In view of the expansion of the Covid-19 in different countries, and taking as a reference the model of spreading exposed in the previous post, it is possible to make an interpretation of the data, in order to solve some doubts and contradictions raised in different forums.
But before starting this analysis, it is important to highlight an outstanding feature of the Covid-19 expansion shown by the model. In general, the modeling of infectious processes usually focuses on the infection rate of individuals, leaving temporal aspects such as incubation or latency periods of the pathogens in the background. This is justified as a consequence of the fact that their influence is generally unnoticed, besides introducing difficulties in the analytical study of the models.
However, in the case of Covid-19 its rapid expansion makes the effect of time parameters evident, putting health systems in critical situations and making it difficult to interpret the data that emerge as the pandemic spreads.
In this sense, the outstanding characteristics of the Covid-19 are:
The high capacity of infection.
The capacity of infection of individuals in the incubation phase.
The capacity of infection of asymptomatic individuals.
This makes the number of possible asymptomatic cases very high, presenting a great difficulty in diagnosis, as a result of the lack of resources caused by the novelty and rapid spread of the virus.
For this reason, the model has been developed taking into account the temporal parameters of the spread of the infection, which requires a numerical model, since the analytical solution is very complex and possibly without a purely analytical solution.
As a result, the model has a distinctive feature compared to conventional models, which is shown in the figure below.
This consists in that it is necessary to distinguish groups of asymptomatic and symptomatic individuals, since they present a temporal evolution delayed in time. As a consequence, the same happens with the curves of hospitalized and ICU individuals.
This allows clarifying some aspects linked to the real evolution of the virus. For example, in relation to the declaration of the exceptional measures in Italy and Spain, a substantial improvement in the contention of the pandemic was expected, something that still seems distant. The reason for this behavior is that the contention measures have been taken on the basis of the evolution of the curve of symptomatic individuals, ignoring the fact that there was already a very important population of asymptomatic individuals.
As can be seen in the graphs, the measurements should have been taken at least three weeks in advance, that is, according to the evolution curve of asymptomatic individuals. But in order to make this decision correctly, this data should have been available, something that was completely impossible, as a result of the lack of a test campaign on the population.
This situation is supported by the example of China, which although the spread of the virus could not be contained at an early stage, containment measures were taken several weeks earlier, on a comparative time scale.
The data from Germany are also very significant, exhibiting a much lower mortality rate than Italy and Spain. Although this raises a question about the capacity of infection in this country, it is actually easy to explain. In Italy and Spain, testing for Covid-19 infection is beginning. However, in Germany these tests have been carried out for several weeks at a rate of several hundred thousand per week. In contrast, the numbers of individuals diagnosed in Italy and Spain should be reviewed in the future.
This explains the lower mortality rate for a large number of infected individuals. This also has a decisive advantage, since early diagnosis allows for the isolation of infected individuals, reducing the possibility of infection of other individuals, which ultimately will result in a lower mortality rate.
Therefore, a quick conclusion can be made that can be summarized in the following points:
Measures to isolate the population are necessary but ineffective when taken at an advanced stage of the pandemic.
Early detection of infection is a totally decisive aspect in the contention of the pandemic and above all in the reduction of the mortality rate.
The reason for addressing this issue is twofold. On the one hand, Covid-19 is the most important challenge for humanity at the moment, but on the other hand the process of expansion of the virus is an example of how nature establishes models based on information processing.
The analysis of the dynamics of the virus expansion and its consequences will be based on a model implemented in Python, which for those who are interested can be downloaded, being able to make the changes that are considered appropriate to analyze different scenarios.
The model
The model is based on a structure of 14 states and 20 parameters, which determine the probabilities and the temporal dynamics of transitions between states. It is important to note that in the model the only vectors for virus spread are the “symptomatic” and “asymptomatic” states. The model also establishes parameters for the mobility of individuals and the rate of infection.
Some simplifications have been made to the model. Thus, it assumes that the geographical distribution of the population is homogeneous, which has contributed to a significant reduction in computational effort. In principle, this may seem to be a major limitation, but we will see that it is not an obstacle to drawing overall conclusions. The following figure represents in a simplified way the state diagram of the model. The conditions that establish the transitions can be consulted in the model.
The parameters have been adjusted according to experience gained from the progression of the virus, so information is limited and should be subject to further review. In any case, it seems clear that the virus has a high efficiency in infiltrating the cells to perform the copying process, so the viral load required for the infection seems to be small. This presupposes a high rate of infection, so it is also assumed that a significant part of the population will be infected.
Scenarios for the spread of the virus can be listed in the following sections:
Early action measures to confine the spread of the virus
Uncontrolled spread of the virus.
Exceptional measures to limit the propagation of virus.
The first scenario is not going to be analyzed as this is not the case in the current situation. This scenario can be analyzed by modifying the parameters of the model.
Therefore, the scenarios of interest are those of uncontrolled propagation and exceptional measures, as these represent the current state of the pandemic.
The natural evolution
The model dynamics for the case of uncontrolled propagation are shown in the figure below. It can be seen that the most important vectors in the propagation of the virus are asymptomatic individuals, for three fundamental reasons. The first is the broad impact of the virus on the population. The second is determined by the fact that it only produces a symptomatic picture in a limited fraction of the population. The third is directly related to the practical limitations in diagnosing asymptomatic individuals, as a consequence of the novelty and rapid spread of Covid-19.
For this reason, it seems clear that the extraordinary measures to contain the virus must be aimed at drastically limiting contact between humans. This is what has surely advised the possible suspension of academic activities, which includes the child and youth population, not because they are a risk group but because they are the most active population in the spread of the virus.
The other characteristic of the spreading dynamics is the abrupt temporary growth of those affected by the virus, until it reaches the whole population, initiating a rapid recovery, but condemning the groups at risk to be admitted to the Intensive Care Unit (ICU) and probably to death.
This will pose an acute problem in health systems, and an increase in collateral cases can be expected, which could easily surpass the direct cases produced by Covid-19. This makes it advisable to take extraordinary measures, but at the same time, the effectiveness of these measures is in doubt, since their rapid expansion may reduce the effectiveness of these measures, leading to late decision-making.
Present situation
This scenario is depicted in the following figures where quarantine is decreed for a large part of the population, restricting the movement of the propagation vectors. To confirm the above, two scenarios have been modeled. The first, in which the decision of extraordinary measures has been taken before the curve of diagnosed symptoms begins to grow, which in the figure occurs around day 40 from patient zero. The second in whom the decision has been taken a few days later, when the curve of diagnosed symptoms is clearly increasing, around day 65 from patient zero.
These two scenarios clearly indicate that it is more than possible that measures have been taken late and that the pandemic is following its natural course, due to the delay between the infected and symptomatic patient curves. Consequently, it seems that the containment measures will not be as effective as expected, and considering that economic factors will possibly have very profound consequences in the long and medium term for the well-being of society, alternative solutions should be considered.
It is interesting to note how the declaration of special measures modifies the temporal behavior of the pandemic. But once these have not been taken at an early stage of the virus’ emergence, the consequences are profound.
What can be expected
Obviously, the most appropriate solution would be to find remedies to cure the disease, which is being actively worked on, but which has a developmental period that may exceed those established by the dynamics of the pandemic.
However, since the groups at risk, the impact and the magnitude of these are known, a possible alternative solution would be:
Quarantine these groups, keeping them totally isolated from the virus and implementing care services to make this isolation effective until the pandemic subsides, or effective treatment is found.
Implement hospitals dedicated exclusively to the treatment of Covid-19.
For the rest of the population not included in the risk groups, continue with normal activity, allowing the pandemic to spread (something that already seems to be an inevitable possibility). However, strict prophylactic and safety measures must be taken.
This strategy has undeniable advantages. Firstly, it would reduce the pressure on the health system, preventing the collapse of normal system activity and leading to a faster recovery. Secondly, it would reduce the problems of treasury and cash management of states, which can lead to an unprecedented crisis, the consequences of which will certainly be more serious than the pandemic itself.
Finally, an important aspect of the model remains to be analyzed, such as its limitation for modeling a non-homogeneous distribution of the population. This section is easy to solve if we consider that it works correctly for cities. Thus, in order to model the case of a wider geographical extension, one only has to model the particular cases of each city or community with a time lag as the extension of the pandemic itself is showing.
One aspect, namely the duration of the extraordinary measures, remains to be determined. If it is considered that the viral load to infect an individual is small, it is possible that the remnants at the end of the quarantine period may reactivate the disease, in those individuals who have not yet been exposed to the virus or who have not been immunized. This is especially important considering that cured people may continue to be infected for another 15 days.
In previous posts, the nature of reality and its complexity has been approached from the point of view of Information Theory. However, it is interesting to make this analysis from the point of view of human perception and thus obtain a more intuitive view.
Obviously, making an exhaustive analysis of reality from this perspective is complex due to the diversity of the organs of perception and the physiological and neurological aspects that develop over them. In this sense, we could explain how the information perceived is processed, depending on each of the organs of perception. Especially the auditory and visual systems, as these are more culturally relevant. Thus, in the post dedicated to color perception it has been described how the physical parameters of light are encoded by the photoreceptor cells of the retina.
However, in this post the approach will consist of analyzing in an abstract way how knowledge influences the interpretation of information, in such a way that previous experience can lead the analysis in a certain direction. This behavior establishes a priori assumptions or conditions that limit the analysis of information in all its extension and that, as a consequence, prevent to obtain certain answers or solutions. Overcoming these obstacles, despite the conditioning posed by previous experience, is what is known as lateral thinking.
To begin with, let’s consider the case of series math puzzles in which a sequence of numbers, characters, or graphics is presented, asking how the sequence continues. For example, given the sequence “IIIIIIIVVV”, we are asked to determine which the next character is. If the Roman culture had not developed, it could be said that the next character is “V”, or also that the sequence has been made by little scribblers. But this is not the case, so the brain begins to engineer determining that the characters can be Roman and that the sequence is that of the numbers “1,2,3,…”. Consequently, the next character must be “I”.
