The ability of mathematics to describe the behavior of nature, particularly in the field of physics, is a surprising fact, especially when one considers that mathematics is an abstract entity created by the human mind and disconnected from physical reality. But if mathematics is an entity created by humans, how is this precise correspondence possible?
Throughout centuries this has been a topic of debate, focusing on two opposing ideas: Is mathematics invented or discovered by humans?
This question has divided the scientific community: philosophers, physicists, logicians, cognitive scientists and linguists, and it can be said that not only is there no consensus, but generally positions are totally opposed. Mario Livio in the essay “Is God a Mathematician? [1] describes in a broad and precise way the historical events on the subject, from Greek philosophers to our days.
The aim of this post is to analyze this dilemma, introducing new analysis tools such as Information Theory (IT) [2], Algorithmic Information Theory (AIT) [3] and Computer Theory (CT) [4], without forgetting the perspective that shows the new knowledge about Artificial Intelligence (AI).
In this post we will make a brief review of the current state of the issue, without entering into its historical development, trying to identify the difficulties that hinder its resolution, for in subsequent posts to analyze the problem from a different perspective to the conventional, using the logical tools that offer us the above theories.
Currents of thought: invented or discovered?
In a very simplified way, it can be said that at present the position that mathematics is discovered by humans is headed by Max Tegmark, who states in “Our Mathematical Universe” [5] that the universe is a purely mathematical entity, which would justify that mathematics describes reality with precision, but that reality itself is a mathematical entity.
On the other extreme, there is a large group of scientists, including cognitive scientists and biologists who, based on the fact of the brain’s capabilities, maintain that mathematics is an entity invented by humans.
Max Tegmark: Our Mathematical Universe
In both cases, there are no arguments that would tip the balance towards one of the hypotheses. Thus, in Max Tegmark’s case he maintains that the definitive theory (Theory of Everything) cannot include concepts such as “subatomic particles”, “vibrating strings”, “space-time deformation” or other man-made constructs. Therefore, the only possible description of the cosmos implies only abstract concepts and relations between them, which for him constitute the operative definition of mathematics.
This reasoning assumes that the cosmos has a nature completely independent of human perception, and its behavior is governed exclusively by such abstract concepts. This view of the cosmos seems to be correct insofar as it eliminates any anthropic view of the universe, in which humans are only a part of it. However, it does not justify that physical laws and abstract mathematical concepts are the same entity.
In the case of those who maintain that mathematics is an entity invented by humans, the arguments do not usually have a formal structure and it could be said that in many cases they correspond more to a personal position and sentiment. An exception is the position maintained by biologists and cognitive scientists, in which the arguments are based on the creative capacity of the human brain and which would justify that mathematics is an entity created by humans.
For these, mathematics does not really differ from natural language, so mathematics would be no more than another language. Thus, the conception of mathematics would be nothing more than the idealization and abstraction of elements of the physical world. However, this approach presents several difficulties to be able to conclude that mathematics is an entity invented by humans.
On the one hand, it does not provide formal criteria for its demonstration. But it also presupposes that the ability to learn is an attribute exclusive to humans. This is a crucial point, which will be addressed in later posts. In addition, natural language is used as a central concept, without taking into account that any interaction, no matter what its nature, is carried out through language, as shown by the TC [4], which is a theory of language.
Consequently, it can be concluded that neither current of thought presents conclusive arguments about what the nature of mathematics is. For this reason, it seems necessary to analyze from new points of view what is the cause for this, since physical reality and mathematics seem intimately linked.
Mathematics as a discovered entity
In the case that considers mathematics the very essence of the cosmos, and therefore that mathematics is an entity discovered by humans, the argument is the equivalence of mathematical models with physical behavior. But for this argument to be conclusive, the Theory of Everything should be developed, in which the physical entities would be strictly of a mathematical nature. This means that reality would be supported by a set of axioms and the information describing the model, the state and the dynamics of the system.
This means a dematerialization of physics, something that somehow seems to be happening as the development of the deeper structures of physics proceeds. Thus, the particles of the standard model are nothing more than abstract entities with observable properties. This could be the key, and there is a hint in Landauer’s principle [6], which establishes an equivalence between information and energy.
But solving the problem by physical means or, to be more precise, by contrasting mathematical models with reality presents a fundamental difficulty. In general, mathematical models describe the functionality of a certain context or layer of reality, and all of them have a common characteristic, in such a way that these models are irreducible and disconnected from the underlying layers. Therefore, the deepest functional layer should be unraveled, which from the point of view of AIT and TC is a non-computable problem.
Mathematics as an invented entity
The current of opinion in favor of mathematics being an entity invented by humans is based on natural language and on the brain’s ability to learn, imagine and create.
But this argument has two fundamental weaknesses. On the one hand, it does not provide formal arguments to conclusively demonstrate the hypothesis that mathematics is an invented entity. On the other hand, it attributes properties to the human brain that are a general characteristic of the cosmos.
The Hippocampus: A paradigmatic example of the dilemma discovered or invented
To clarify this last point, let us take as an example the invention of whole numbers by humans, which is usually used to support this view. Let us now imagine an animal interacting with the environment. Therefore, it has to interpret spacetime accurately as a basic means of survival. Obviously, the animal must have learned or invented the space-time map, something much more complex than natural numbers.
Moreover, nature has provided or invented the hippocampus [7], a neuronal structure specialized in acquiring long-term information that forms a complex convolution, forming a recurrent neuronal network, very suitable for the treatment of the space-time map and for the resolution of trajectories. And of course this structure is physical and encoded in the genome of higher animals. The question is: Is this structure discovered or invented by nature?
Regarding the use of language as an argument, it should be noted that language is the means of interaction in nature at all functional levels. Thus, biology is a language, the interaction between particles is formally a language, although this point requires a deeper analysis for its justification. In particular, natural language is in fact a non-formal language, so it is not an axiomatic language, which makes it inconsistent.
Finally, in relation to the learning capability attributed to the brain, this is a fundamental characteristic of nature, as demonstrated by mathematical models of learning and evidenced in an incipient manner by AI.
Another way of approaching the question about the nature of mathematics is through Wigner’s enigma [8], in which he asks about the inexplicable effectiveness of mathematics. But this topic and the topics opened before will be dealt with and expanded in later posts.
References
[1]
M. Livio, Is God a Mathematician?, New York: Simon & Schuster Paperbacks, 2009.
[2]
C. E. Shannon, «A Mathematical Theory of Communication,» The Bell System Technical Journal, vol. 27, pp. 379-423, 1948.
[3]
P. Günwald and P. Vitányi, “Shannon Information and Kolmogorov Complexity,” arXiv:cs/0410002v1 [cs:IT], 2008.
[4]
M. Sipser, Introduction to the Theory of Computation, Course Technology, 2012.
[5]
M. Tegmark, Our Mathematical Universe: My Quest For The Ultimate Nature Of Reality, Knopf Doubleday Publishing Group, 2014.
[6]
R. Landauer, «Irreversibility and Heat Generation in Computing Process,» IBM J. Res. Dev., vol. 5, pp. 183-191, 1961.
[7]
S. Jacobson y E. M. Marcus, Neuroanatomy for the Neuroscientist, Springer, 2008.
[8]
E. P. Wigner, «The unreasonable effectiveness of mathematics in the natural sciences.,» Communications on Pure and Applied Mathematics, vol. 13, nº 1, pp. 1-14, 1960.
Zoonosis, or the jump from an animal virus to humans, has the characteristics of a contingent event. In principle, this leap can be limited by sanitary control of domestic animal species and by regulation of trade, contact and consumption of wild species. However, given the complexity of modern society and the close contact between humans at a global level, the probability of a virus jump to humans is not an avoidable event, so zoonosis can be considered a contingent phenomenon.
This situation has been clearly shown in recent times with the appearance of MERS (MERS-Cov), SARS (SARS-Cov) and recently the COVID-19 (SARS-Cov-2). This propagation is fundamentally motivated by globalization, although the factors are multiple and complex, such as health controls and the structure of livestock farms. But the list is long, and we can also mention the expansion of other viral diseases due to climate change, such as Zika, Chikungunya or Dengue.
The question that arises in this scenario is: What factors influence the magnitude and speed of the spread of a pandemic? Thus, in the cases mentioned above, a very significant difference in the behavior and spread of infection can be seen. Except in the case of COVID-19, the spread has been limited and outbreaks have been localized and isolated, avoiding a global spread.
In contrast, the situation has been completely different with CoVID-19. Thus, its rapid expansion has caught societies unfamiliar with this type of problem unawares, so that health systems have been overwhelmed and without appropriate protocols for the treatment of the infection. On the other hand, authorities unaware of the magnitude of the problem, and ignorant of the minimum precautions to prevent the spread of the virus, seem to have made a series of chained errors, typical of catastrophic processes, such as economic bankruptcies and air accidents.
The long-term impact is still very difficult to assess, as it has triggered a vicious circle of events affecting fundamental activities of modern society.
