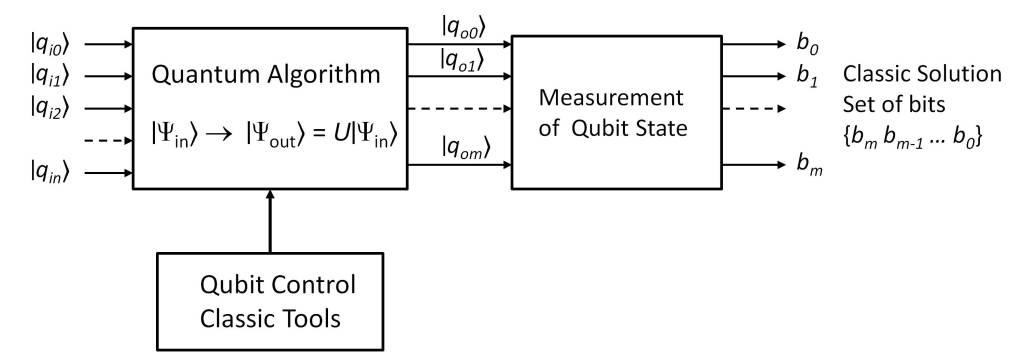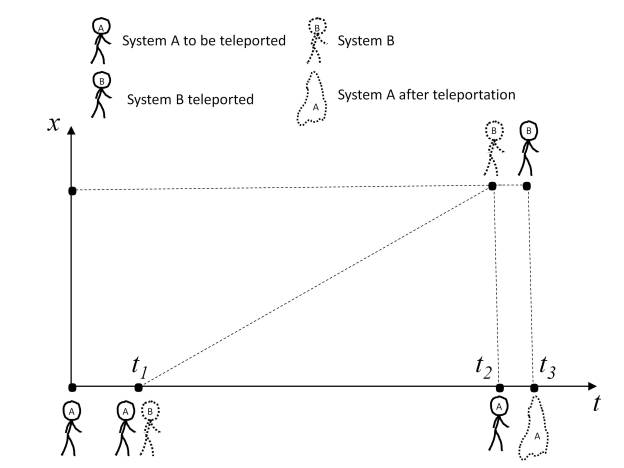
When we talk about teleportation, we quickly remember science fiction stories in which both people and artifacts are teleported over great distances instantaneously, overcoming the limitations of relativistic physical laws.
Considering that the theoretical possibility of teleporting quantum information was proposed in the scientific field, Bennett et al [1] (1993), and that it was later experimentally demonstrated to be possible, Bouwmeester et al (1997) [2] and Boschi et al (1998) [3], we can ask the question what is true in this assumption.
For this reason, the aim of this post is to expose the basics of quantum teleportation, analyze its possible practical applications and clarify what is true in the scenarios proposed by science fiction.
Fundamentals of quantum teleportation
Before delving into the fundamentals, it should be clarified that quantum teleportation consists of converting the quantum state of a system into an exact replica of the unknown quantum state of another system with which it is quantum entangled. Therefore, teleportation in no way means the transfer of matter or energy. And as we will see below, teleportation also does not imply the violation of the non-cloning theorem [4] [5].
Thus, the model proposed by Bennet et al [1] is the one shown in the figure below, which is constituted by a set of quantum logic gates that process the states of the three qubits, named A, B and Ancillary. The A qubit corresponds to the system whose state is to be teleported, while the B qubit is the system on which the quantum state of system A is transferred. The ancillary qubit is a qubit necessary to perform the transfer.