In this way, it can be seen how the knowledge acquired conditions the interpretation of the information perceived by the senses. But from this example another conclusion can be drawn, consisting of the ordering of information as a sign of intelligence. To expose this idea in a formal way let’s consider a numerical sequence, for example the Fibonacci series “0,1,2,3,5,8,…”. Similarly to the previous case, the following number should be 13, so that the general term can be expressed as fn=fn-1+fn-2. However, we can define another discrete mathematical function that takes the values “0,1,2,3,5,8” for n = 0,1,2,3,4,5, but differs for the rest of the values of n belonging to the natural numbers, as shown in the following figure. In fact, with this criterion it is possible to define an infinite number of functions that meet this criterion.
The question, therefore, is: What is so special about the Fibonacci series in relation to the set of functions that meet the condition defined above?
Here we can make the argument already used in the case of the Roman number series. So that mathematical training leads to identifying the series of numbers as belonging to the Fibonacci series. But this poses a contradiction, since any of the functions that meet the same criterion could have been identified. To clear up this contradiction, Algorithmic Information Theory (AIT) should be used again.
Firstly, it should be stressed that culturally the game of riddles implicitly involves following logical rules and that, therefore, the answer is free from arbitrariness. Thus, in the case of number series the game consists of determining a rule that justifies the result. If we now try to identify a simple mathematical series that determines the sequence “0,1,2,3,5,8,…” we see that the expression fn=fn-1+fn-2 fulfills these requirements. In fact, it is possible that this is the simplest within this type of expressions. The rest are either complex, arbitrary or simple expressions that follow different rules from the implicit rules of the puzzle.
From the AIT point of view, the solution that contains the minimum information and can therefore be expressed most readily will be the most likely response that the brain will give in identifying a pattern determined by a stimulus. In the example above, the description of the predictable solution will be the one composed of:
A Turing machine.
The information to code the calculus rules.
The information to code the analytical expression of the simplest solution. In the example shown it corresponds to the expression of the Fibonacci series.
Obviously, there are solutions of similar or even less complexity, such as the one performed by a Turing machine that periodically generates the sequence “0,1,2,3,5,8”. But in most cases the solutions will have a more complex description, so that, according to the AIT, in most cases their most compact description will be the sequence itself, which cannot be compressed or expressed analytically.
For example, it is easy to check that the function:
generates for integer values of n the sequence “0,1,1,2,3,5,8,0,-62,-279,…”, so it could be said that the quantities following the proposed series are “…,0,-62,-279,… Obviously, the complexity of this sequence is higher than that of the Fibonacci series, as a result of the complexity of the description of the function and the operations to be performed.
Similarly, we can try to define other algorithms that generate the proposed sequence, which will grow in complexity. This shows the possibility of interpreting the information from different points of view that go beyond the obvious solutions, which are conditioned by previous experiences.
If, in addition to all the above, it is considered that, according to Landauer’s principle, information complexity is associated with greater energy consumption, the resolution of complex problems not only requires a greater computational effort, but also a greater energy effort.
This may explain the feeling of satisfaction produced when a certain problem is solved, and the tendency to engage in relaxing activities that are characterized by simplicity or monotony. Conversely, the lack of response to a problem produces frustration and restlessness.
This is in contrast to the idea that is generally held about intelligence. Thus, the ability to solve problems such as the ones described above is considered a sign of intelligence. But on the contrary, the search for more complex interpretations does not seem to have this status. Something similar occurs with the concept of entropy, which is generally interpreted as disorder or chaos and yet from the point of view of information it is a measure of the amount of information.
Another aspect that should be highlighted is the fact that the cognitive process is supported by the processing of information and, therefore, subject to the rules of mathematical logic, whose nature is irrefutable. This nuance is important, since emphasis is generally placed on the physical and biological mechanisms that support the cognitive processes, which may eventually be assigned a spiritual or esoteric nature.
Therefore, it can be concluded that the cognitive process is subject to the nature and structure of information processing and that from the formal point of view of the Theory of Computability it corresponds to a Turing machine. In such a way that nature has created a processing structure based on the physics of emerging reality – classical reality -, materialized in a neural network, which interprets the information coded by the perception senses, according to the algorithmic established by previous experience. As a consequence, the system performs two fundamental functions, as shown in the figure:
Interact with the environment, producing a response to the input stimuli.
Enhance the ability to interpret, acquiring new skills -algorithmic- as a result of the learning capacity provided by the neural network.
But the truth is that the input stimuli are conditioned by the sensory organs, which constitute a first filter of information and therefore they condition the perception of reality. The question that can be raised is: What impact does this filtering have on the perception of reality?
The purpose of physics is the description and interpretation of physical reality based on observation. To this end, mathematics has been a fundamental tool to formalize this reality through models, which in turn have allowed predictions to be made that have subsequently been experimentally verified. This creates an astonishing connection between reality and abstract logic that makes suspect the existence of a deep relationship beyond its conceptual definition. In fact, the ability of mathematics to accurately describe physical processes can lead us to think that reality is nothing more than a manifestation of a mathematical world.
But perhaps it is necessary to define in greater detail what we mean by this. Usually, when we refer to mathematics we think of concepts such as theorems or equations. However, we can have another view of mathematics as an information processing system, in which the above concepts can be interpreted as a compact expression of the behavior of the system, as shown by the algorithmic information theory [1].
In this way, physical laws determine how the information that describes the system is processed, establishing a space-time dynamic. As a consequence, a parallelism is established between the physical system and the computational system that, from an abstract point of view, are equivalent. This equivalence is somewhat astonishing, since in principle we assume that both systems belong to totally different fields of knowledge.
But apart from this fact, we can ask what consequences can be drawn from this equivalence. In particular, computability theory [2] and information theory [3] [1] provide criteria for determining the computational reversibility and complexity of a system [4]. In particular:
In a reversible computing system (RCS) the amount of information remains constant throughout the dynamics of the system.
In a non-reversible computational system (NRCS) the amount of information never increases along the dynamics of the system.
The complexity of the system corresponds to the most compact expression of the system, called Kolmogorov complexity and is an absolute measure.
It is important to note that in an NRCS system information is not lost, but is explicitly discarded. This means that there is no fundamental reason why such information should not be maintained, as the complexity of an RCS system remains constant. In practice, the implementation of computer systems is non-reversible in order to optimize resources, as a consequence of the technological limitations for its implementation. In fact, the energy currently needed for its implementation is much higher than that established by the Landauer principle [5].
If we focus on the analysis of reversible physical systems, such as quantum mechanics, relativity, Newtonian mechanics or electromagnetism, we can observe invariant physical magnitudes that are a consequence of computational reversibility. These are determined by unitary mathematical processes, which mean that every process has an inverse process [6]. But the difficulties in understanding reality from the point of view of mathematical logic seem to arise immediately, with thermodynamics and quantum measurement being paradigmatic examples.
In the case of quantum measurement, the state of the system before the measurement is made is in a superposition of states, so that when the measurement is made the state collapses in one of the possible states in which the system was [7]. This means that the quantum measurement scenario corresponds to that of a non-reversible computational system, in which the information in the system decreases when the superposition of states disappears, making the system non-reversible as a consequence of the loss of information.
This implies that physical reality systematically loses information, which poses two fundamental contradictions. The first is the fact that quantum mechanics is a reversible theory and that observable reality is based on it. The second is that this loss of information contradicts the systematic increase of classical entropy, which in turn poses a deeper contradiction, since in classical reality there is a spontaneous increase of information, as a consequence of the increase of entropy.
The solution to the first contradiction is relatively simple if we eliminate the anthropic vision of reality. In general, the process of quantum measurement introduces the concept of observer, which creates a certain degree of subjectivity that is very important to clarify, as it can lead to misinterpretations. In this process there are two clearly separated layers of reality, the quantum layer and the classical layer, which have already been addressed in previous posts. The realization of quantum measurement involves two quantum systems, one that we define as the system to be measured and another that corresponds to the measurement system, which can be considered as a quantum observer, and both have a quantum nature. As a result of this interaction, classical information emerges, where the classical observer is located, who can be identified e.g. with a physicist in a laboratory.
Now consider that the measurement is structured in two blocks, one the quantum system under observation and the other the measurement system that includes the quantum observer and the classical observer. In this case it is being interpreted that the quantum system under measurement is an open quantum system that loses quantum information in the measurement process and that as a result a lesser amount of classical information emerges. In short, this scenario offers a negative balance of information.
But, on the contrary, in the quantum reality layer the interaction of two quantum systems takes place which, it can be said, mutually observe each other according to unitary operators, so that the system is closed producing an exchange of information with a null balance of information. As a result of this interaction, the classical layer emerges. But then there seems to be a positive balance of information, as classical information emerges from this process. But what really happens is that the emerging information, which constitutes the classical layer, is simply a simplified view of the quantum layer. For this reason we can say that the classical layer is an emerging reality.
So, it can be said that the quantum layer is formed by subsystems that interact with each other in a unitary way, constituting a closed system in which the information and, therefore, the complexity of the system is invariant. As a consequence of these interactions, the classical layer emerges as an irreducible reality of the quantum layer.
As for the contradiction produced by the increase in entropy, the reasons justifying this behavior seem more subtle. However, a first clue may lie in the fact that this increase occurs only in the classical layer. It must also be considered that, according to the algorithmic information theory, the complexity of a system, and therefore the amount of information that describes the system, is the set formed by the processed information and the information necessary to describe the processor itself.
A physical scenario that can illustrate this situation is the case of the big bang [8], in which it is considered that the entropy of the system in its beginning was small or even null. This is so because the microwave background radiation shows a fairly homogeneous pattern, so the amount of information for its description and, therefore, its entropy is small. But if we create a computational model of this scenario, it is evident that the complexity of the system has increased in a formidable way, which is incompatible from the logical point of view. This indicates that in the model not only the information is incomplete, but also the description of the processes that govern it. But what physical evidence do we have to show that this is so?
Perhaps the clearest sample of this is cosmic inflation [9], so that the space-time metric changes with time, so that the spatial dimensions grow with time. To explain this behavior the existence of dark energy has been postulated as the engine of this process [10], which in a physical form recognizes the gaps revealed by mathematical logic. Perhaps one aspect that is not usually paid attention is the interaction between vacuum and photons, which produces a loss of energy in photons as space-time expands. This loss supposes a decrease of information that necessarily must be transferred to space-time.