In particular, the impact on health services will leave a deep imprint, with extension to areas that in principle are not directly related to the COVID-19, such as the psychological and psychiatric effects derived from the perception of danger and social confinement. But even more important is the detraction of resources in other health activities, having reduced the flow of daily health activity, so it is foreseeable a future increase in morbidity and mortality rates of other diseases, especially cancer.
To all this must be added the deterioration of economic activity, with reductions in GDP of up to two figures, which will trigger an increase in poverty, especially in the most disadvantaged segments of the population. And since the economic factor is the transmission belt of human activity, it is easy to imagine a perfect storm scenario.
Pandemic Influencing Factors COVID-19
But let’s return to the question that has been raised, about the singularity of SARS-Cov-2, so that its expansion has been unstoppable and that we are now facing a second wave.
To unravel this question we can analyze what the mathematical models of expansion of an infection show us, starting with the classic SIR model. This type of model allows us to determine the rates of infection (β) and recovery (γ), as well as the basic reproduction rate (R0=β/γ) from the observed morbidity.
The origin of the SIR models (Susceptible, Infectious, and Recovered) goes back to the beginning of the 20th century, proposed by Kermack and McKendrick in 1927. The advantage of these models is that they are based on a system of differential equations, which can be solved analytically and therefore suitable for resolution at the time they were proposed.
However, these types of models are basic and do not facilitate considerations of geographical distribution, mobility, probability of infection, clinical status, temporal development of each of the phases of the infection, age, sex, social distance, protection, tracking and testing strategies. On the other hand, the classic SIR model has a deductive structure, exclusively. This means that from the morbidity data it is possible to determine the basic reproduction rate exclusively, hiding fundamental parameters in the pandemic process, as will be justified below.
To contrast this idea, it is necessary to propose new approaches to the simulation of the pandemic process, as is the case of the study proposed in “A model of the spread of Covid-19” and in its implementation. In this case, the model is a discrete SIR structure, in which individuals go through an infection and recovery process with realistic states, in addition to including all the parameters for defining the scenario mentioned above, that is, probability of infection, geographical distribution of the population, mobility, etc. This allows an accurate simulation of the pandemic and, despite its complexity, its structure is very suitable for implementation with existing computational means.
The first conclusion drawn from the simulations of the initial phase of the pandemic was the need to consider the existence of a very significant asymptomatic population. Thus, in the classical model it is possible to obtain a rapid expansion of the pandemic simply by considering high values of the infection rate (β).
On the contrary, in the discrete model the application of existing data did not justify the observed data, unless there was a very significant asymptomatic population that hid the true magnitude of the spread of the infection. The symptomatic population in the early stages of the pandemic should be considered to be small. This, together with the data on spread through different geographical areas and the possible probability of infection, produced temporary results of much slower expansion that did not even trigger the priming of the model.
In summary, the result of the simulations led to totally inconsistent scenarios, until a high population of asymptomatic people was included, from which the model began to behave according to the observed data. At present, there are already more precise statistics that confirm this behavior that, in the group of infected people, get to establish that 80% are asymptomatic, 15% are symptomatic that require some type of medical attention by means of treatment or hospital admission and, the rest, 5% that require from basic level life support to advanced life support.
These figures help explain the virulence of a pandemic, which is strongly regulated by the percentage of asymptomatic individuals. This behavior justifies the enormous difference between the behaviors of different types of viruses. Thus, if a virus has a high morbidity it is easy to track and isolate, since the infectious cases do not remain hidden. On the contrary, a virus with low morbidity keeps hidden the individuals who are vectors of the disease, since they belong to the group of asymptomatic people. Unlike the viruses mentioned above, COVID-19 is a paradigmatic example of this scenario, with the added bonus that it is a virus that has demonstrated a great capacity for contagion.
This behavior has meant that when the pandemic has shown its face there was already a huge group of individual vectors. And this has probably been the origin of a chain of events with serious health, economic and social consequences.
The mechanisms of expansion and containment of the pandemic
In retrospect, the apparent low incidence in the first few weeks suggested that the risk of a pandemic was low and not very virulent. Obviously, an observation clearly distorted by the concealment of the problem caused by the asymptomatic nature of the majority of those infected.
This possibly also conditioned the response to their containment. The inadequate management of the threat by governments and institutions, the lack of protection resources and the message transmitted to the population ended up materializing the pandemic.
In this context, there is one aspect that calls for deep attention. A disease with a high infectious capacity requires a very effective means of transmission and since the first symptoms were of pulmonary type it should have been concluded that the airway was the main means of transmission. However, much emphasis was placed on direct physical contact and social distance. The minimization of the effect of aerosols, which are very active in closed spaces, as is now being recognized, is remarkable.
Another seemingly insignificant nuance related to the behavior of the pandemic under protective measures should also be noted. This is related to the modeling of the pandemic. The classical SIR model assumes that the infection rate (β) and recovery rate (γ) are uniquely proportional to the sizes of the populations in the different States. However, this is an approach that masks the underlying statistical process, and in the case of the recovery is also a conceptual flaw. This assumption determines the structure of the differential equations of the model, imposing a general solution of exponential type that is not necessarily the real one.
By the way, the exponential functions introduce a phase delay, which produces the effect that the recovery of an individual occurs in pieces, for example, first the head and then the legs!
But the reality is that the process of infection is a totally stochastic process that is a function of the probability of contagion determined by the capacity of the virus, the susceptibility of the individual, the interaction between infected and susceptible individuals, the geographical distribution, mobility, etc. In short, this process has a Gaussian nature.
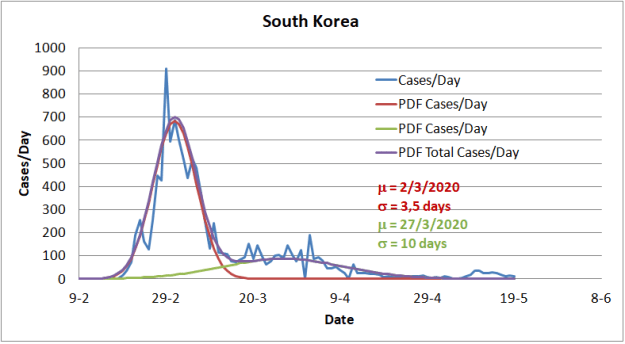
As will later be justified, this Gaussian process is masked by the overlap of infection in different geographical areas, so they are only visible in separate local outbreaks, as a result of effective containment. An example of this can be found in the case of South Korea, represented in the figure below.
In the case of recovery, the process corresponds to a stochastic delay line and therefore Gaussian, since it only depends on the temporary parameters of recovery imposed by the virus, the response of the individual and the healing treatments. Therefore, the recovery process is totally independent for each individual.
The result is that the general solution of the discrete SIR model is Gaussian and therefore responds to a quadratic exponential function, unlike the order one exponential functions of the classical SIR model. This makes the protection measures much more effective than those exposed by the conventional models.So they must be considered a fundamental element to determine the strategy for the containment of the pandemic.
The point is that once a pandemic is evident, containment and confinement measures must be put in place. It is at this point that COVID-19 poses a challenge of great complexity, as a result of the large proportion of asymptomatic individuals, who are the main contributors to the spread of infection.
A radical solution to the problem requires strict confinement of the entire population for a period no less than the latency period of the virus in an infected person. To be effective, this measure must be accompanied by protective measures in the family or close environment, as well as extensive screening campaigns. This strategy has shown its effectiveness in some Asian countries.
In reality, early prophylaxis and containment is the only measure to effectively contain the pandemic, as the model output for different dates of containment shows. Interestingly, the dispersion of the curves in the model’s priming areas is a consequence of the stochastic nature of the model.
But the late implementation of this measure, when the number of people infected in hiding was already very high, together with the lack of a culture of prophylaxis against pandemics in Western countries has meant that these measures have been ineffective and very damaging.
In this regard, it should be noted that the position of the governments has been lukewarm and in most cases totally erratic, which has contributed to the fact that the confinement measures have been followed very laxly by the population.
Here it is important to note that in the absence of effective action, governments have based their distraction strategy on the availability of a vaccine, which is clearly not a short-term solution.
As a consequence of the ineffectiveness of the measure, the period of confinement has been excessively prolonged, with restrictions being lifted once morbidity and mortality statistics were lowered. The result is that, since the virus is widespread in the population, new waves of infection have inevitably occurred.
This is another important aspect in interpreting the pandemic’s spread figures. According to the classic SIR model, everything seems to indicate that in the progression of the figures, a peak of infections should be expected, which should decrease exponentially. Throughout the first months, those responsible for the control of the pandemic have been looking for this peak, as well as the flattening of the integration curve of the total cases. Something expected but never seemed to come.