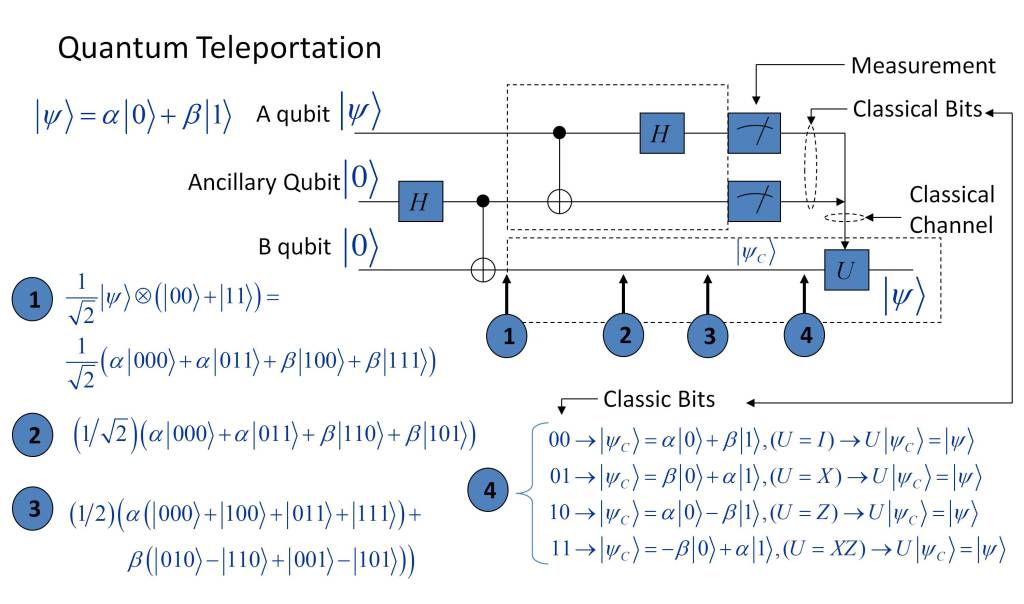
Once the three qubits are processed by the logic gates located up to the point indicated by ③ they are quantum entangled [6] [7] [8] [9], in such a way that when a measurement is performed on qubit A and ancillary qubit ④ its state collapses into one of the possible states (|00〉,|01〉,|10〉,|11〉).
From this information, qubit B is processed by a quantum gate U, whose functionality depends on the state obtained from the measurement performed on qubits A and ancillary, according to the following criterion, where I, X, Z are Pauli gates.
- |00〉 → U = I.
- |01〉 → U = X.
- |10〉 → U = Z.
- |11〉 → U = XZ.
As a consequence, the state of qubit B corresponds to the original state of qubit A, which in turn is modified as a consequence of the measurement process. This means that once the measurement of qubit A and the ancillary qubit is performed, their state collapses, verifying the non-cloning theorem [4] [5] which establishes the impossibility of creating copies of a quantum state.
From a practical point of view, once the three qubits are entangled, qubit B can be moved to another spatial position, which is constrained by the laws of general relativity, so the velocity of qubit B cannot exceed the speed of light. On the other hand, the measurement result of the A ancillary qubits must be transferred to the location of qubit B by means of a classical information channel, so the information transfer speed cannot exceed the speed of light. The result is that teleportation makes it possible to transfer the state of a quantum particle to another remotely located quantum particle, but this transfer is bound by the laws of general relativity, so it cannot exceed the speed of light.

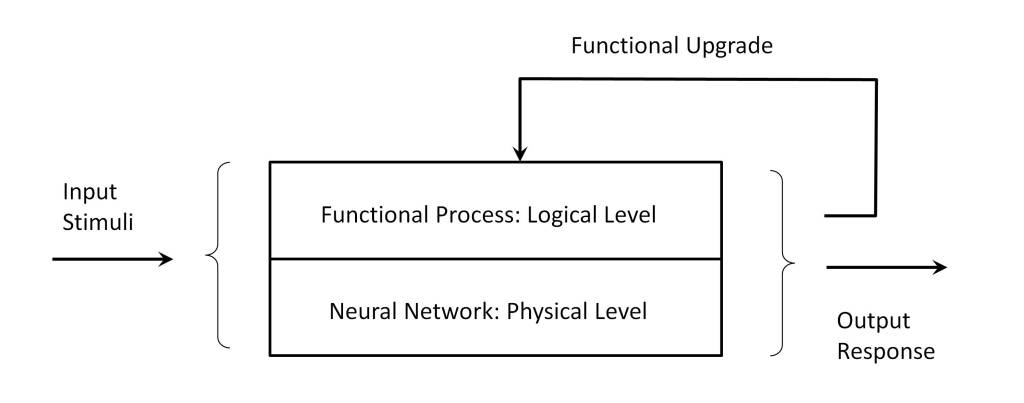
It is very important to note that in reality the only thing that is transferred between qubit A and qubit B is the information describing the wave function, since what physically constitutes the particles that support the qubit are not teleported. This raises a fundamental question concerning the meaning of teleportation at the level of classical reality, which we will analyze in the context of complex systems consisting of multiple qubits.