This situation causes the vacuum, which in the context of classical physics is nothing more than an abstract metric, to become a fundamental physical piece of enormous complexity. Aspects that contribute to this conception of vacuum are the entanglement of quantum particles [11], decoherence and zero point energy [12].
From all of the above, a hypothesis can be made as to what the structure of reality is from a computational point of view, as shown in the following figure. If we assume that the quantum layer is a unitary and closed structure, its complexity will remain constant. But the functionality and complexity of this remains hidden from observation and it is only possible to model it through an inductive process based on experimentation, which has led to the definition of physical models, in such a way that these models allow us to describe classical reality. As a consequence, the quantum layer shows a reality that constitutes the classical layer and that is a partial vision and, according to the theoretical and experimental results, extremely reduced of the underlying reality and that makes the classical reality an irreducible reality.
The fundamental question that can be raised in this model is whether the complexity of the classical layer is constant or whether it can vary over time, since it is only bound by the laws of the underlying layer and is a partial and irreducible view of that functional layer. But for the classical layer to be invariant, it must be closed and therefore its computational description must be closed, which is not verified since it is subject to the quantum layer. Consequently, the complexity of the classical layer may change over time.
Consequently, the question arises as to whether there is any mechanism in the quantum layer that justifies the fluctuation of the complexity of the classical layer. Obviously one of the causes is quantum decoherence, which makes information observable in the classical layer. Similarly, cosmic inflation produces an increase in complexity, as space-time grows. On the contrary, attractive forces tend to reduce complexity, so gravity would be the most prominent factor.
From the observation of classical reality we can answer that currently its entropy tends to grow, as a consequence of the fact that decoherence and inflation are predominant causes. However, one can imagine recession scenarios, such as a big crunch scenario in which entropy decreased. Therefore, the entropy trend may be a consequence of the dynamic state of the system.
In summary, it can be said that the amount of information in the quantum layer remains constant, as a consequence of its unitary nature. On the contrary, the amount of information in the classical layer is determined by the amount of information that emerges from the quantum layer. Therefore, the challenge is to determine precisely the mechanisms that determine the dynamics of this process. Additionally, it is possible to analyze specific scenarios that generally correspond to the field of thermodynamics. Other interesting scenarios may be quantum in nature, such as the one proposed by Hugh Everett on the Many-Worlds Interpretation (MWI).
Bibliography
[1]
P. Günwald and P. Vitányi, “Shannon Information and Kolmogorov Complexity,” arXiv:cs/0410002v1 [cs:IT], 2008.
[2]
M. Sipser, Introduction to the Theory of Computation, Course Technology, 2012.
[3]
C. E. Shannon, “A Mathematical Theory of Communication,” vol. 27, pp. 379-423, 623-656, 1948.
[4]
M. A. Nielsen and I. L. Chuang, Quantum computation and Quantum Information, Cambridge University Press, 2011.
[5]
R. Landauer, «Irreversibility and Heat Generation in Computing Process,» IBM J. Res. Dev., vol. 5, pp. 183-191, 1961.
[6]
J. Sakurai y J. Napolitano, Modern Quantum Mechanics, Cambridge University Press, 2017.
[7]
G. Auletta, Foundations and Interpretation of Quantum Mechanics, World Scientific, 2001.
[8]
A. H. Guth, The Inflationary Universe, Perseus, 1997.
[9]
A. Liddle, An Introduction to Modern Cosmology, Wiley, 2003.
[10]
P. J. E. Peebles and Bharat Ratra, “The cosmological constant and dark energy,” arXiv:astro-ph/0207347, 2003.
[11]
A. Aspect, P. Grangier and G. Roger, “Experimental Tests of Realistic Local Theories via Bell’s Theorem,” Phys. Rev. Lett., vol. 47, pp. 460-463, 1981.
[12]
H. B. G. Casimir and D. Polder, “The Influence of Retardation on the London-van der Waals Forces,” Phys. Rev., vol. 73, no. 4, pp. 360-372, 1948.
There is no doubt that since the origins of geometry humans have been seduced by the number π. Thus, one of its fundamental characteristics is that it determines the relationship between the length of a circumference and its radius. But this does not stop here, since this constant appears systematically in mathematical and scientific models that describe the behavior of nature. In fact, it is so popular that it is the only number that has its own commemorative day. The great fascination around π has raised speculations about the information encoded in its figures and above all has unleashed an endless race for its determination, having calculated several tens of billions of figures to date.
Formally, the classification of real numbers is done according to the rules of calculus. In this way, Cantor showed that real numbers can be classified as countable infinities and uncountable infinities, what are commonly called rational and irrational. Rational numbers are those that can be expressed as a quotient of two whole numbers. While irrational numbers cannot be expressed this way. These in turn are classified as algebraic numbers and transcendent numbers. The former correspond to the non-rational roots of the algebraic equations, that is, the roots of polynomials. On the contrary, transcendent numbers are solutions of transcendent equations, that is, non-polynomial, such as exponential and trigonometric functions.
Georg Cantor. Co-creator of Set Theory
Without going into greater detail, what should catch our attention is that this classification of numbers is based on positional rules, in which each figure has a hierarchical value. But what happens if the numbers are treated as ordered sequences of bits, in which the position is not a value attribute. In this case, the Algorithmic Information Theory (AIT) allows to establish a measure of the information contained in a finite sequence of bits, and in general of any mathematical object, and that therefore is defined in the domain of natural numbers.
What does the AIT tell us?
This measure is based on the concept of Kolmogorov complexity (KC). So that, the Kolmogorov complexity K(x) of a finite object x is defined as the length of the shortest effective binary description of x. Where the term “effective description” connects the Kolmogorov complexity with the Theory of Computation, so that K(x) would correspond to the length of the shortest program that prints x and enters the halt state. To be precise, the formal definition of K(x) is:
K(x) = minp,i{K(i) + l(p):Ti (p) = x } + O(1)
Where Ti(p) is the Turing machine (TM) i that executes p and prints x, l(p) is the length of p, and K(i) is the complexity of Ti. Therefore, object p is a compressed representation of object x, relative to Ti, since x can be retrieved from p by the decoding process defined by Ti, so it is defined as meaningful information. The rest is considered as meaningless, redundant, accidental or noise (meaningless information). The term O(1) indicates that K(i) is a recursive function and in general it is non-computable, although by definition it is machine independent, and whose result has the same order of magnitude in each one of the implementations. In this sense, Gödel’s incompleteness theorems, Turing machine and Kolmogorov complexity lead to the same conclusion about undecidability, revealing the existence of non-computable functions.
KC shows that information can be compressed, but does not establish any general procedure for its implementation, which is only possible for certain sequences. In effect, from the definition of KC it is demonstrated that this is an intrinsic property of bitstreams, in such a way that there are sequences that cannot be compressed. Thus, the number of n-bit sequences that can be encoded by m bits is less than 2m, so the fraction of n-bit sequences with K(x) ≥ n-k is less than 2-k. If the n-bit possible sequences are considered, each one of them will have a probability of occurrence equal to 2-n, so the probability that the complexity of a sequence is K(x) ≥ n-k is equal to or greater than (1-2-k). In short, most bit sequences cannot be compressed beyond their own size, showing a high complexity as they do not present any type of pattern. Applied to the field of physics, this behavior justifies the ergodic hypothesis. As a consequence, this means that most of the problems cannot be solved analytically, since they can only be represented by themselves and as a consequence they cannot be described in a compact way by means of formal rules.
It could be thought that the complexity of a sequence can be reduced at will, by applying a coding criterion that modifies the sequence into a less complex sequence. In general, this only increases the complexity, since in the calculation of K(x) we would have to add the complexity of the coding algorithm that makes it grow as n2. Finally, add that the KC is applicable to any mathematical object, integers, sets, functions, and it is demonstrated that, as the complexity of the mathematical object grows, K(x) is equivalent to the entropy H defined in the context of Information Theory. The advantage of AIT is that it performs a semantic treatment of information, being an axiomatic process, so it does not require having a priori any type of alphabet to perform the measurement of information.
What can be said about the complexity of π?
According to its definition, KC cannot be applied to irrational numbers, since in this case the Turing machine does not reach the halt state, and as we know these numbers have an infinite number of digits. In other words, and to be formally correct, the Turing machine is only defined in the field of natural numbers (it must be noted that their cardinality is the same as that of the rationals), while irrational numbers have a cardinality greater than that of rational numbers. This means that KC and the equivalent entropy H of irrational numbers are undecidable and therefore non-computable.
To overcome this difficulty we can consider an irrational number X as the concatenation of a sequence of bits composed of a rational number x and a residue δx, so that in numerical terms X=x+δx, but in terms of information X={x,δx}. As a consequence, δx is an irrational number δx→0, and therefore δx is a sequence of bits with an undecidable KC and hence non-computable. In this way, it can be expressed:
K(X) = K(x)+K(δx)
The complexity of X can be assimilated to the complexity of x. A priori this approach may seem surprising and inadmissible, since the term K(δx) is neglected when in fact it has an undecidable complexity. But this is similar to the approximation made in the calculation of the entropy of a continuous variable or to the renormalization process used in physics, in order to circumvent the complexity of the underlying processes that remain hidden from observable reality.
Consequently, the sequence p, which runs the Turing machine i to get x, will be composed of the concatenation of:
The sequence of bits that encode the rules of calculus in the Turing machine i.
The bitstream that encodes the compressed expression of x, for example a given numerical series of x.
The length of the sequence x that is to be decoded and that determines when the Turing machine should reach the halt state, for example a googol (10100).
In short, it can be concluded that the complexity K(x) of known irrational numbers, e.g. √2, π, e,…, is limited. For this reason, the challenge must be to obtain the optimum expression of K(x) and not the figures that encode these numbers, since according to what has been said, their uncompressed expression, or the development of their figures, has a high degree of redundancy (meaningless information).
What in theory is a surprising and questionable fact is in practice an irrefutable fact, since the complexity of δx will always remain hidden, since it is undecidable and therefore non-computable.
Another important conclusion is that it provides a criterion for classifying irrational numbers into two groups: representable and non-representable. The former correspond to irrational numbers that can be represented by mathematical expressions, which would be the compressed expression of these numbers. While non-representable numbers would correspond to irrational numbers that could only be expressed by themselves and are therefore undecidable. In short, the cardinality of representable irrational numbers is that of natural numbers. It should be noted that the previous classification criterion is applicable to any mathematical object.