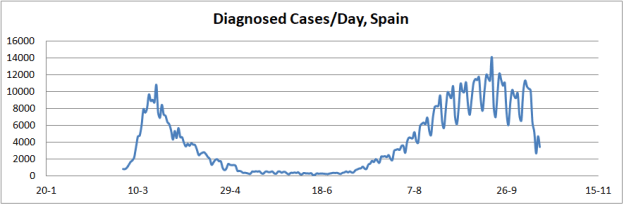
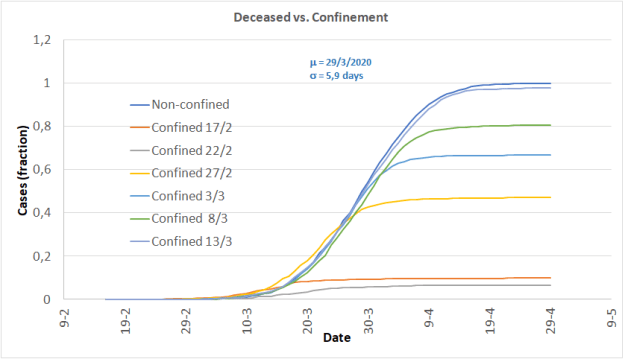
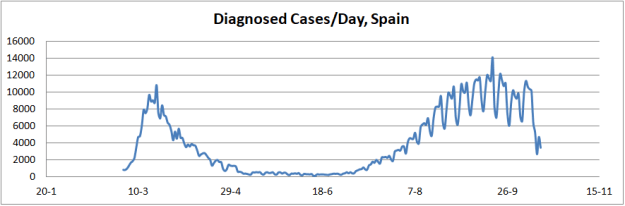
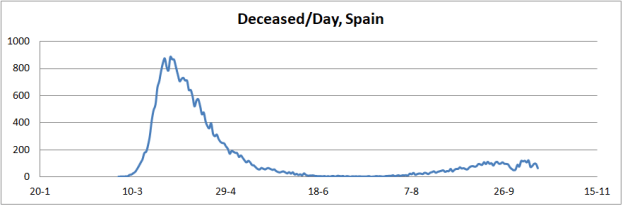
The explanation for this phenomenon is quite simple. The spread of the pandemic is not subject to infection of a closed group of individuals, as the classical SIR model assumes. Rather, the spread of the virus is a function of geographic areas with specific population density and the mobility of individuals between them. The result is that the curves that describe the pandemic are a complex superposition of the results of this whole conglomerate, as shown by the curve of deaths in Spain, on the dates indicated.
The result is that the process can be spread out over time, so that the dynamics of the curves are a complex overlap of outbreaks that evolve according to multiple factors, such as population density and mobility, protective measures, etc.
This indicates that the concepts of pandemic spread need to be thoroughly reviewed. This should not be surprising if we consider that throughout history there have been no reliable data that have allowed contrasting their behavior.
Evolution of morbidity and mortality
Another interesting aspect is the study of the evolution of morbidity and mortality of SARS-Cov-2. For this purpose, case records can be used, especially now that data from a second wave of infection are beginning to be available, as shown in the figure below.
In view of these data a premature conclusion could be drawn, assuring that the virus is affecting the population with greater virulence, increasing morbidity, but on the other hand it could also be said that mortality is decreasing dramatically.
But nothing could be further from reality if we consider the procedure for obtaining data on diagnosed cases. Thus, it can be seen that the magnitude of the curve of diagnosed cases in the second phase is greater than in the first phase, indicating greater morbidity. However, in the first phase the diagnosis was mainly of a symptomatic type, given the lack of resources for testing. On the contrary, in the second phase the diagnosis was made in a symptomatic way and by means of tests, PCR and serology.
This has only brought to light the magnitude of the group of asymptomatic infected, which were hidden in the first phase. Therefore, we cannot speak of a greater morbidity. On the contrary, if we look at the slope of evolution of the curve, it is smoother, indicating that the probability of infection is being much lower than that shown in the month of March. This is a clear indication that the protective measures are effective. And they would be even more so if the discipline were greater and the messages would converge on this measure, instead of creating confusion and uncertainty.
If the slopes of the case curves are compared, it is clear that the expansion of the pandemic in the first phase was very abrupt, as a result of the existence of a multitude of asymptomatic vectors and the absolute lack of prevention measures. In the second phase, the slope is gentler, attributable to the prevention measures. The comparison of these slopes is by a factor of approximately 4.
However, it is possible that without prevention measures the second phase could be much more aggressive. This is true considering that it is very possible that the number of vectors of infection at present is much higher than in the first phase, since the pandemic is much more widespread. Therefore the spread factor could have been much higher in the second phase, as a consequence of this parameter.
In terms of mortality, the ratio deceased/diagnosed seems to have dropped dramatically, which would lead to say that the lethality of the virus has dropped. Thus at the peak of the first phase its value was approximately 0.1, while in the second phase it has a value of approximately 0.01, that is, an order of magnitude lower.
But considering that in the figures of diagnosed in the first phase the asymptomatic were hidden, both ratios are not comparable. Obviously, the term corresponding to the asymptomatic would allow us to explain this apparent decrease, although we must also consider that the real mortality has decreased as a result of improved treatment protocols.
Consequently, it is not possible to draw consequences on the evolution of the lethality of the virus, but what is certain is that the magnitudes of mortality are decreasing for two reasons. One is virtual one, such as the availability of more reliable figures of infected people, and the other is real, as a result of improved treatment protocols.
Strategies for the future
At present, it seems clear that the spread of the virus is a consolidated fact, so the only possible strategy in the short and medium term is to limit its impact. In the long term, the availability of a vaccine could finally eradicate the disease, although the possibility of the disease becoming endemic or recurrent will also have to be considered.
For this reason, and considering the implications of the pandemic on human activity of all kinds, future plans must be based on a strategy of optimization, so as to minimize the impact on the general health of the population and on the economy. This is because increased poverty may have a greater impact than the pandemic itself.
Under this point of view and considering the aspects analyzed above, the strategy should be based on the following points:
Strict protection and prophylaxis measures: masks, cleaning, ventilation, social distance in all areas.
Protection of the segments of the population at risk.
Maintain as much as possible the economic and daily activities.
Social awareness: Voluntary declaration and isolation in case of infection. Compliance with regulations without the need for coercive measures.
Implementing an organizational structure for mass testing, tracking and isolation of infected.
It is important to note that, as experience is demonstrating, aggressive containment measures are not adequate to prevent successive waves of infection and are generally highly ineffective, producing distrust and rejection, which is a brake on fighting the pandemic.
Another interesting aspect is that the implementation of the previous points does not correspond to strictly health-related projects, but rather to resource management and control projects. For this reason, the activities aimed at fighting the pandemic must be ad hoc projects, since the pandemic is an eventual event, to which specific efforts must be devoted.
Directing the effort through organizations such as the health system itself will only result in a destructuring of the organization and a dispersion of resources, a task for which it has not been created nor does it have the profile to do so.
In view of the expansion of the Covid-19 in different countries, and taking as a reference the model of spreading exposed in the previous post, it is possible to make an interpretation of the data, in order to solve some doubts and contradictions raised in different forums.
But before starting this analysis, it is important to highlight an outstanding feature of the Covid-19 expansion shown by the model. In general, the modeling of infectious processes usually focuses on the infection rate of individuals, leaving temporal aspects such as incubation or latency periods of the pathogens in the background. This is justified as a consequence of the fact that their influence is generally unnoticed, besides introducing difficulties in the analytical study of the models.
However, in the case of Covid-19 its rapid expansion makes the effect of time parameters evident, putting health systems in critical situations and making it difficult to interpret the data that emerge as the pandemic spreads.
In this sense, the outstanding characteristics of the Covid-19 are:
The high capacity of infection.
The capacity of infection of individuals in the incubation phase.
The capacity of infection of asymptomatic individuals.
This makes the number of possible asymptomatic cases very high, presenting a great difficulty in diagnosis, as a result of the lack of resources caused by the novelty and rapid spread of the virus.
For this reason, the model has been developed taking into account the temporal parameters of the spread of the infection, which requires a numerical model, since the analytical solution is very complex and possibly without a purely analytical solution.
As a result, the model has a distinctive feature compared to conventional models, which is shown in the figure below.
This consists in that it is necessary to distinguish groups of asymptomatic and symptomatic individuals, since they present a temporal evolution delayed in time. As a consequence, the same happens with the curves of hospitalized and ICU individuals.
This allows clarifying some aspects linked to the real evolution of the virus. For example, in relation to the declaration of the exceptional measures in Italy and Spain, a substantial improvement in the contention of the pandemic was expected, something that still seems distant. The reason for this behavior is that the contention measures have been taken on the basis of the evolution of the curve of symptomatic individuals, ignoring the fact that there was already a very important population of asymptomatic individuals.
As can be seen in the graphs, the measurements should have been taken at least three weeks in advance, that is, according to the evolution curve of asymptomatic individuals. But in order to make this decision correctly, this data should have been available, something that was completely impossible, as a result of the lack of a test campaign on the population.
This situation is supported by the example of China, which although the spread of the virus could not be contained at an early stage, containment measures were taken several weeks earlier, on a comparative time scale.
The data from Germany are also very significant, exhibiting a much lower mortality rate than Italy and Spain. Although this raises a question about the capacity of infection in this country, it is actually easy to explain. In Italy and Spain, testing for Covid-19 infection is beginning. However, in Germany these tests have been carried out for several weeks at a rate of several hundred thousand per week. In contrast, the numbers of individuals diagnosed in Italy and Spain should be reviewed in the future.