But a fundamental aspect in determining the nature of information is the fact that teleportation is based on the transfer of information, which is another indication that information is the support of reality, as we concluded in the post “Reality as an Information Process“.
Quantum teleportation of macroscopic objects
Analogous to the teleportation scenario proposed by Bennett et al [1], it is possible to teleport the quantum state of a complex system consisting of N quantum particles. As shown in the figure below, teleportation from system A to system B requires the use of N ancillary qubits.
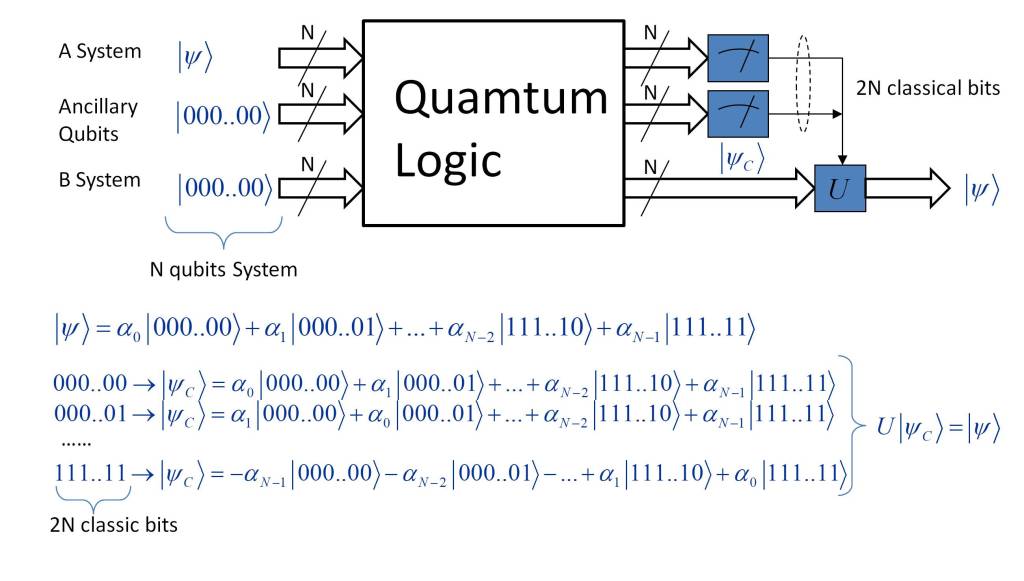
This is because the number of combinations of the coefficients aI of the wave function |ψC〉 and their signs is of the order of 22N. Thus, when the measurement of the qubits of system A and the auxiliary qubits is performed, 2N classical bits are obtained, which encode 22N configurations of the unitary transform U. Thus, the coefficients of the wave function |ψC〉 can be rearranged, transforming the wave function of system B into |ψ〉.
Consequently, from the theoretical point of view, the teleportation of complex quantum systems consisting of a large number of particles is possible. However, its practical realization faces the difficulty of maintaining the quantum entanglement of all particles, as a consequence of quantum decoherence [10]. This causes the quantum particles to no longer be entangled as a consequence of the interaction with the environment, which causes the transferred quantum information to contain errors.
Since decoherence effect grows exponentially with the number of particles forming the quantum system, it is evident that the teleportation of N-particle systems is in practice a huge challenge, since the system is composed of 3N particles. The difficulty is even greater if it is considered that in the preparation of the teleportation scenario systems A, B and ancillary qubits will be in the same location. But subsequently system B will have to move to another space-time location in order for the teleportation to make any practical sense. This makes system B under physical conditions that make decoherence much more likely and produce a higher error rate in the transferred quantum state, with respect to the original quantum state of system A.
But suppose that these limitations are overcome in such a way that it is possible in practice to teleport macroscopic objects, even objects of a biological nature. The question arises: what properties of the teleported object are transferred to the receiving object?
In principle, it can be assumed that the properties of the receiving object have the same properties as the original object from the point of view of classical reality, since after the teleportation is completed the receiving object has the same wave function as the teleported object.