On the other hand, it is evident that mathematics, and calculus in particular, de facto accepts the criteria established to define the complexity K(x). This may go unnoticed because, traditionally in this context, numbers are analyzed from the perspective of positional coding, in such a way that the non-representable residue is filtered out through the concept of limit, in such a way that δx→0. However, when it comes to evaluating the informative complexity of a mathematical object, it may be required to apply a renormalization procedure.
From the analysis carried out in the previous post, it can be concluded that, in general, it is not possible to identify the macroscopic states of a complex system with its quantum states. Thus, the macroscopic states corresponding to the dead cat (DC) or to the living cat (AC) cannot be considered quantum states, since according to quantum theory the system could be expressed as a superposition of these states. Consequently, as it has been justified, for macroscopic systems it is not possible to define quantum states such as |DC⟩ and |DC⟩. On the other hand, the states (DC) and (AC) are an observable reality, indicating that the system presents two realities, a quantum reality and an emerging reality that can be defined as classical reality.
Quantum reality will be defined by its wave function, formed by the superposition of the quantum subsystems that make up the system and which will evolve according to the existing interaction between all the quantum elements that make up the system and the environment. For simplicity, if the CAT system is considered isolated from the environment, the succession of its quantum state can be expressed as:
Expression in which it has been taken into account
that the number of non-entangled quantum subsystems k also varies with time, so
it is a function of the sequence n, considering time as a discrete
variable.
The observable classical reality can be described by the state of the system that, if for the object “cat” is defined as (CAT[n]), from the previous reasoning it is concluded that (CAT[n]) ≢ |CAT[n]⟩. In other words, the quantum and classical states of a complex object are not equivalent.
The question that remains to be justified is the irreducibility of the observable classical state (CAT) from the underlying quantum reality, represented by the quantum state |CAT⟩. This can be done if it is considered that the functional relationship between states |CAT⟩ and (CAT) is extraordinarily complex, being subject to the mathematical concepts on which complex systems are based, such as they are:
The complexity of the space of quantum states (Hilbert space).
The random behavior of observable information emerging from quantum reality.
The enormous number of quantum entities involved in a macroscopic system.
The non-linearity of the laws of classical physics.
Based on Kolmogorov complexity [1], it is possible to prove that the behavior of systems with these characteristics does not support, in most cases, an analytical solution that determines the evolution of the system from its initial state. This also implies that, in practice, the process of evolution of a complex object can only be represented by itself, both on a quantum and a classical level.
According to the algorithmic information theory [1], this process is equivalent to a mathematical object composed of an ordered set of bits processed according to axiomatic rules. In such a way that the information of the object is defined by the Kolmogorov complexity, in a manner that it remains constant throughout time, as long as the process is an isolated system. It should be pointed out that the Kolmogorov complexity makes it possible to determine the information contained in an object, without previously having an alphabet for the determination of its entropy, as is the case in the information theory [2], although both concepts coincide at the limit.
From this point of view, two fundamental questions
arise. The first is the evolution of the entropy of the system and the second
is the apparent loss of information in the observation process, through which
classical reality emerges from quantum reality. This opens a possible line of
analysis that will be addressed later.
But going back to the analysis of what is the relationship between classic and quantum states, it is possible to have an intuitive view of how the state (CAT) ends up being disconnected from the state |CAT⟩, analyzing the system qualitatively.
First, it should be noted that virtually 100% of the quantum information contained in the state |CAT⟩ remains hidden within the elementary particles that make up the system. This is a consequence of the fact that the physical-chemical structure [3] of the molecules is determined exclusively by the electrons that support its covalent bonds. Next, it must be considered that the molecular interaction, on which molecular biology is based, is performed by van der Waals forces and hydrogen bonds, creating a new level of functional disconnection with the underlying layer.
Supported by this functional level appears a new functional structure formed by cellular biology [4], from which appear living organisms, from unicellular beings to complex beings formed by multicellular organs. It is in this layer that the concept of living being emerges, establishing a new border between the strictly physical and the concept of perception. At this level the nervous tissue [5] emerges, allowing the complex interaction between individuals and on which new structures and concepts are sustained, such as consciousness, culture, social organization, which are not only reserved to human beings, although it is in the latter where the functionality is more complex.
But to the complexity of the functional layers must be
added the non-linearity of the laws to which they are subject and which are necessary and sufficient conditions for a behavior of deterministic chaos [6] and which, as previously justified, is based on the algorithmic information theory [1]. This means that any variation in the initial conditions will produce a different dynamic, so that any emulation will end up diverging from the original, this behavior being the justification of free will. In this sense, Heisenberg’s uncertainty principle [7] prevents from knowing exactly the initial conditions of the classical system, in any of the functional layers described above. Consequently, all of them will have an irreducible nature and an unpredictable dynamic, determined exclusively by the system itself.
At this point and in view of this complex functional structure, we must ask what the state (CAT) refers to, since in this context the existence of a classical state has been implicitly assumed. The complex functional structure of the object “cat” allows a description at different levels. Thus, the cat object can be described in different ways:
As atoms and molecules subject to the laws of physical chemistry.
As molecules that interact according to molecular biology.
As complex sets of molecules that give rise to cell biology.
As sets of cells to form organs and living organisms.
As structures of information processing, that give rise to the mechanisms of perception and interaction with the environment that allow the development of individual and social behavior.
As a result, each of these functional layers can be expressed by means of a certain state. So to speak of, the definition of a unique macroscopic state (CAT) is not correct. Each of these states will describe the object according to different functional rules, so it is worth asking what relationship exists between these descriptions and what their complexity is. Analogous to the arguments used to demonstrate that the states |CAT⟩ and (CAT) are not equivalent and are uncorrelated with each other, the states that describe the “cat” object at different functional levels will not be equivalent and may to some extent be disconnected from each other.
This behavior is a proof of how reality is structured in irreducible functional layers, in such a way that each one of the layers can be modeled independently and irreducibly, by means of an ordered set of bits processed according to axiomatic rules.
Refereces
[1]
P. Günwald and P. Vitányi, “Shannon Information and Kolmogorov Complexity,” arXiv:cs/0410002v1 [cs:IT], 2008.
[2]
C. E. Shannon, «A Mathematical Theory of Communication,» The Bell System Technical Journal, vol. 27, pp. 379-423, 1948.
[3]
P. Atkins and J. de Paula, Physical Chemestry, Oxford University Press, 2006.
[4]
A. Bray, J. Hopkin, R. Lewis and W. Roberts, Essential Cell Biology, Garlan Science, 2014.
[5]
D. Purves and G. J. Augustine, Neuroscience, Oxford Univesisty press, 2018.
[6]
J. Gleick, Chaos: Making a New Science, Penguin Books, 1988.
[7]
W. Heisenberg, «The Actual Content of Quantum Theoretical Kinematics and Mechanics,» Zeit-schrift fur Physik. Translation: NASA TM-77379., vol. 43, nº 3-4, pp. 172-198, 1927.
Note: This post is the first in a series in which macroscopic objects will be analyzed from a quantum and classical point of view, as well as the nature of the observation. Finally, all of them will be integrated into a single article.
Introduction
Quantum theory establishes the fundamentals of the behavior of particles and their interaction with each other. In general, these fundamentals apply to microscopic systems formed by a very limited number of particles. However, nothing indicates that the application of quantum theory cannot be applied to macroscopic objects, since the emerging properties of such objects must be based on the underlying quantum reality. Obviously, there is a practical limitation established by the increase in complexity, which grows exponentially as the number of elementary particles increases.
The initial reference to this approach was made by Schrödinger [1], indicating that the quantum superposition of states did not represent any contradiction at the macroscopic level. To do this, he used what is known as Schrödinger’s cat paradox in which the cat could be in a superposition of states, one in which the cat was alive and another in which the cat was dead. Schrödinger’s original motivation was to raise a discussion about the EPR paradox [2], which revealed the incompleteness of quantum theory. This has finally been solved by Bell’s theorem [3] and its experimental verification by Aspect [4], making it clear that the entanglement of quantum particles is a reality on which quantum computation is based [5]. A summary of the aspects related to the realization of a quantum system that emulates Schrödinger cat has been made by Auletta [6], although these are restricted to non-macroscopic quantum systems.
But the question that remains is whether quantum theory can be used to describe macroscopic objects and whether the concept of quantum entanglement applies to these objects as well. Contrary to Schrödinger’s position, Wigner argued, through the friend paradox, that quantum mechanics could not have unlimited validity [7]. Recently, Frauchiger and Renner [8] have proposed a virtual experiment (Gedankenexperiment) that shows that quantum mechanics is not consistent when applied to complex objects.
The Schrödinger cat paradigm will be used to analyze these results from two points of view, with no loss of generality, one as a quantum object and the other as a macroscopic object (in a next post). This will allow their consistency and functional relationship to be determined, leading to the establishment of an irreducible functional structure. As a consequence of this, it will also be necessary to analyze the nature of the observer within this functional structure (also in a later posts).
Schrödinger’s cat as a quantum reality
In the Schrödinger cat experiment there are several entities [1], the radioactive particle, the radiation monitor, the poison flask and the cat. For simplicity, the experiment can be reduced to two quantum variables: the cat, which we will identify as CAT, and the system formed by the radioactive particle, the radiation monitor and the poison flask, which we will define as the poison system PS.
|CAT⟩ = α1|DC⟩ + β1|LC⟩. Quantum state of the cat: dead cat |DC⟩, live cat |LC⟩.
|PS⟩ = α2|PD⟩ + β2|PA⟩. Quantum state of the poison system: poison deactivated |PD⟩, poison activated |PA⟩.
The quantum state of the Schrödinger cat experiment SCE as a whole can be expressed as: |SCE⟩ = |CAT⟩⊗|PS⟩= α1α2|DC⟩|PD⟩+α1β2|DC⟩|PA⟩+β1α2|LC⟩|PD⟩+β1β2|LC⟩|PA⟩.
Since for a classical observer the final result of the experiment requires that the states |DC⟩|PD⟩ and |LC⟩|PA⟩ are not compatible with observations, the experiment must be prepared in such a way that the quantum states |CAT⟩ and |PS⟩ are entangled [10] [11], so that the wave function of the experiment must be:
|SCE⟩ = α|DC⟩|PA⟩ + β|LC⟩|PD⟩.
