What is reality?
The idea that reality may be nothing more than a result of emerging information is not a novel idea at all. Plato, in what is known as the allegory of the cave, exposes how reality is perceived by a group of humans chained in a cave who from birth observe reality through the shadows projected on a wall.

Modern version of the allegory of the cave
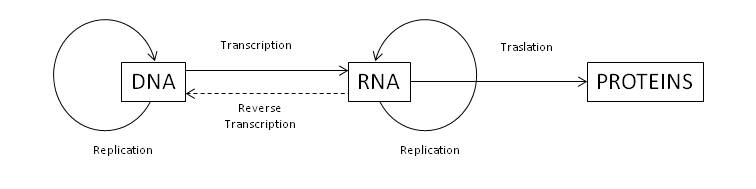
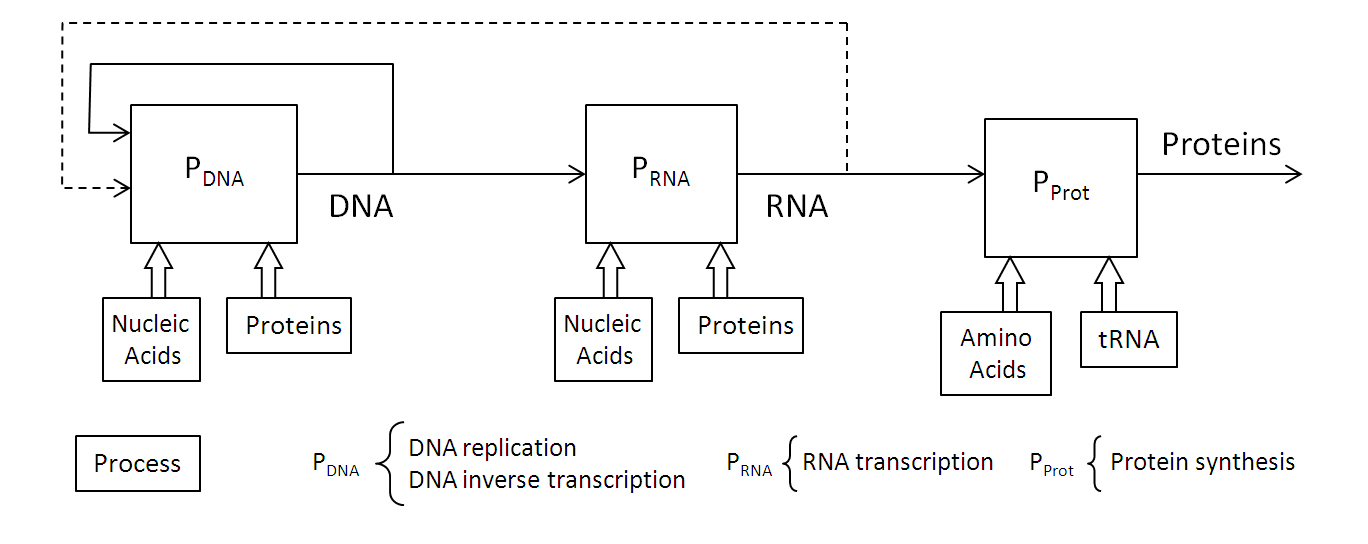
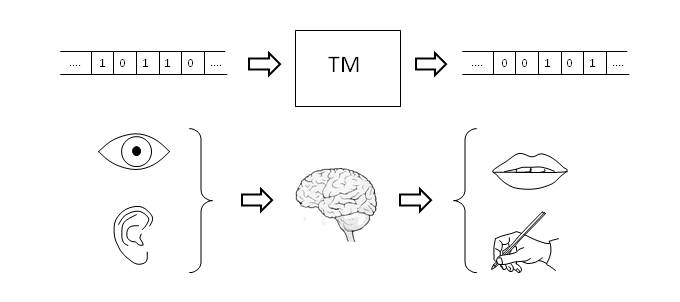
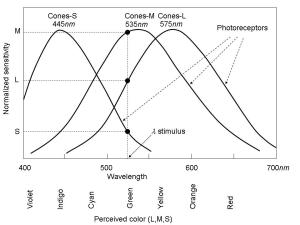
It is interesting to note that when we refer to perception, anthropic vision plays an important role, which can create some confusion by associating perception with human consciousness. To clarify this point, let’s imagine an automaton of artificial vision. In the simplest case, it will be equipped with image sensors, processes for image processing and a database of patterns to be recognized. Therefore, the system is reduced to information encoded as a sequence of bits and to a set of processes, defined axiomatically, that convert information into knowledge.