In the case of inanimate objects it can be assumed that the classical properties of the receiving object are the same as those of the original object, since its wave function is exactly the same. This must be so since the observables of the object are determined by the wave function. This means that the receiving object will not be distinguishable from the original object, so for all intents and purposes it must be considered the same object. But from this conclusion the question again arises as to what is the nature of reality, since the process of teleportation is based on the transfer of information between the original object and the receiving object. Therefore, it seems obvious that information is a fundamental part of reality.
Another issue is the teleportation of biological objects. In this case the same argument could be used as in the case of non-animate objects. However, in this case it must be considered that in the framework of classical reality decoherence plays a fundamental role, since classical reality emerges as a consequence of the interaction of quantum systems, which observe one another, producing the collapse of their quantum functions, emerging states of classical reality.
This makes the process of entanglement of biological systems necessary in teleportation incompatible with what is defined as life, since this process would inhibit decoherence and therefore the emergence of classical reality. This issue has already been discussed in the posts Reality as an irreducible layered structure and A macroscopic view of Schrodinger’s cat, in which it is made clear that a living being is a set of independent quantum systems, and therefore not entangled among them. Therefore, the process of entanglement of all these systems will require the inhibition of all biological activity, something that will certainly have a profound effect on what is defined as a living being.
Since if teleportation is to be used to move an object to another location, system B must be relocated to that location prior to making measurements on system A and the ancillary system, which is governed by the laws of general relativity. Additionally, once the measurement has been performed, the information must be transferred to the location of system B, which is also limited by general relativity. In short, the teleportation process has no practical advantage over a classical transport process, especially considering that it is also susceptible to possible quantum errors.
Consequently, quantum applications are limited to the implementation of quantum networks and quantum computing systems, the structure of which can be found in the specialized literature [11] [12].
A bit of theory
The functionality of quantum systems is based on tensor calculus and quantum computation [13]. In particular, in order to illustrate the mathematical foundation underpinning quantum teleportation, the figure below shows the functionality of the Hadamard and CNOT logic gates needed to implement quantum teleportation.
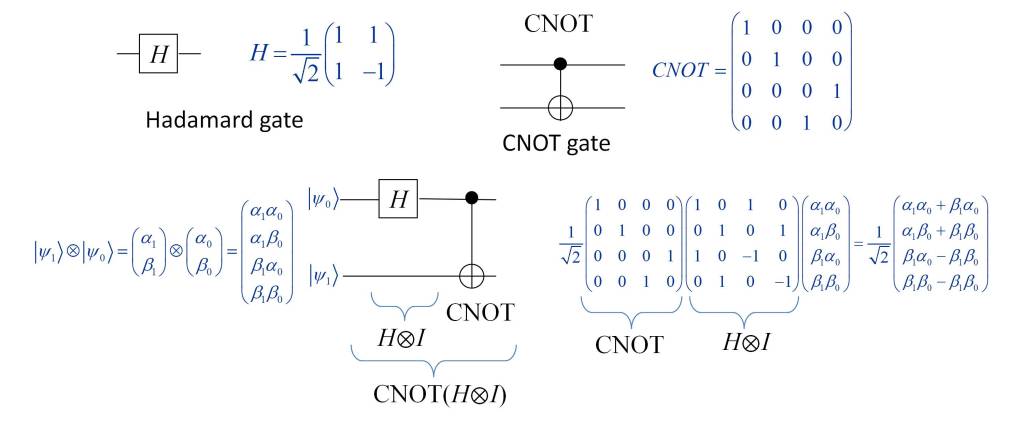
Additionally, the following figure shows the functionality of the Pauli gates, necessary to perform the transformation of the wave function of qubit B, once the measurement is performed on the A and auxiliary qubits.