As a consequence, the observation of the experiment [12] will result in a state:
|SCE⟩ = |DC⟩|PA⟩, with probability α2, (poison activated, dead cat).
or:
|SCE⟩ =|LC⟩|PD⟩, with probability β2, (poison deactivated, live cat).
Although from the formal point of view of quantum theory the approach of the experiment is correct, for a classical observer the experiment presents several objections. One of these is related to the fact that the experiment requires establishing “a priori” the requirement that the PS and CAT systems are entangled. Something contradictory, since from the point of view of the preparation of the quantum experiment there is no restriction, being able to exist results with quantum states |DC⟩|PD⟩, or |LC⟩|PA⟩, something totally impossible for a classical observer, assuming in any case that the poison is effective, that it is taken for granted in the experiment. Therefore, the SCE experiment is inconsistent, so it is necessary to analyze the root of the incongruence between the SCE quantum system and the result of the observation.
Another objection, which may seem trivial, is that for the SCE experiment to collapse in one of its states the OBS observer must be entangled with the experiment, since the experiment must interact with it. Otherwise, the operation performed by the observer would have no consequence on the experiment. For this reason, this aspect will require more detailed analysis.
Returning to the first objection, from the perspective of quantum theory it may seem possible to prepare the PS and CAT systems in an entangled superposition of states. However, it should be noted that both systems are composed of a huge number of non-entangled quantum subsystems Si subject to continuous decoherence [13] [14]. It should be noted that the Si subsystems will internally have an entangled structure. Thus, the CAT and PS systems can be expressed as:
|CAT⟩ = |SC1⟩ ⊗ |SC2⟩ ⊗…⊗ |SCi⟩ ⊗…⊗ |SCk⟩,
|PS⟩= |SP1⟩⊗|SP2⟩⊗…⊗|SPi⟩⊗…⊗|SPl⟩,
in such a way that the observation of a certain subsystem causes its state to collapse, producing no influence on the rest of the subsystems, which will develop an independent quantum dynamics. This makes it unfeasible that the states |LC⟩ and |DC⟩ can be simultaneous and as a consequence the CAT system cannot be in a superposition of these states. An analogous reasoning can be made of the PS system, although it imay seem obvious that functionally it is much simpler.
In short, from a theoretical point of view it is possible to have a quantum system equivalent to the SCE, for which all the subsystems must be fully entangled with each other, and in addition the system will require an “a priori” preparation of its state. However, the emerging reality differs radically from this scenario, so that the experiment seems to be unfeasible in practice. But the most striking fact is that, if the SCE experiment is generalized, the observable reality would be radically different from the observed reality.
To better understand the consequences of the quantum state of the ECS system having to be prepared “a priori”, imagine that the supplier of the poison has changed its contents to a harmless liquid. As a result of this, the experiment will be able to kill the cat without cause.
From these conclusions the question can be raised as to whether quantum theory can explain in a general and consistent way the observable reality at the macroscopic level. But perhaps the question is also whether the assumptions on which the SCE experiment has been conducted are correct. Thus, for example: Is it correct to use the concepts of live cat or dead cat in the domain of quantum physics? Which in turn raises other kinds of questions, such as: Is it generally correct to establish a strong link between observable reality and the underlying quantum reality?
The conclusion that can be drawn from the contradictions of the SCE experiment is that the scenario of a complex quantum system cannot be treated in the same terms as a simple system. In terms of quantum computation these correspond, respectively, to systems made up of an enormous number and a limited number of qubits [5]. As a consequence of this, classical reality will be an irreducible fact, which based on quantum reality ends up being disconnected from it. This leads to defining reality in two independent and irreducible functional layers, a quantum reality layer and a classical reality layer. This would justify the criterion established by the Copenhagen interpretation [15] and its statistical nature as a means of functionally disconnecting both realities. Thus, quantum theory would be nothing more than a description of the information that can emerge from an underlying reality, but not a description of that reality. At this point, it is important to emphasize that statistical behavior is the means by which the functional correlation between processes can be reduced or eliminated [16] and that it would be the cause of irreducibility.
References
[1]
E. Schrödinger, «Die gegenwärtige Situation in der Quantenmechanik,» Naturwissenschaften, vol. 23, pp. 844-849, 1935.
[2]
A. Einstein, B. Podolsky and N. Rose, “Can Quantum-Mechanical description of Physical Reality be Considered Complete?,” Physical Review, vol. 47, pp. 777-780, 1935.
[3]
J. S. Bell, «On the Einstein Podolsky Rosen Paradox,» Physics,vol. 1, nº 3, pp. 195-290, 1964.
[4]
A. Aspect, P. Grangier and G. Roger, “Experimental Tests of Realistic Local Theories via Bell’s Theorem,” Phys. Rev. Lett., vol. 47, pp. 460-463, 1981.
[5]
M. A. Nielsen and I. L. Chuang, Quantum computation and Quantum Information, Cambridge University Press, 2011.
[6]
G. Auletta, Foundations and Interpretation of Quantum Mechanics, World Scientific, 2001.
[7]
E. P. Wigner, «Remarks on the mind–body question,» in Symmetries and Reflections, Indiana University Press, 1967, pp. 171-184.
[8]
D. Frauchiger and R. Renner, “Quantum Theory Cannot Consistently Describe the Use of Itself,” Nature Commun., vol. 9, no. 3711, 2018.
[9]
P. Dirac, The Principles of Quantum Mechanics, Oxford University Press, 1958.
[10]
E. Schrödinger, «Discussion of Probability Relations between Separated Systems,» Mathematical Proceedings of the Cambridge Philosophical Society, vol. 31, nº 4, pp. 555-563, 1935.
[11]
E. Schrödinger, «Probability Relations between Separated Systems,» Mathematical Proceedings of the Cambridge Philosophical Society, vol. 32, nº 3, pp. 446-452, 1936.
[12]
M. Born, «On the quantum mechanics of collision processes.,» Zeit. Phys.(D. H. Delphenich translation), vol. 37, pp. 863-867, 1926.
[13]
H. D. Zeh, «On the Interpretation of Measurement in Quantum Theory,» Found. Phys., vol. 1, nº 1, pp. 69-76, 1970.
[14]
W. H. Zurek, «Decoherence, einselection, and the quantum origins of the classical,» Rev. Mod. Phys., vol. 75, nº 3, pp. 715-775, 2003.
[15]
W. Heisenberg, Physics and Philosophy. The revolution in Modern Science, Harper, 1958.
Visible light, heat, radio waves and other types of radiation all have the same physical nature and are constituted by a flow of particles called photons. The photon or “light quantum” was proposed by Einstein, for which he was awarded the Nobel Prize in 1921 and is one of the elementary particles of the standard model, belonging to the boson family. The fundamental characteristic of a photon is its capacity to transfer energy in quantized form, which is determined by its frequency, according to the expression E=h∙ν, where h is the Planck constant and ν the frequency of the photon.
Electromagnetic spectrum
Thus, we can find photons of very low frequencies located in the band of radio waves, to photons of very high energy called gamma rays, as shown in the following figure, forming a continuous frequency range that constitutes the electromagnetic spectrum. Since the photon can be modeled as a sinusoid traveling at the speed of light c, the length of a complete cycle is called the photon wavelength λ, so the photon can be characterized either by its frequency or its wavelength, since λ=c/ν. But it is common to use the term color as a synonym for frequency, since the color of light perceived by humans is a function of frequency. However, as we are going to see, this is not strictly physical but a consequence of the process of measuring and interpreting information, which makes color an emerging reality of another underlying reality, sustained by the physical reality of electromagnetic radiation.
Structure of an electromagnetic wave
But before addressing this issue, it should be considered that to detect photons efficiently it is necessary to have a detector called an antenna, whose size must be similar to the wavelength of the photons.
Color perception by humans
The human eye is sensitive to wavelengths ranging from deep red (700nm, nanometers=10-9 meters) to violet (400nm). This requires receiving antennas of the order of hundreds of nanometres in size! But for nature this is not a big problem, as complex molecules can easily be this size. In fact, the human eye, for color vision, is endowed with three types of photoreceptor proteins, which produce a response as shown in the following figure.
Response of photoreceptor cells of the human retina
Each of these types configures a type of photoreceptor cell in the retina, which due to its morphology are called cones. The photoreceptor proteins are located in the cell membrane, so that when they absorb a photon they change shape, opening up channels in the cell membrane that generate a flow of ions. After a complex biochemical process, a flow of nerve impulses is produced that is preprocessed by several layers of neurons in the retina that finally reach the visual cortex through the optic nerve, where the information is finally processed.
But in this context, the point is that the retinal cells do not measure the wavelength of the photons of the stimulus. On the contrary, what they do is convert a stimulus of a certain wavelength into three parameters called L, M, S, which are the response of each of the types of photoreceptor cells to the stimulus. This has very interesting implications that need to be analyzed. In this way, we can explain aspects such as:
The reason why the rainbow has 7 colors.
The possibility of synthesizing the color by means of additive and subtractive mixing.
The existence of non-physical colors, such as white and magenta.
The existence of different ways of interpreting color according to the species.
To understand this, let us imagine that they provide us with the response of a measurement system that relates L, M, S to the wavelength and ask us to establish a correlation between them. The first thing we can see is that there are 7 different zones in the wavelength, 3 ridges and 4 valleys. 7 patterns! This explains why we perceive the rainbow composed of 7 colors, an emerging reality as a result of information processing that transcends physical reality.
But what answer will a bird give us if we ask it about the number of colors of the rainbow? Possibly, though unlikely, it will tell us nine! This is because the birds have a fourth type of photoreceptor positioned in the ultraviolet, so the perception system will establish 9 regions in the light perception band. And this leads us to ask: What will be the chromatic range perceived by our hypothetical bird, or by species that only have a single type of photoreceptor? The result is a simple case of combinatorial!
On the other hand, the existence of three types of photoreceptors in the human retina makes it possible to synthesize the chromatic range in a relatively precise way, by means of the additive combination of three colors, red, green and blue, as it is done in the video screens. In this way, it is possible to produce an L,M,S response at each point of the retina similar to that produced by a real stimulus, by means of the weighted application of a mixture of photons of red, green and blue wavelengths.