This explains the lower mortality rate for a large number of infected individuals. This also has a decisive advantage, since early diagnosis allows for the isolation of infected individuals, reducing the possibility of infection of other individuals, which ultimately will result in a lower mortality rate.
Therefore, a quick conclusion can be made that can be summarized in the following points:
Measures to isolate the population are necessary but ineffective when taken at an advanced stage of the pandemic.
Early detection of infection is a totally decisive aspect in the contention of the pandemic and above all in the reduction of the mortality rate.
The reason for addressing this issue is twofold. On the one hand, Covid-19 is the most important challenge for humanity at the moment, but on the other hand the process of expansion of the virus is an example of how nature establishes models based on information processing.
The analysis of the dynamics of the virus expansion and its consequences will be based on a model implemented in Python, which for those who are interested can be downloaded, being able to make the changes that are considered appropriate to analyze different scenarios.
The model
The model is based on a structure of 14 states and 20 parameters, which determine the probabilities and the temporal dynamics of transitions between states. It is important to note that in the model the only vectors for virus spread are the “symptomatic” and “asymptomatic” states. The model also establishes parameters for the mobility of individuals and the rate of infection.
Some simplifications have been made to the model. Thus, it assumes that the geographical distribution of the population is homogeneous, which has contributed to a significant reduction in computational effort. In principle, this may seem to be a major limitation, but we will see that it is not an obstacle to drawing overall conclusions. The following figure represents in a simplified way the state diagram of the model. The conditions that establish the transitions can be consulted in the model.
The parameters have been adjusted according to experience gained from the progression of the virus, so information is limited and should be subject to further review. In any case, it seems clear that the virus has a high efficiency in infiltrating the cells to perform the copying process, so the viral load required for the infection seems to be small. This presupposes a high rate of infection, so it is also assumed that a significant part of the population will be infected.
Scenarios for the spread of the virus can be listed in the following sections:
Early action measures to confine the spread of the virus
Uncontrolled spread of the virus.
Exceptional measures to limit the propagation of virus.
The first scenario is not going to be analyzed as this is not the case in the current situation. This scenario can be analyzed by modifying the parameters of the model.
Therefore, the scenarios of interest are those of uncontrolled propagation and exceptional measures, as these represent the current state of the pandemic.
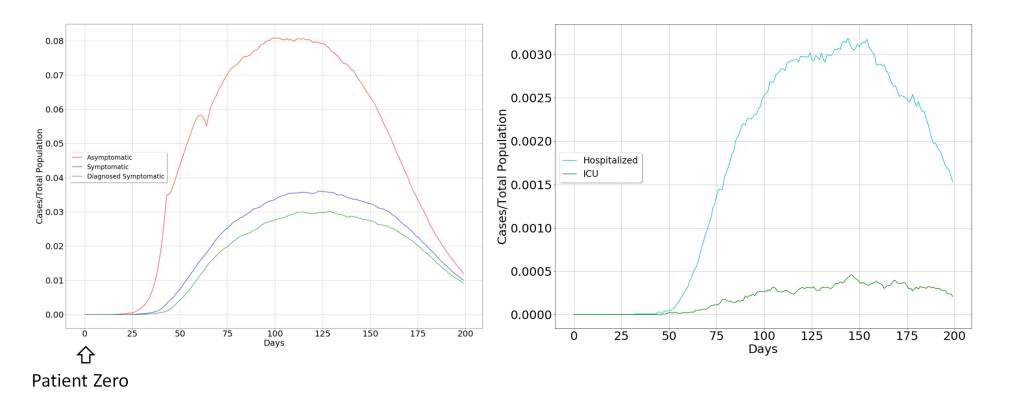
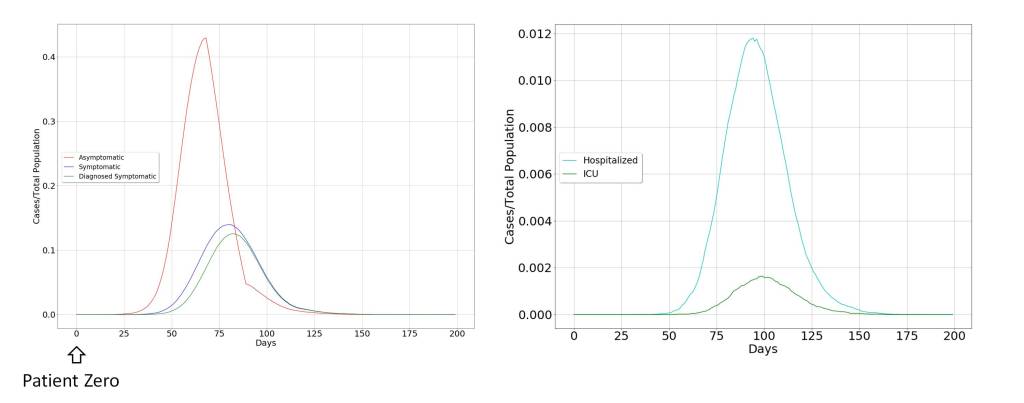
The natural evolution
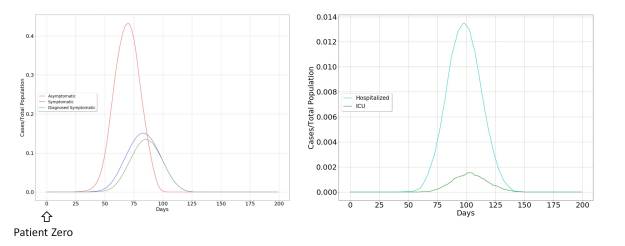
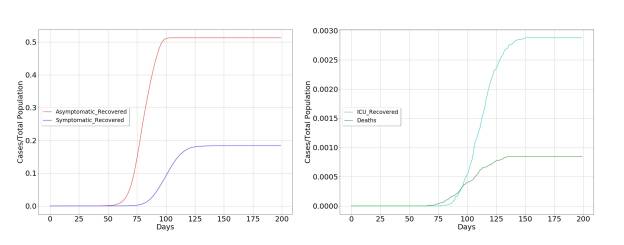
The model dynamics for the case of uncontrolled propagation are shown in the figure below. It can be seen that the most important vectors in the propagation of the virus are asymptomatic individuals, for three fundamental reasons. The first is the broad impact of the virus on the population. The second is determined by the fact that it only produces a symptomatic picture in a limited fraction of the population. The third is directly related to the practical limitations in diagnosing asymptomatic individuals, as a consequence of the novelty and rapid spread of Covid-19.
For this reason, it seems clear that the extraordinary measures to contain the virus must be aimed at drastically limiting contact between humans. This is what has surely advised the possible suspension of academic activities, which includes the child and youth population, not because they are a risk group but because they are the most active population in the spread of the virus.
The other characteristic of the spreading dynamics is the abrupt temporary growth of those affected by the virus, until it reaches the whole population, initiating a rapid recovery, but condemning the groups at risk to be admitted to the Intensive Care Unit (ICU) and probably to death.
This will pose an acute problem in health systems, and an increase in collateral cases can be expected, which could easily surpass the direct cases produced by Covid-19. This makes it advisable to take extraordinary measures, but at the same time, the effectiveness of these measures is in doubt, since their rapid expansion may reduce the effectiveness of these measures, leading to late decision-making.