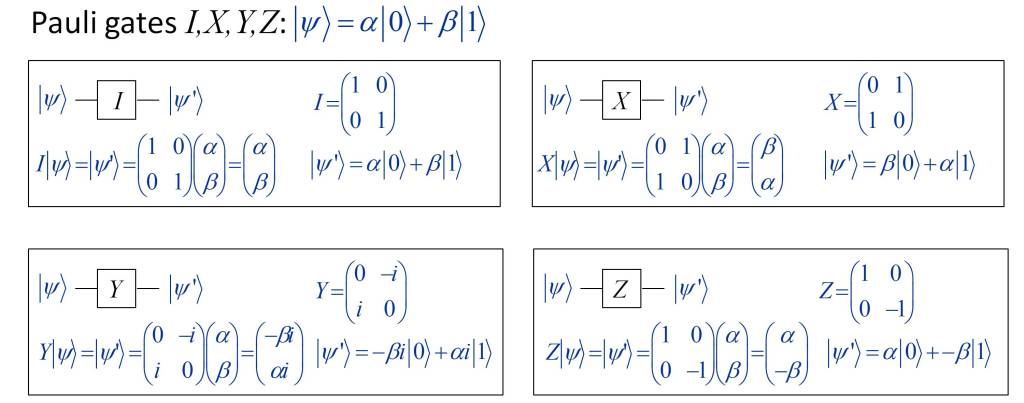
Conclusion
As discussed, quantum teleportation allows the transfer of quantum information between two remote locations by means of particle entanglement. This makes it possible to implement quantum communication and computing systems.
Although for the moment its experimental realization is limited to a very small number of particles, from a theoretical point of view it can be applied to macroscopic objects, which raises the possibility of applying it to transport objects of classical reality, even objects of a biological nature.
However, as has been analyzed, the application of teleportation to macroscopic objects poses a difficulty as a consequence of quantum decoherence, which implies the appearance of errors in the transferred quantum information.
On the other hand, quantum teleportation does not involve overcoming the limitations imposed by the theory of relativity, so the fictitious idea of using quantum teleportation as a means of transferring macroscopic objects at a distance instantaneously is not an option. But in addition, it must be considered that quantum entanglement of biological objects may not be compatible with what is defined as life.
| [1] | C. H. Bennett, G. Brassard, C. Crépeau, R. Jozsa, A. Peres and W. K. Wootters, “Teleporting an Unknown Quantum State via Dual Classical and Einstein-Podolsky-Rosen Channels,” Phys. Rev. Lett., vol. 70, pp. 1895-1899, 1993. |
| [2] | D. Bouwmeester, J.-W. Pan, K. Matte, M. Eibl, H. Weinfurter y A. Heilinger, «Experimental quantum teleportation,» arXiv:1901.11004v1 [quant-ph], 1997. |
| [3] | D. Boschi, S. Branca, F. De Martini, L. Hardy y S. Popescu, «Experimental Realization of Teleporting an Unknown Pure Quantum State via Dual Classical and Einstein-Podolsky-Rosen Channels,» Physical Review Letters, vol. 80, nº 6, pp. 1121-1125, 1998. |
| [4] | W. K. Wootters y W. H. Zurek, «A Single Quantum Cannot be Cloned,» Nature, vol. 299, pp. 802-803, 1982. |
| [5] | D. Dieks, «Communication by EPR devices,» Physics Letters, vol. 92A, nº 6, pp. 271-272, 1982. |
| [6] | E. Schrödinger, «Probability Relations between Separated Systems,» Mathematical Proceedings of the Cambridge Philosophical Society, vol. 32, nº 3, pp. 446-452, 1936. |
| [7] | A. Einstein, B. Podolsky and N. Rose, “Can Quantum-Mechanical Description of Physical Reality be Considered Complete?,” Physical Review, vol. 47, pp. 777-780, 1935. |
| [8] | J. S. Bell, «On the Einstein Podolsky Rosen Paradox,» Physics, vol. 1, nº 3, pp. 195-290, 1964. |
| [9] | A. Aspect, P. Grangier and G. Roger, “Experimental Tests of Realistic Local Theories via Bell’s Theorem,” Phys. Rev. Lett., vol. 47, pp. 460-463, 1981. |
| [10] | H. D. Zeh, «On the Interpretation of Measurement in Quantum Theory,» Found. Phys., vol. 1, nº 1, pp. 69-76, 1970. |
| [11] | T. Liu, «The Applications and Challenges of Quantum Teleportation,» Journal of Physics: Conference Series, vol. 1634, nº 1, 2020. |
| [12] | Z.-H. Yan, J.-L. Qin, Z.-Z. Qin, X.-L. Su, X.-J. Jia, C.-D. Xie y K.-C. Peng, «Generation of non-classical states of light and their application in deterministic quantum teleportation,» Fundamental Research, vol. 1, nº 1, pp. 43-49, 2021. |
| [13] | M. A. Nielsen and I. L. Chuang, Quantum computation and Quantum Information, Cambridge University Press, 2011. |