Similarly, it is possible to synthesize color by subtractive or pigmentary mixing of three colors, magenta, cyan and yellow, as in oil paint or printers. And this is where the virtuality of color is clearly shown, since there are no magenta photons, since this stimulus is a mixture of blue and red photons. The same happens with the white color, as there are no individual photons that produce this stimulus, since white is the perception of a mixture of photons distributed in the visible band, and in particular by the mixture of red, green and blue photons.
In short, the perception of color is a clear example of how reality emerges as a result of information processing. Thus, we can see how a given interpretation of the physical information of the visible electromagnetic spectrum produces an emerging reality, based a much more complex underlying reality.
In this sense, we could ask ourselves what an android with a precise wavelength measurement system would think of the images we synthesize in painting or on video screens. It would surely answer that they do not correspond to the original images, something that for us is practically imperceptible. And this connects with a subject, which may seem unrelated, as is the concept of beauty and aesthetics. The truth is that when we are not able to establish patterns or categories in the information we perceive it as noise or disorder. Something unpleasant or unsightly!
If we stick to its definition, which can be found in dictionaries, we can see that it always refers to a set of data and often adds the fact that these are sorted and processed. But we are going to see that these definitions are imprecise and even erroneous in assimilating it to the concept of knowledge.
One of the things that information theory has taught us is that any object (news, profile, image, etc.) can be expressed precisely by a set of bits. Therefore, the formal definition of information is the ordered set of symbols that represent the object and that in their basic form constitute an ordered set of bits. However, information theory itself surprisingly reveals that information has no meaning, which is technically known as “information without meaning”.
This seems to be totally contradictory, especially if we take into account the conventional idea of what is considered as information. However, this is easy to understand. Let us imagine that we find a book in which symbols appear written that are totally unknown to us. We will immediately assume that it is a text written in a language unknown to us, since, in our culture, book-shaped objects are what they usually contain. Thus, we begin to investigate and conclude that it is an unknown language without reference or Rosetta stone with any known language. Therefore, we have information but we do not know its message and as a result, the knowledge contained in the text. We can even classify the symbols that appear in the text and assign them a binary code, as we do in the digitization processes, converting the text into an ordered set of bits.
However, to know the content of the message we must analyze the information through a process that must include the keys that allow extracting the content of the message. It is exactly the same as if the message were encrypted, so the message will remain hidden if the decryption key is not available, as shown by the one-time pad encryption technique.
Ray Solomonoff, co-founder of Algorithmic Information Theory together with Andrey Kolmogorov.
What is knowledge?
This clearly shows the difference between information and knowledge. In such a way that information is the set of data (bits) that describe an object and knowledge is the result of a process applied to this information and that is materialized in reality. In fact, reality is always subject to this scheme.
For example, suppose we are told a certain story. From the sound pressure applied to our eardrums we will end up extracting the content of the news and also we will be able to experience subjective sensations, such as pleasure or sadness. There is no doubt that the original stimulus can be represented as a set of bits, considering that audio information can be a digital content, e.g. MP3.
But for knowledge to emerge, information needs to be processed. In fact, in the previous case it is necessary to involve several different processes, among which we must highlight:
Biological processes responsible for the transduction of information into nerve stimuli.
Extraction processes of linguistic information, established by the rules of language in our brain by learning.
Extraction processes of subjective information, established by cultural rules in our brain by learning.
In short, knowledge is established by means of information processing. And here the debate may arise as a consequence of the diversity of processes, of their structuring, but above all because of the nature of the ultimate source from which they emerge. Countless examples can be given. But, since doubts can surely arise that this is the way reality emerges, we can try to look for a single counterexample!
A fundamental question is: Can we measure knowledge? The answer is yes and is provided by the algorithmic information theory (AIT) which, based on information theory and computer theory, allows us to establish the complexity of an object, by means of the Kolmogorov complexity K(x), which is defined as follows:
For a finite object x, K(x) is defined as the length of the shortest effective binary description of x.
Without going into complex theoretical details, it is important to mention that K(x) is an intrinsic property of the object and not a property of the evaluation process. But don’t panic! Since, in practice, we are familiar with this idea.
Let’s imagine audio, video, or general bitstream content. We know that these can be compressed, which significantly reduces their size. This means that the complexity of these objects is not determined by the number of bits of the original sequence, but by the result of the compression since through an inverse decompression process we can recover the original content. But be careful! The effective description of the object must include the result of the compression process and the description of the decompression process, needed to retrieve the message.
Complexity of digital content, equivalent to a compression process
A similar scenario is the modeling of reality, where physical processes stand out. Thus, a model is a compact definition of a reality. For example, Newton’s universal gravitation model is the most compact definition of the behavior of a gravitational system in a non-relativistic context. In this way, the model, together with the rules of calculus and the information that defines the physical scenario, will be the most compact description of the system and constitutes what we call algorithm. It is interesting to note that this is the formal definition of algorithm and that until these mathematical concepts were developed in the first half of the 20th century by Klein, Chruch and Turing, this concept was not fully established.
Alan Turing, one of the fathers of computing
It must be considered that the physical machine that supports the process is also part of the description of the object, providing the basic functions. These are axiomatically defined and in the case of the Turing machine correspond to an extremely small number of axiomatic rules.
Structure of the models, equivalent to a decompression process
In summary, we can say that knowledge is the result of information processing. Therefore, information processing is the source of reality. But this raises the question: Since there are non-computable problems, to what depth is it possible to explore reality?
Classically, information is considered to be human-to-human transactions. However, throughout history this concept has been expanded, not so much by the development of mathematical logic but by technological development. A substantial change occurred with the arrival of the telegraph at the beginning of the 19th century. Thus, “send” went from being strictly material to a broader concept, as many anecdotes make clear. Among the most frequent highlights the intention of many people to send material things by means of telegrams, or the anger of certain customers arguing that the telegraph operator had not sent the message when he returned them the message note.
Currently, “information” is an abstract concept based on the theory of information, created by Claude Shannon in the mid-twentieth century. However, computer technology is what has contributed most to the concept of “bit” being something totally familiar. Moreover, concepts such as virtual reality, based on the processing of information, have become everyday terms.
The point is that information is ubiquitous in all natural processes, physics, biology, economics, etc., in such a way that these processes can be described by mathematical models and ultimately by information processing. This makes us wonder: What is the relationship between information and reality?
Information as a physical entity
It is evident that information emerges from physical reality, as computer technology demonstrates. The question is whether information is fundamental to physical reality or simply a product of it. In this sense, there is evidence of the strict relationship between information and energy.
Claude Elwood Shannon was a mathematician, electrical engineer and American cryptographer remembered as «the father of information theory» / Image: DobriZheglov
Thus, the Shannon-Hartley theorem of information theory establishes the minimum amount of energy required to transmit a bit, known as the Bekenstein bound. In a different way and in order to determine the energy consumption in the computation process, Rolf Landauer established the minimum amount of energy needed to erase a bit, a result known as Landauer principle, and its value exactly coincides with the Bekenstein bound, which is a function of the absolute temperature of the medium.
These results allow determining the maximum capacity of a communication channel and the minimum energy required by a computer to perform a given task. In both cases, the inefficiency of current systems is evidenced, whose performance is extremely far from theoretical limits. But in this context, the really important thing is that Shannon-Hartley’s theorem is a strictly mathematical development, in which the information is finally coded on physical variables, leading us to think that information is something fundamental in what we define as reality.
Both cases show the relationship between energy and information, but are not conclusive in determining the nature of information. What is clear is that for a bit to emerge and be observed on the scale of classical physics requires a minimum amount of energy determined by the Bekenstein bound. So, the observation of information is something related to the absolute temperature of the environment.
This behavior is fundamental in the process of observation, as it becomes evident in the experimentation of physical phenomena. A representative example is the measurement of the microwave background radiation produced by the big bang, which requires that the detector located in the satellite be cooled by liquid helium. The same is true for night vision sensors, which must be cooled by a Peltier cell. On the contrary, this is not necessary in a conventional camera since the radiation emitted by the scene is much higher than the thermal noise level of the image sensor.
This proofs that information emerges from physical reality. But we can go further, as information is the basis for describing natural processes. Therefore, something that cannot be observed cannot be described. In short, every observable is based on information, something that is clearly evident in the mechanisms of perception.
From the emerging information it is possible to establish mathematical models that hide the underlying reality, suggesting a functional structure in irreducible layers. A paradigmatic example is the theory of electromagnetism, which accurately describes electromagnetism without relying itself on the photon’s existence, and the existence of photos cannot be inferred from it. Something that is generally extendable to all physical models.
Another indication that information is a fundamental entity of what we call reality is the impossibility of transferring informationfaster than light. This would make reality a non-causal and inconsistent system. Therefore, from this point of view information is subject to the same physical laws as energy. And considering a behavior such as particle entanglement, we can ask: How does information flow at the quantum level?
Is information the essence of reality?
Based on these clues, we could hypothesize that information is the essence of reality in each of the functional layers in which it is manifested. Thus, for example, if we think of space-time, its observation is always indirect through the properties of matter-energy, so we could consider it to be nothing more than the emergent information of a more complex underlying reality. This gives an idea of why the vacuum remains one of the great enigmas of physics. This kind of argument leads us to ask: What is it and what do we mean by reality?
Space-Time perception
From this perspective, we can ask what conclusions we could reach if we analyze what we define as reality from the point of view of information theory and, in particular, from the algorithmic information theory and the theory of computability. All this without losing sight of the knowledge provided by the different areas that study reality, especially physics.