Therefore, the acquisition of information always takes place by physical processes, which in the case of the automaton are materialized by means of an image sensor based on electronic technology and in the case of living beings by means of molecular photoreceptors. As algorithmic information theory shows us, this information has no meaning until it is processed, extracting patterns contained in it.
As a result, we can draw general conclusions about the process of perception. Thus, the information can be obtained and analyzed with different degrees of detail, giving rise to different layers of reality. This is what makes humans have a limited view of reality and sometimes a distorted one.
But in the case of physics, the scientific procedure aims to solve this problem by rigorously contrasting theory and experimentation. This leads to the definition of physical models such as the theory of electromagnetism or Newton’s theory of universal gravitation that condense the behavior of nature to a certain functional level, hiding a more complex underlying reality, which is why they are irreducible models of reality. Thus, Newton’s theory of gravitation models the gravitational behavior of massive bodies without giving a justification for it.
Today we know that the theory of general relativity gives an explanation to this behavior, through the deformation of space-time by the effect of mass, which in turn determines the movement of massive bodies. However, the model is again a description limited to a certain level of detail, proposing a space-time structure that may be static, expansive or recessive, but without giving justification for it. Neither does it establish a link with the quantum behavior of matter, which is one of the objectives of the unification theories. What we can say is that all these models are a description of reality at a certain functional level.

Universal Gravitation vs. Relativistic Mechanics
Reality as information processing
But the question is: What does this have to do with perception? As we have described, perception is the result of information processing, but this is a term generally reserved for human behavior, which entails a certain degree of subjectivity or virtuality. In short, perception is a mechanism to establish reality as the result of an interpretation process of information. For this reason, we handle concepts such as virtual reality, something that computers have boosted but that is nothing new and that we can experiment through daydreaming or simply by reading a book.
Leaving aside a controversial issue such as the concept of consciousness: What is the difference between the interaction of two atoms, two complex molecules or two individuals? Let’s look at the similarities first. In all these cases, the two entities exchange and process information, in each particular case making a decision to form a molecule, synthesize a new molecule or decide to go to the cinema. The difference is the information exchanged and the functionality of each entity. Can we make any other difference? Our anthropic vision tells us that we humans are superior beings, which makes a fundamental difference. But let’s think of biology: This is nothing more than a complex interaction between molecules, to which we owe our existence!
We could argue that in the case where human intelligence intervenes the situation is different. However, the structure of the three cases is the same, so the information transferred between the entities, which as far as we know have a quantum nature, is processed with a certain functionality. The difference that can be seen is that in the case of human intervention we say that functionality is intelligent. But we must consider that it is very easy to cheat with natural language, as it becomes clear when analyzing its nature.
In short, one could say that reality is the result of emerging information and its subsequent interpretation by means of processes, whose definition is always axiomatic, at least as far as knowledge reaches.
Perhaps, all this is very abstract so a simple example, which we find in advertising techniques, can give us a more intuitive idea. Let’s suppose an image whose pixels are actually images that appear when we zoom in, as shown in the figure.

Perception of a structure in functional layers
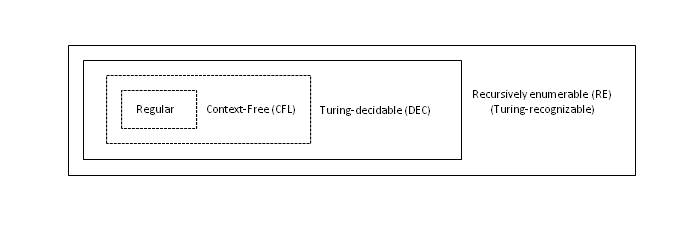
For an observer with a limited visual capacity, only a reality that shows a specific scene of a city will emerge. But for an observer with a much greater visual acuity, or who has an appropriate measuring instrument, he will observe a much more complex reality. This example shows that the process of observation of a mathematical object formed by a sequence of bits can be structured into irreducible functional layers, depending on the processes used to interpret the information. Since everything observable in our Universe seems to follow this pattern, we can ask ourselves the question: Is this functional structure the foundation of our Universe?