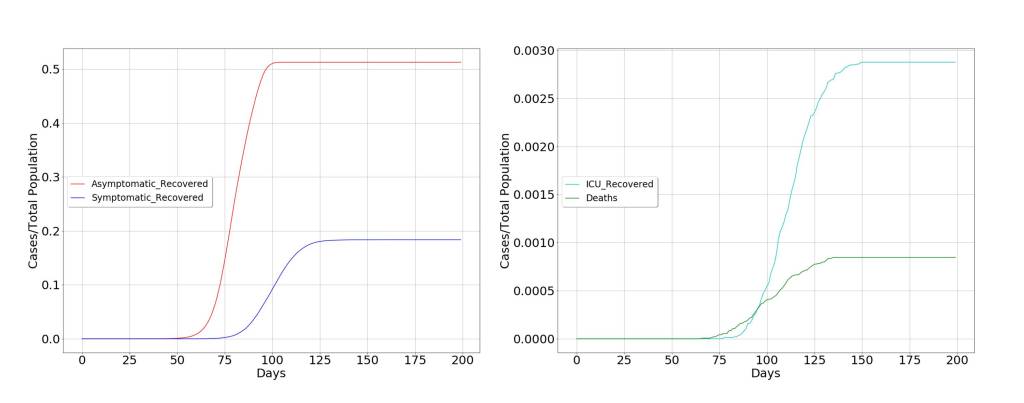
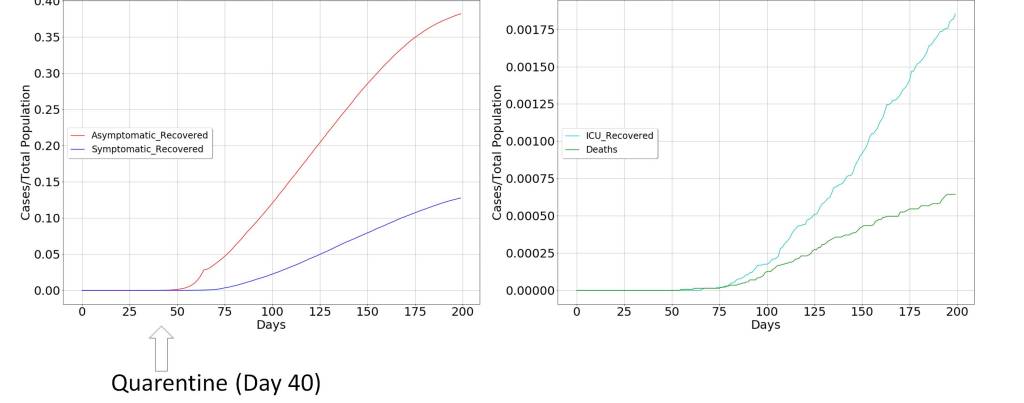
Present situation
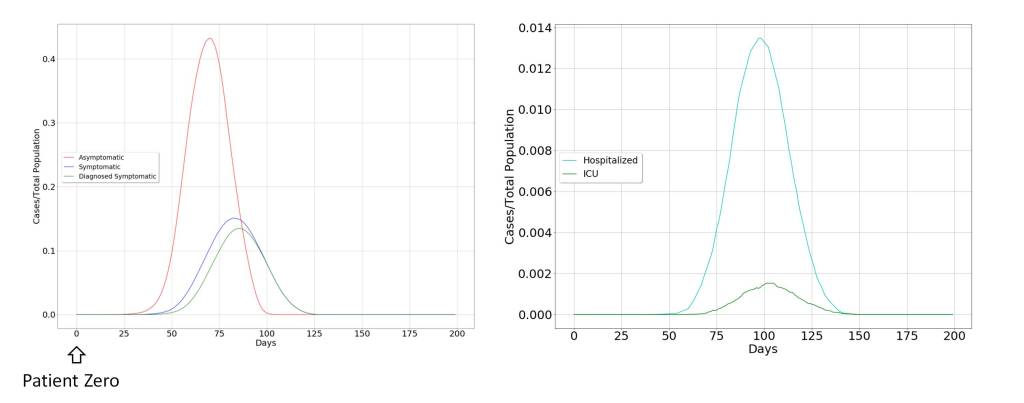
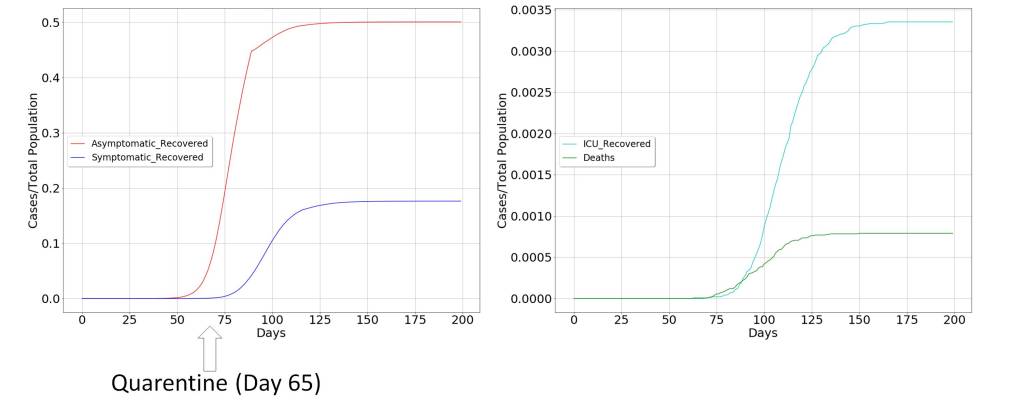
This scenario is depicted in the following figures where quarantine is decreed for a large part of the population, restricting the movement of the propagation vectors. To confirm the above, two scenarios have been modeled. The first, in which the decision of extraordinary measures has been taken before the curve of diagnosed symptoms begins to grow, which in the figure occurs around day 40 from patient zero. The second in whom the decision has been taken a few days later, when the curve of diagnosed symptoms is clearly increasing, around day 65 from patient zero.
These two scenarios clearly indicate that it is more than possible that measures have been taken late and that the pandemic is following its natural course, due to the delay between the infected and symptomatic patient curves. Consequently, it seems that the containment measures will not be as effective as expected, and considering that economic factors will possibly have very profound consequences in the long and medium term for the well-being of society, alternative solutions should be considered.
It is interesting to note how the declaration of special measures modifies the temporal behavior of the pandemic. But once these have not been taken at an early stage of the virus’ emergence, the consequences are profound.
What can be expected
Obviously, the most appropriate solution would be to find remedies to cure the disease, which is being actively worked on, but which has a developmental period that may exceed those established by the dynamics of the pandemic.
However, since the groups at risk, the impact and the magnitude of these are known, a possible alternative solution would be:
Quarantine these groups, keeping them totally isolated from the virus and implementing care services to make this isolation effective until the pandemic subsides, or effective treatment is found.
Implement hospitals dedicated exclusively to the treatment of Covid-19.
For the rest of the population not included in the risk groups, continue with normal activity, allowing the pandemic to spread (something that already seems to be an inevitable possibility). However, strict prophylactic and safety measures must be taken.
This strategy has undeniable advantages. Firstly, it would reduce the pressure on the health system, preventing the collapse of normal system activity and leading to a faster recovery. Secondly, it would reduce the problems of treasury and cash management of states, which can lead to an unprecedented crisis, the consequences of which will certainly be more serious than the pandemic itself.
Finally, an important aspect of the model remains to be analyzed, such as its limitation for modeling a non-homogeneous distribution of the population. This section is easy to solve if we consider that it works correctly for cities. Thus, in order to model the case of a wider geographical extension, one only has to model the particular cases of each city or community with a time lag as the extension of the pandemic itself is showing.
One aspect, namely the duration of the extraordinary measures, remains to be determined. If it is considered that the viral load to infect an individual is small, it is possible that the remnants at the end of the quarantine period may reactivate the disease, in those individuals who have not yet been exposed to the virus or who have not been immunized. This is especially important considering that cured people may continue to be infected for another 15 days.
From the analysis carried out in the previous post, it can be concluded that, in general, it is not possible to identify the macroscopic states of a complex system with its quantum states. Thus, the macroscopic states corresponding to the dead cat (DC) or to the living cat (AC) cannot be considered quantum states, since according to quantum theory the system could be expressed as a superposition of these states. Consequently, as it has been justified, for macroscopic systems it is not possible to define quantum states such as |DC⟩ and |DC⟩. On the other hand, the states (DC) and (AC) are an observable reality, indicating that the system presents two realities, a quantum reality and an emerging reality that can be defined as classical reality.
Quantum reality will be defined by its wave function, formed by the superposition of the quantum subsystems that make up the system and which will evolve according to the existing interaction between all the quantum elements that make up the system and the environment. For simplicity, if the CAT system is considered isolated from the environment, the succession of its quantum state can be expressed as:
Expression in which it has been taken into account
that the number of non-entangled quantum subsystems k also varies with time, so
it is a function of the sequence n, considering time as a discrete
variable.
The observable classical reality can be described by the state of the system that, if for the object “cat” is defined as (CAT[n]), from the previous reasoning it is concluded that (CAT[n]) ≢ |CAT[n]⟩. In other words, the quantum and classical states of a complex object are not equivalent.
The question that remains to be justified is the irreducibility of the observable classical state (CAT) from the underlying quantum reality, represented by the quantum state |CAT⟩. This can be done if it is considered that the functional relationship between states |CAT⟩ and (CAT) is extraordinarily complex, being subject to the mathematical concepts on which complex systems are based, such as they are:
The complexity of the space of quantum states (Hilbert space).
The random behavior of observable information emerging from quantum reality.
The enormous number of quantum entities involved in a macroscopic system.
The non-linearity of the laws of classical physics.
Based on Kolmogorov complexity [1], it is possible to prove that the behavior of systems with these characteristics does not support, in most cases, an analytical solution that determines the evolution of the system from its initial state. This also implies that, in practice, the process of evolution of a complex object can only be represented by itself, both on a quantum and a classical level.
According to the algorithmic information theory [1], this process is equivalent to a mathematical object composed of an ordered set of bits processed according to axiomatic rules. In such a way that the information of the object is defined by the Kolmogorov complexity, in a manner that it remains constant throughout time, as long as the process is an isolated system. It should be pointed out that the Kolmogorov complexity makes it possible to determine the information contained in an object, without previously having an alphabet for the determination of its entropy, as is the case in the information theory [2], although both concepts coincide at the limit.
From this point of view, two fundamental questions
arise. The first is the evolution of the entropy of the system and the second
is the apparent loss of information in the observation process, through which
classical reality emerges from quantum reality. This opens a possible line of
analysis that will be addressed later.
But going back to the analysis of what is the relationship between classic and quantum states, it is possible to have an intuitive view of how the state (CAT) ends up being disconnected from the state |CAT⟩, analyzing the system qualitatively.