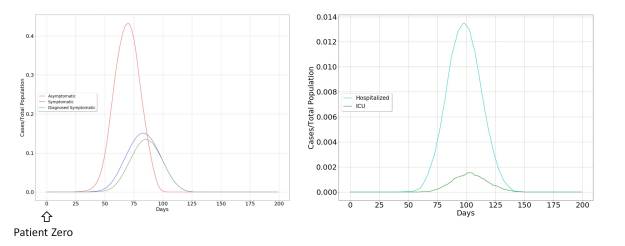
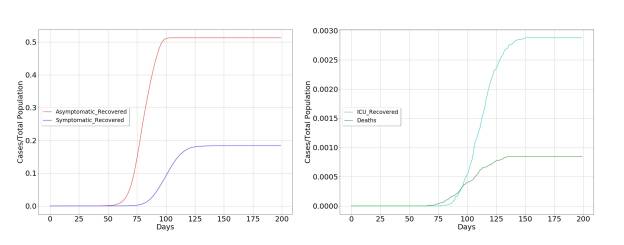
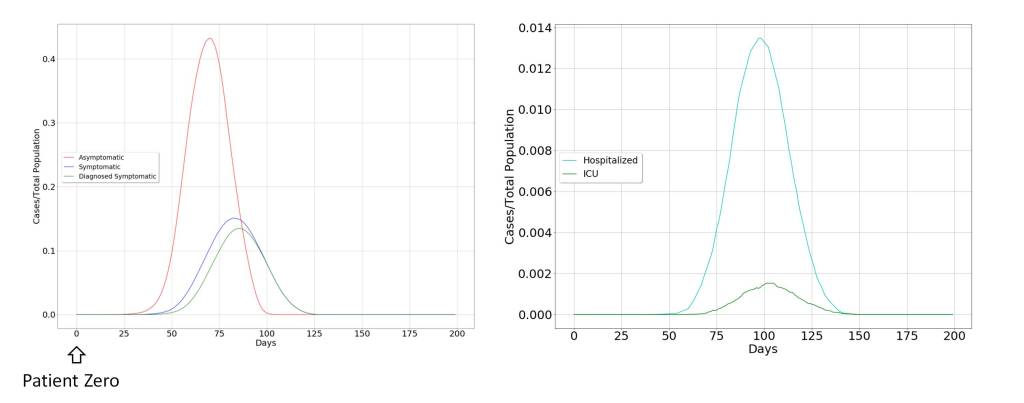
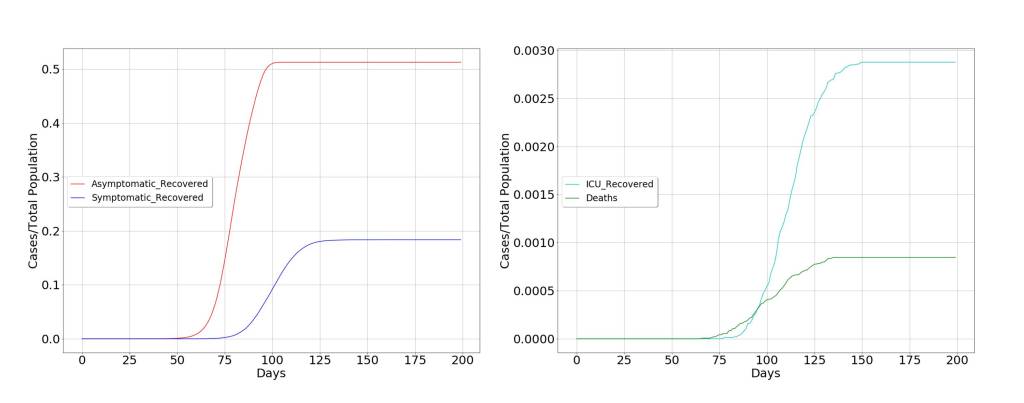
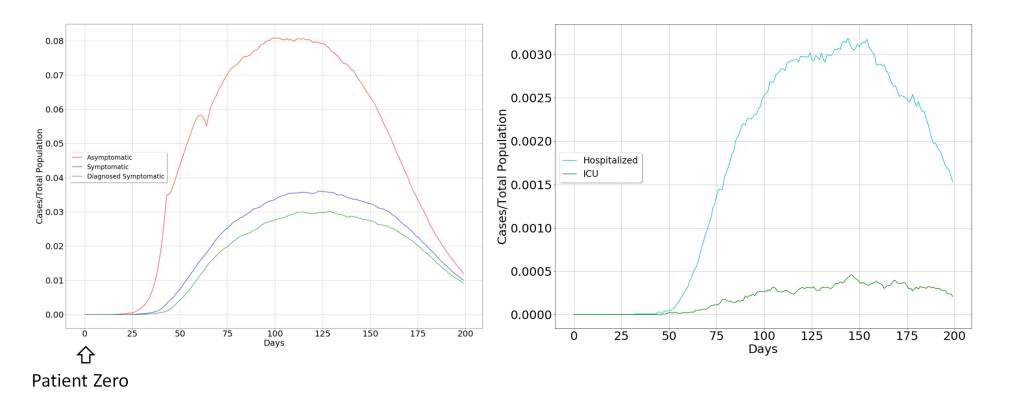
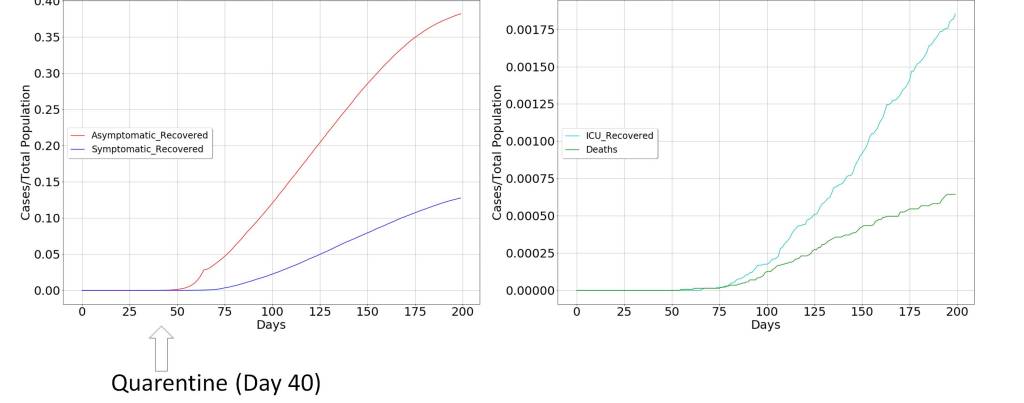
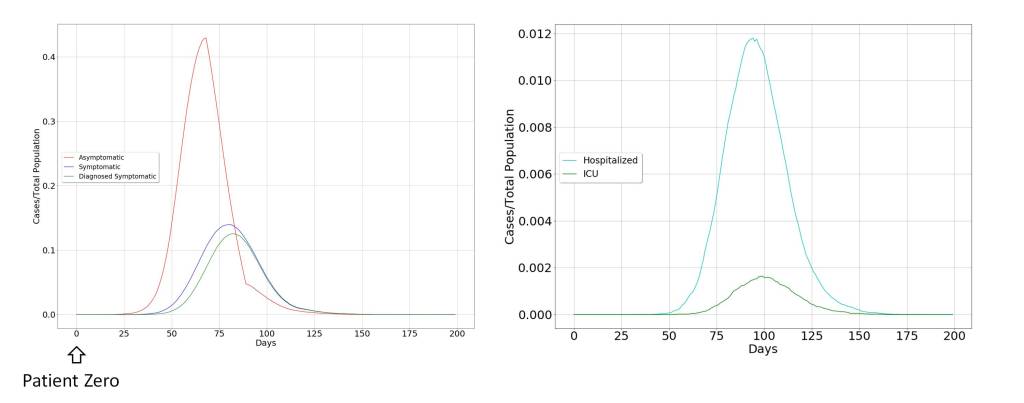