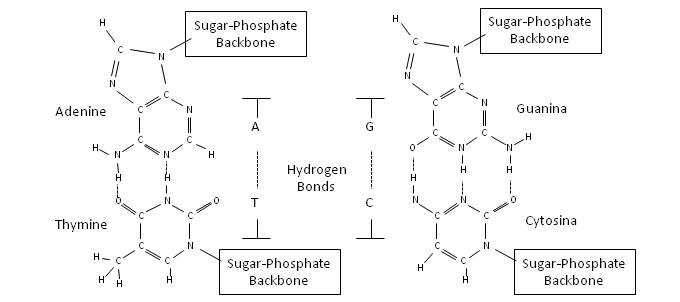
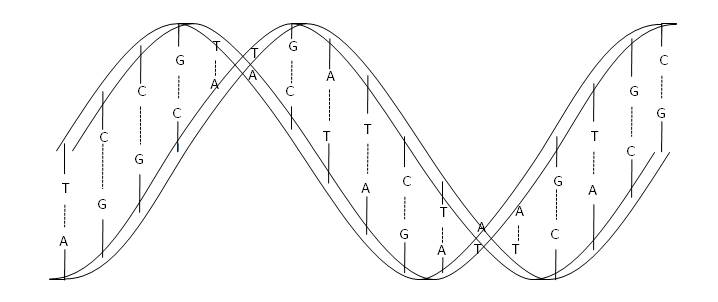
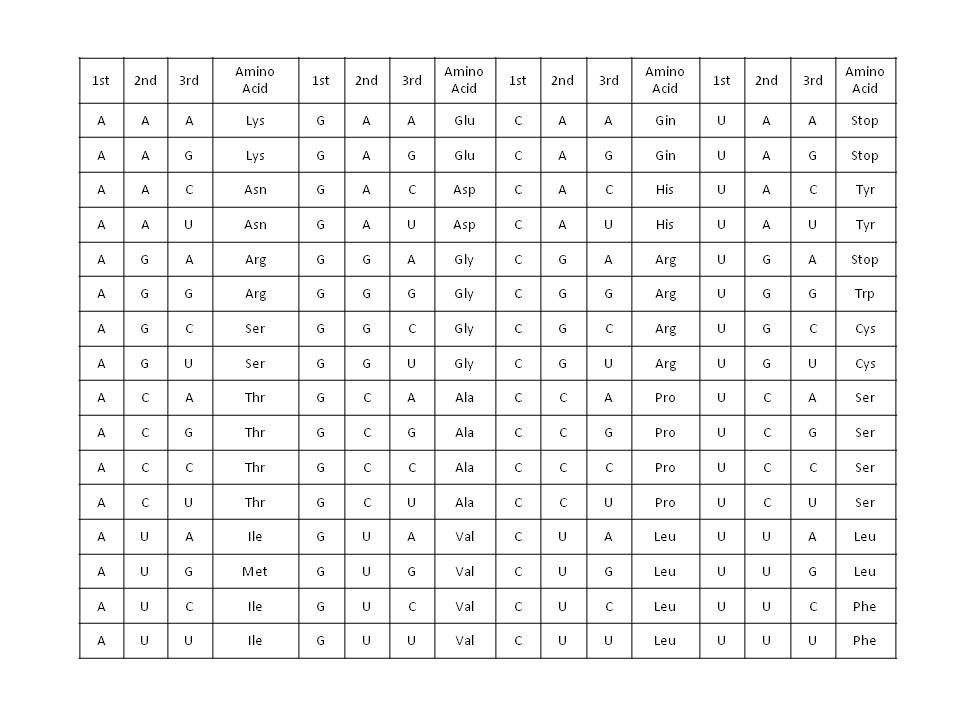
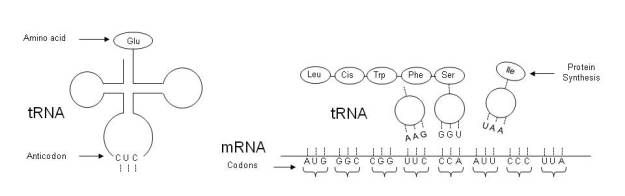

 After years of dealing with information and other subjects such as engineering, physics, and mathematics, I have decided to venture into the analysis of what we mean by reality and its relationship to information. Given the nature of the subject, I hope to stick to reason, trying to avoid any kind of speculation and not let myself be carried away by enthusiasm. Formally said, I hope that the analysis responds to “pure reason” (This is a very cool statement in the Kantian style!).
After years of dealing with information and other subjects such as engineering, physics, and mathematics, I have decided to venture into the analysis of what we mean by reality and its relationship to information. Given the nature of the subject, I hope to stick to reason, trying to avoid any kind of speculation and not let myself be carried away by enthusiasm. Formally said, I hope that the analysis responds to “pure reason” (This is a very cool statement in the Kantian style!).