First, it should be noted that virtually 100% of the quantum information contained in the state |CAT⟩ remains hidden within the elementary particles that make up the system. This is a consequence of the fact that the physical-chemical structure [3] of the molecules is determined exclusively by the electrons that support its covalent bonds. Next, it must be considered that the molecular interaction, on which molecular biology is based, is performed by van der Waals forces and hydrogen bonds, creating a new level of functional disconnection with the underlying layer.
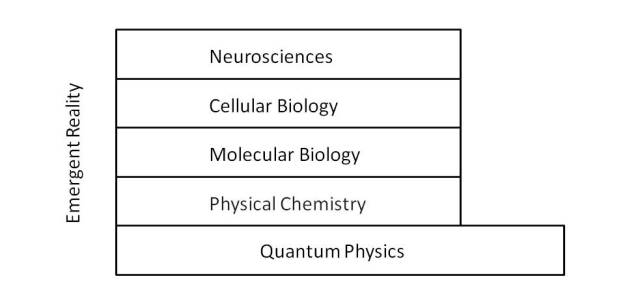
Supported by this functional level appears a new functional structure formed by cellular biology [4], from which appear living organisms, from unicellular beings to complex beings formed by multicellular organs. It is in this layer that the concept of living being emerges, establishing a new border between the strictly physical and the concept of perception. At this level the nervous tissue [5] emerges, allowing the complex interaction between individuals and on which new structures and concepts are sustained, such as consciousness, culture, social organization, which are not only reserved to human beings, although it is in the latter where the functionality is more complex.
But to the complexity of the functional layers must be
added the non-linearity of the laws to which they are subject and which are necessary and sufficient conditions for a behavior of deterministic chaos [6] and which, as previously justified, is based on the algorithmic information theory [1]. This means that any variation in the initial conditions will produce a different dynamic, so that any emulation will end up diverging from the original, this behavior being the justification of free will. In this sense, Heisenberg’s uncertainty principle [7] prevents from knowing exactly the initial conditions of the classical system, in any of the functional layers described above. Consequently, all of them will have an irreducible nature and an unpredictable dynamic, determined exclusively by the system itself.
At this point and in view of this complex functional structure, we must ask what the state (CAT) refers to, since in this context the existence of a classical state has been implicitly assumed. The complex functional structure of the object “cat” allows a description at different levels. Thus, the cat object can be described in different ways:
As atoms and molecules subject to the laws of physical chemistry.
As molecules that interact according to molecular biology.
As complex sets of molecules that give rise to cell biology.
As sets of cells to form organs and living organisms.
As structures of information processing, that give rise to the mechanisms of perception and interaction with the environment that allow the development of individual and social behavior.
As a result, each of these functional layers can be expressed by means of a certain state. So to speak of, the definition of a unique macroscopic state (CAT) is not correct. Each of these states will describe the object according to different functional rules, so it is worth asking what relationship exists between these descriptions and what their complexity is. Analogous to the arguments used to demonstrate that the states |CAT⟩ and (CAT) are not equivalent and are uncorrelated with each other, the states that describe the “cat” object at different functional levels will not be equivalent and may to some extent be disconnected from each other.
This behavior is a proof of how reality is structured in irreducible functional layers, in such a way that each one of the layers can be modeled independently and irreducibly, by means of an ordered set of bits processed according to axiomatic rules.
Refereces
[1]
P. Günwald and P. Vitányi, “Shannon Information and Kolmogorov Complexity,” arXiv:cs/0410002v1 [cs:IT], 2008.
[2]
C. E. Shannon, «A Mathematical Theory of Communication,» The Bell System Technical Journal, vol. 27, pp. 379-423, 1948.
[3]
P. Atkins and J. de Paula, Physical Chemestry, Oxford University Press, 2006.
[4]
A. Bray, J. Hopkin, R. Lewis and W. Roberts, Essential Cell Biology, Garlan Science, 2014.
[5]
D. Purves and G. J. Augustine, Neuroscience, Oxford Univesisty press, 2018.
[6]
J. Gleick, Chaos: Making a New Science, Penguin Books, 1988.
[7]
W. Heisenberg, «The Actual Content of Quantum Theoretical Kinematics and Mechanics,» Zeit-schrift fur Physik. Translation: NASA TM-77379., vol. 43, nº 3-4, pp. 172-198, 1927.
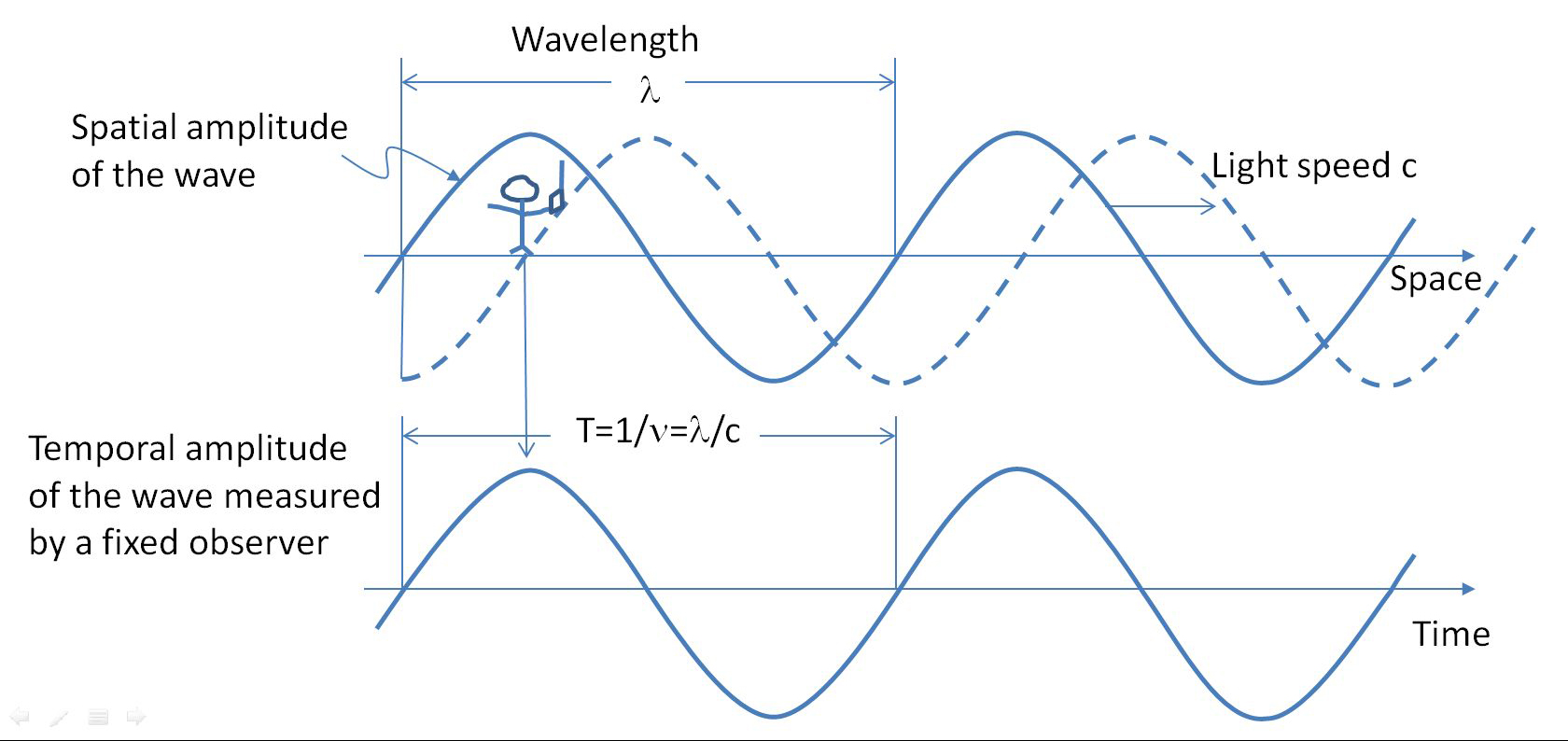
Visible light, heat, radio waves and other types of radiation all have the same physical nature and are constituted by a flow of particles called photons. The photon or “light quantum” was proposed by Einstein, for which he was awarded the Nobel Prize in 1921 and is one of the elementary particles of the standard model, belonging to the boson family. The fundamental characteristic of a photon is its capacity to transfer energy in quantized form, which is determined by its frequency, according to the expression E=h∙ν, where h is the Planck constant and ν the frequency of the photon.
Electromagnetic spectrum
Thus, we can find photons of very low frequencies located in the band of radio waves, to photons of very high energy called gamma rays, as shown in the following figure, forming a continuous frequency range that constitutes the electromagnetic spectrum. Since the photon can be modeled as a sinusoid traveling at the speed of light c, the length of a complete cycle is called the photon wavelength λ, so the photon can be characterized either by its frequency or its wavelength, since λ=c/ν. But it is common to use the term color as a synonym for frequency, since the color of light perceived by humans is a function of frequency. However, as we are going to see, this is not strictly physical but a consequence of the process of measuring and interpreting information, which makes color an emerging reality of another underlying reality, sustained by the physical reality of electromagnetic radiation.
Structure of an electromagnetic wave
But before addressing this issue, it should be considered that to detect photons efficiently it is necessary to have a detector called an antenna, whose size must be similar to the wavelength of the photons.
Color perception by humans
The human eye is sensitive to wavelengths ranging from deep red (700nm, nanometers=10-9 meters) to violet (400nm). This requires receiving antennas of the order of hundreds of nanometres in size! But for nature this is not a big problem, as complex molecules can easily be this size. In fact, the human eye, for color vision, is endowed with three types of photoreceptor proteins, which produce a response as shown in the following figure.
Response of photoreceptor cells of the human retina
Each of these types configures a type of photoreceptor cell in the retina, which due to its morphology are called cones. The photoreceptor proteins are located in the cell membrane, so that when they absorb a photon they change shape, opening up channels in the cell membrane that generate a flow of ions. After a complex biochemical process, a flow of nerve impulses is produced that is preprocessed by several layers of neurons in the retina that finally reach the visual cortex through the optic nerve, where the information is finally processed.
But in this context, the point is that the retinal cells do not measure the wavelength of the photons of the stimulus. On the contrary, what they do is convert a stimulus of a certain wavelength into three parameters called L, M, S, which are the response of each of the types of photoreceptor cells to the stimulus. This has very interesting implications that need to be analyzed. In this way, we can explain aspects such as:
The reason why the rainbow has 7 colors.
The possibility of synthesizing the color by means of additive and subtractive mixing.
The existence of non-physical colors, such as white and magenta.
The existence of different ways of interpreting color according to the species.
To understand this, let us imagine that they provide us with the response of a measurement system that relates L, M, S to the wavelength and ask us to establish a correlation between them. The first thing we can see is that there are 7 different zones in the wavelength, 3 ridges and 4 valleys. 7 patterns! This explains why we perceive the rainbow composed of 7 colors, an emerging reality as a result of information processing that transcends physical reality.
But what answer will a bird give us if we ask it about the number of colors of the rainbow? Possibly, though unlikely, it will tell us nine! This is because the birds have a fourth type of photoreceptor positioned in the ultraviolet, so the perception system will establish 9 regions in the light perception band. And this leads us to ask: What will be the chromatic range perceived by our hypothetical bird, or by species that only have a single type of photoreceptor? The result is a simple case of combinatorial!
On the other hand, the existence of three types of photoreceptors in the human retina makes it possible to synthesize the chromatic range in a relatively precise way, by means of the additive combination of three colors, red, green and blue, as it is done in the video screens. In this way, it is possible to produce an L,M,S response at each point of the retina similar to that produced by a real stimulus, by means of the weighted application of a mixture of photons of red, green and blue wavelengths.
Similarly, it is possible to synthesize color by subtractive or pigmentary mixing of three colors, magenta, cyan and yellow, as in oil paint or printers. And this is where the virtuality of color is clearly shown, since there are no magenta photons, since this stimulus is a mixture of blue and red photons. The same happens with the white color, as there are no individual photons that produce this stimulus, since white is the perception of a mixture of photons distributed in the visible band, and in particular by the mixture of red, green and blue photons.
In short, the perception of color is a clear example of how reality emerges as a result of information processing. Thus, we can see how a given interpretation of the physical information of the visible electromagnetic spectrum produces an emerging reality, based a much more complex underlying reality.
In this sense, we could ask ourselves what an android with a precise wavelength measurement system would think of the images we synthesize in painting or on video screens. It would surely answer that they do not correspond to the original images, something that for us is practically imperceptible. And this connects with a subject, which may seem unrelated, as is the concept of beauty and aesthetics. The truth is that when we are not able to establish patterns or categories in the information we perceive it as noise or disorder. Something unpleasant or unsightly!
The replication mechanisms of living beings can be compared with the self-replication of automatons in the context of computability theory. In particular, DNA replication, analyzed from the perspective of the recursion theorem, indicates that its replication structure goes beyond biology and the quantum mechanisms that support it, as it is analyzed in the article Biology as an Axiomatic Process.
Physical chemistry establishes the principles by which atoms interact with each other to form molecules. In the inorganic world the resulting molecules are relatively simple, not allowing establishing a complex functional structure. On the other hand, in the organic world, molecules can be made up of thousands or even millions of atoms and have complex functionality. It highlights what is known as molecular recognition, through which the molecules interact with each other selectively and which is the basis of biology.
Molecular recognition plays a fundamental role in the structure of DNA, in the translation of the genetic code of DNA into proteins and in the biochemical interaction of proteins, which ultimately form the basis on which living beings are based.
The detailed study of these molecular interactions makes it possible to describe the functionality of the processes, in such a way that it is possible to establish formal models, to such an extent that they can be used as a computing technology, as is the case of DNA-based computing.
From this perspective, this allows us to ask if the process of information is something deeper and if in reality it is the foundation of biology itself, according to what is established by the principle of reality.
For this purpose, this section aims to analyze the basic processes on which biology is based, in order to establish a link with axiomatic processing and thus investigate the nature of biological processes. For this, it is not necessary to describe in detail the biological mechanisms described in the literature. We will simply describe its functionality, so that they can be identified with the theoretical foundations of information processing. To this end, we will explain the mechanisms on which DNA replication and protein synthesis are based.
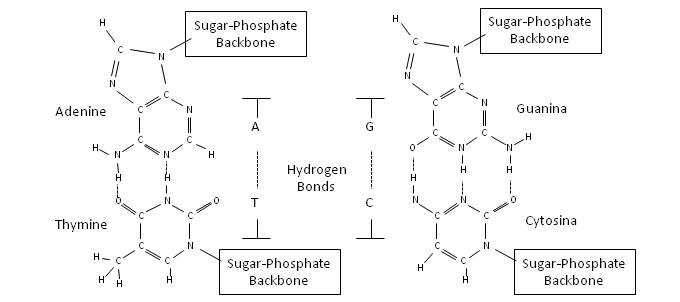
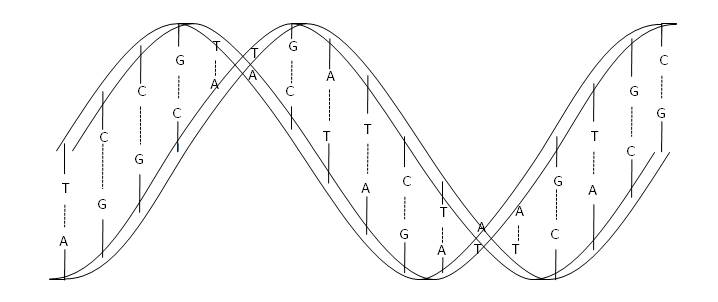
DNA and RNA molecules are polymers formed from the ribose and deoxyribose nucleotides, respectively, bound by phosphates. On the basis of this nucleotide chain, one of the four possible nucleic acids can be linked. There are five different nucleic acids, adenine (A), guanine (G), cytosine (C), thymine (T) and uracil (U). In the case of DNA, nucleic acids that can be coupled by covalent bonds to nucleotides are A, G, C and T, whereas in the case of RNA they are A, G, C and U. As a consequence, molecules are structured in a helix shape, fitting the nucleic acids in a precise and compact way, due to the shape of their electronic clouds.
The helix structure allows the nucleic acids of two different strands to be bound together by hydrogen bonds, forming pairs A-T and G-C in the case of DNA, and A-U and G-C in the case of RNA, as shown in the following figure.
Base-pairing of nucleic acids in DNA
As a result, the DNA molecule is formed by a double helix, in which two chains of nucleotides polymers wind one on top of the other, remaining together by means of hydrogen bonds of nucleic acids. Thus, each strand of the DNA molecule contains the same genetic code, one of which can be considered the negative of the other.
Double helix structure of DNA molecule
The genetic information of an organism, called a genome, is not contained in a single DNA molecule, but is organized into chromosomes. These are made up of DNA strands bound together by proteins. Thus, in the case of humans, the genome is formed by 46 chromosomes, and so, the number of bases in the DNA molecules that compose it being about 3×109. Since each base can be encoded by means of 2 bits, the human genome, considered as an object of information, is equivalent to 6×109 bits.
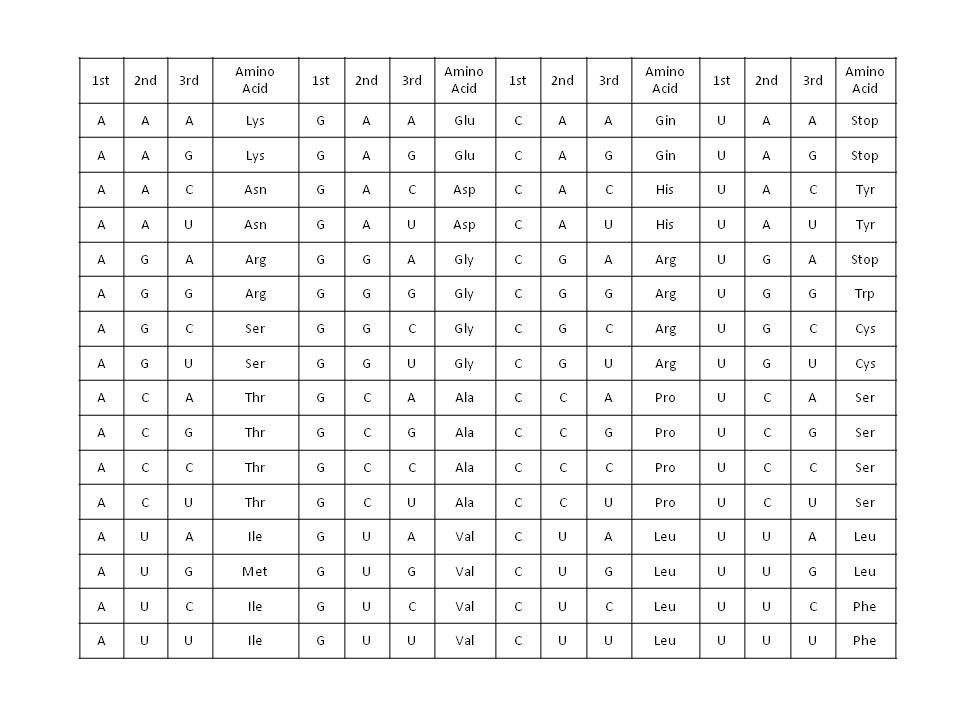
The information contained in the genes is the basis for the synthesis of proteins, which are responsible for executing and controlling the biochemistry of living beings. The proteins are formed by the bonding of amino acids, through covalent bonds, which is done from the sequences of the bases contained in the DNA. The number of existing amino acids is 20 and since each base codes 2 bits, 3 bases (6 bits, 64 combinations) are necessary to be able to code each one of the amino acids. This means that there is some redundancy in the assignment of base sequences to amino acids, in addition to control codes for the synthesis process (Stop), as shown in the following table.
Translation of nucleic acids (Codons) to amino acids
However, protein synthesis is not done directly from DNA, since it requires the intermediation of RNA. This is called the translation process and involves two types of different RNA molecules, the messenger ARM (mRNA) and the transfer RNA (tRNA). The first step is the synthesis of mRNA from DNA. This process is called transcription, in such a way that the information corresponding to a gene is copied into the mRNA molecule, which is done through a process of recognition between the molecules of the nucleic acids, carried out by the hydrogen bonds, such as shows the following figure.
DNA transcription
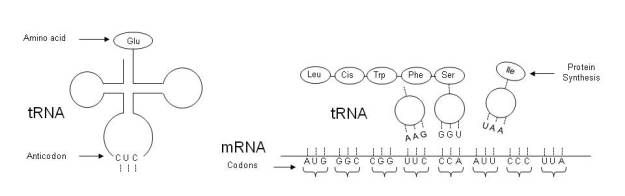
Once the mRNA molecule is synthesized, the tRNA molecule is responsible for mediating between mRNA and amino acids to synthesize proteins, for which it has two specific molecular mechanisms. On the one hand, tRNA has a chain of three amino acids called anticodon at one end. On the opposite side, tRNA binds to a specific amino acid, according to the translation table of nucleic acid sequences into amino acids. In this way, tRNA is able to translate mRNA into a protein, as shown in the figure below.
Protein synthesis (mRNA translation)
But perhaps the most complex process is undoubtedly DNA replication, so that each molecule produces two identical replicas. Replication is performed by unwinding each strand of the molecule and inserting the nucleic acid molecules on each of the strands, in a similar way to that shown in the mRNA synthesis. DNA replication is controlled by enzymatic processes supported by proteins. Without going into detail and in order to show its complexity, the table below shows the proteins involved in the replication process and their role.
The role of proteins in the DNA replication process
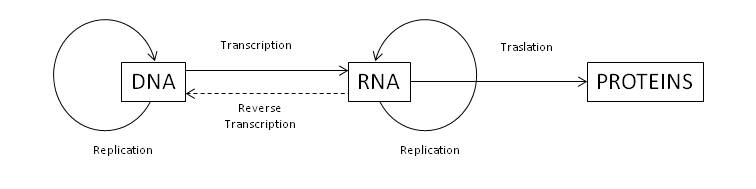
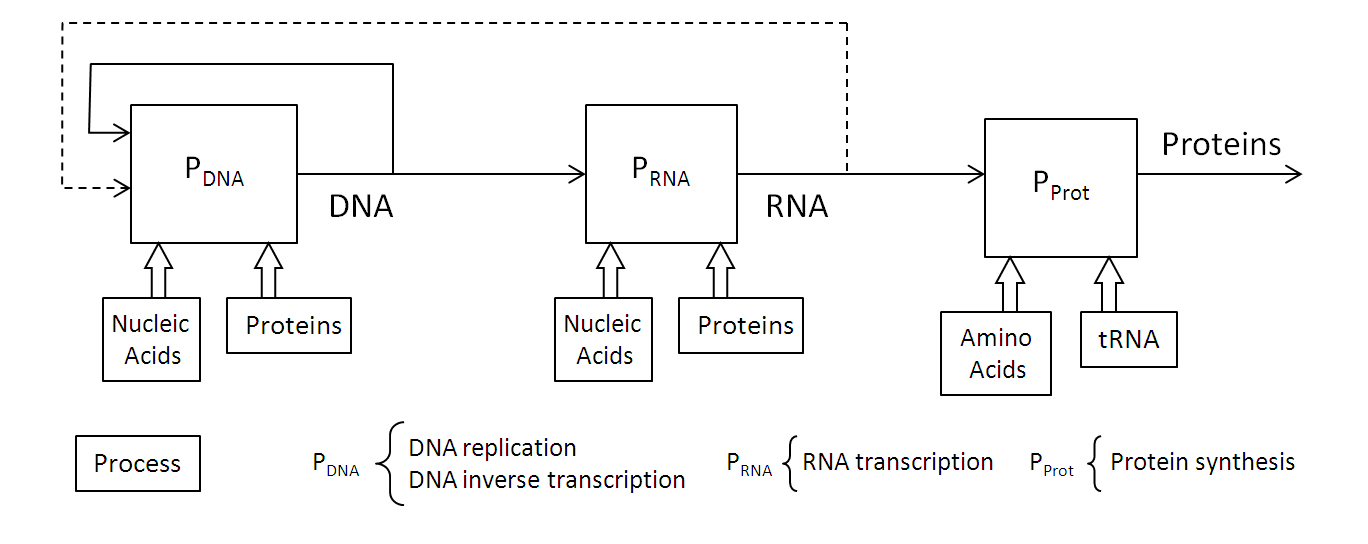
The processes described above are defined as the central dogma of molecular biology and are usually schematically represented schematically as shown in the following figure. It also depicts the reverse transcription that occurs in retroviruses, which synthesizes a DNA molecule from RNA.
Central dogma of molecular biology
The biological process from the perspective of computability theory
Molecular processes supported by DNA, RNA and proteins can be considered from an abstract point of view as information processes. As a result, input statements corresponding to a language are processed resulting in new output statements. Thus, the following languages can be identified:
DNA molecule. Sentence consisting of a sequence of characters corresponding to a 4-symbol alphabet.
RNA molecule – protein synthesis. Sentence consisting of a sequence of characters belonging to a 21-symbol alphabet.
RNA molecule-reverse transcription. Sentence composed of a sequence of characters belonging to a 4-symbol alphabet.
Protein molecule. Sentence composed of a sequence of characters belonging to a 20-symbol alphabet.
This information is processed by the machinery established by the physicochemical properties of control molecules. To better understand this functional structure, it is advisable to modify the scheme corresponding to the central dogma of biology. To do this, we must represent the processes involved and the information that flows between them, as shown in the following block diagram.
Functional structure of DNA replication
This structure highlights the flow of information between processes, such as DNA and RNA sentences, where the functional blocks of information processing are the following:
PDNA. Replication process. The functionality of this process is determined by the proteins involved in DNA synthesis, producing two replicas of DNA from a single molecule.
PRNA. Transcription process. It synthesizes a RNA molecule from a gene encoded in DNA.
PProt. Translation process. It synthesizes a protein from an RNA molecule.
This structure clearly shows how information emerges from biological processes, something that seems to be ubiquitous in all natural models and allows the implementation of computer systems. In all cases this capacity is finally supported by quantum physics. In the case of biology in particular, this is produced from the physicochemical properties of molecules, which are determined by quantum physics. Therefore, the information process is something that emerges from an underlying reality and ultimately from quantum physics. This is true as far as knowledge goes.
This means that, although there is a strong link between reality and information, information is simply an emerging product of reality. But biology provides a clue to the intimate relationship between reality and information, which are ultimately indistinguishable concepts. If we look at the DNA replication process, we see that DNA is produced in several stages of processing:
DNA → RNA → Proteins → DNA.
We could consider this to be a specific feature of the biological process. However, computability theory indicates that the replication process is subject to deeper logical rules than the physical processes themselves that support replication. In computability theory, the recursion theorem determines that replication of information requires at least the intervention of two independent processes.
This shows that DNA replication is subject to abstract rules that must be satisfied not only by biology, but by every natural process. Therefore, the physical foundations that support biological processes must verify this requirement. Consequently, this shows that the information processing is essential in what we understand by reality.