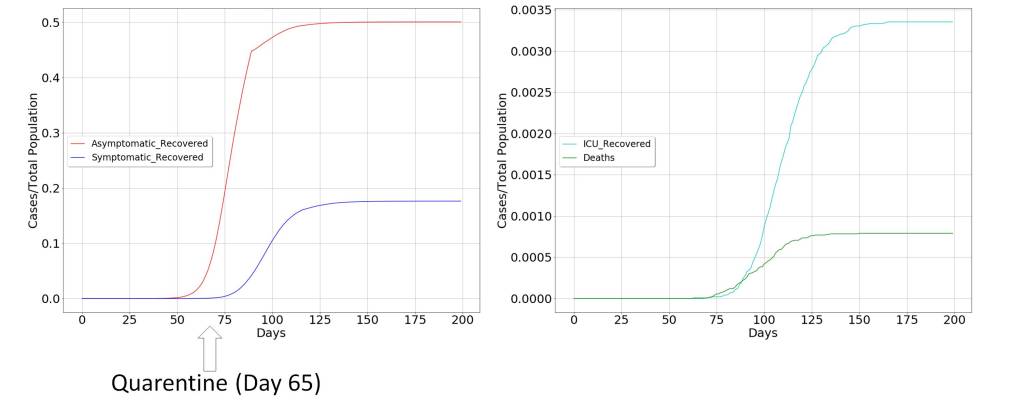


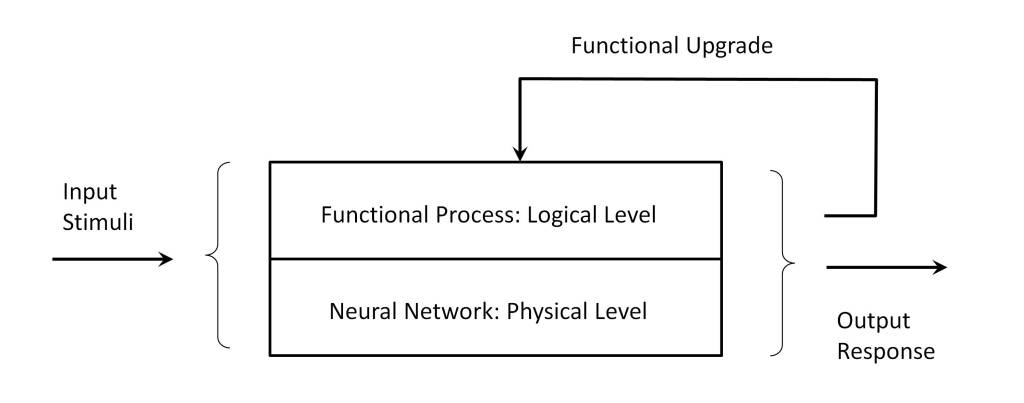
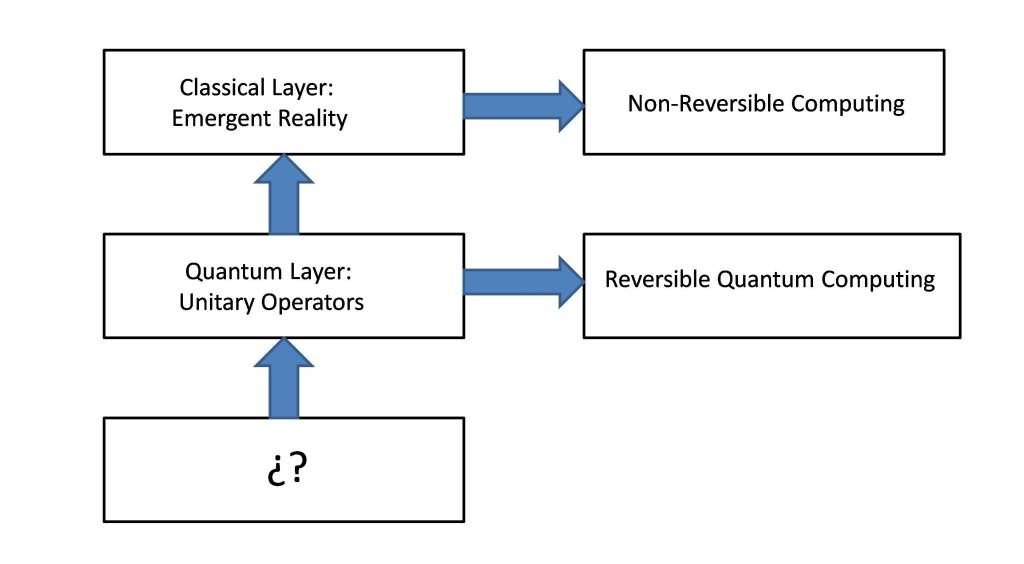


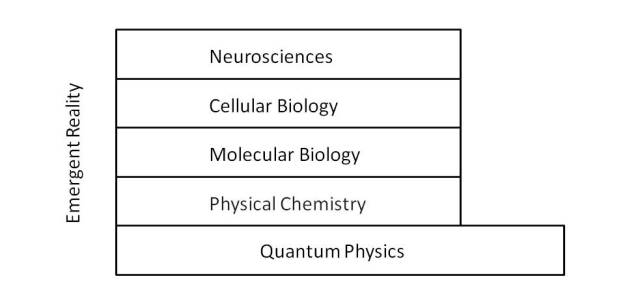
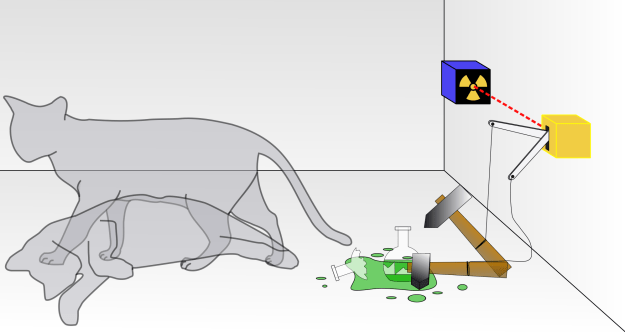

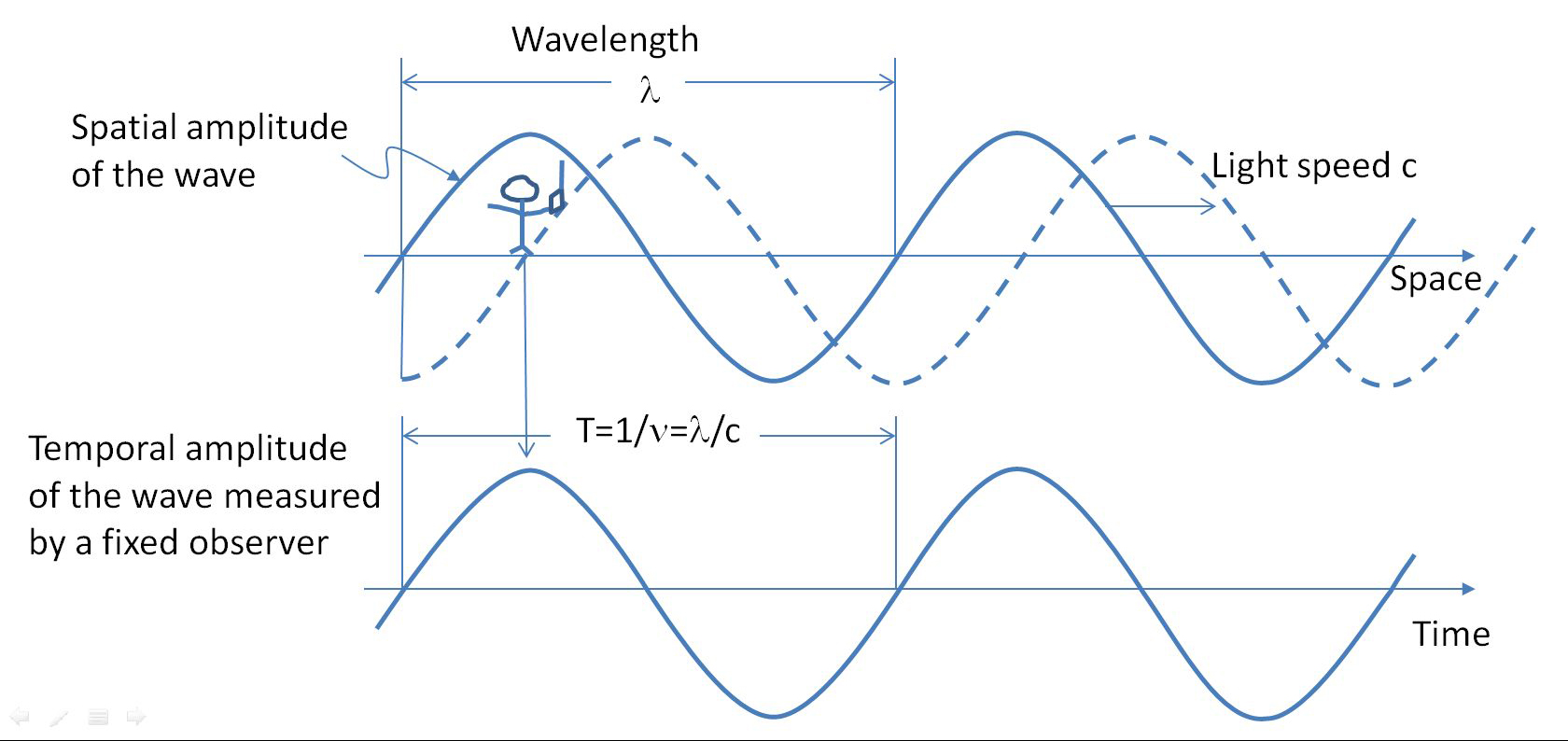


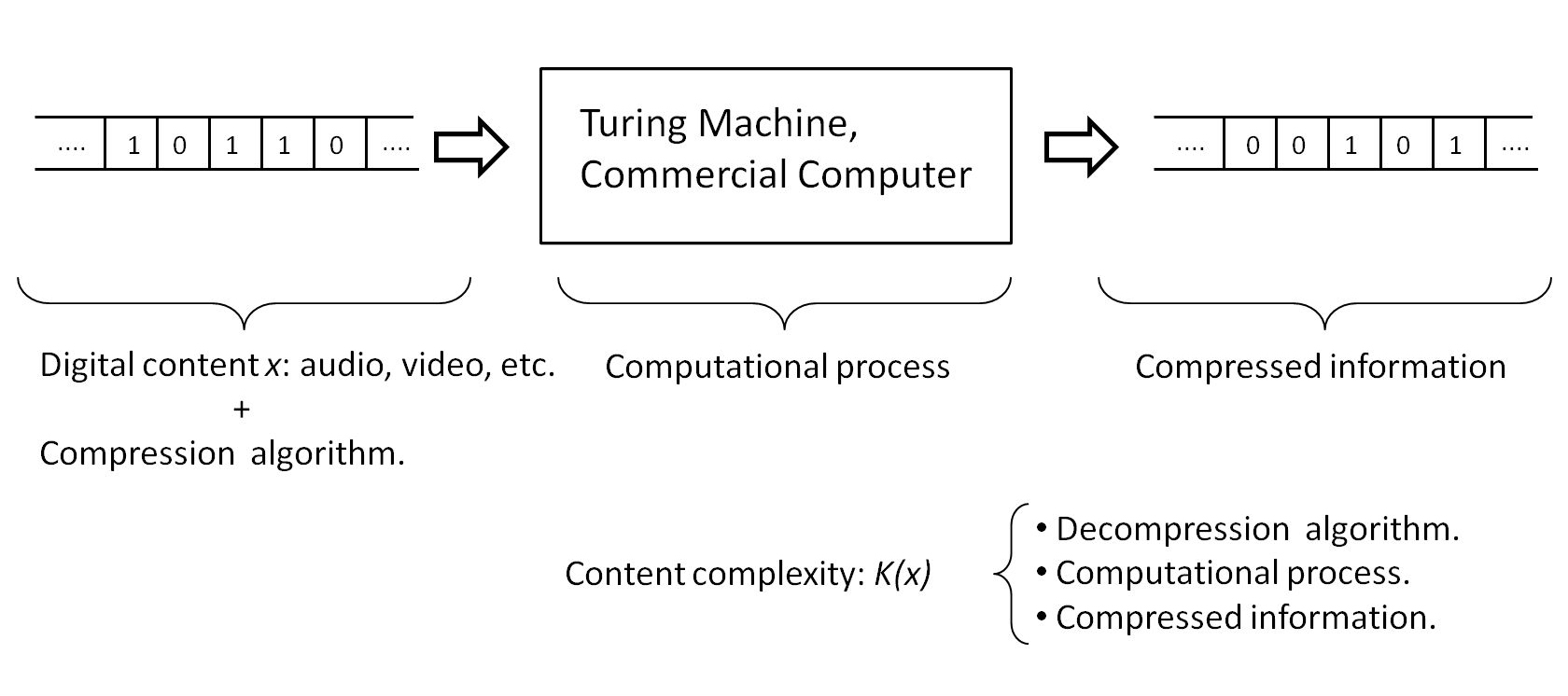

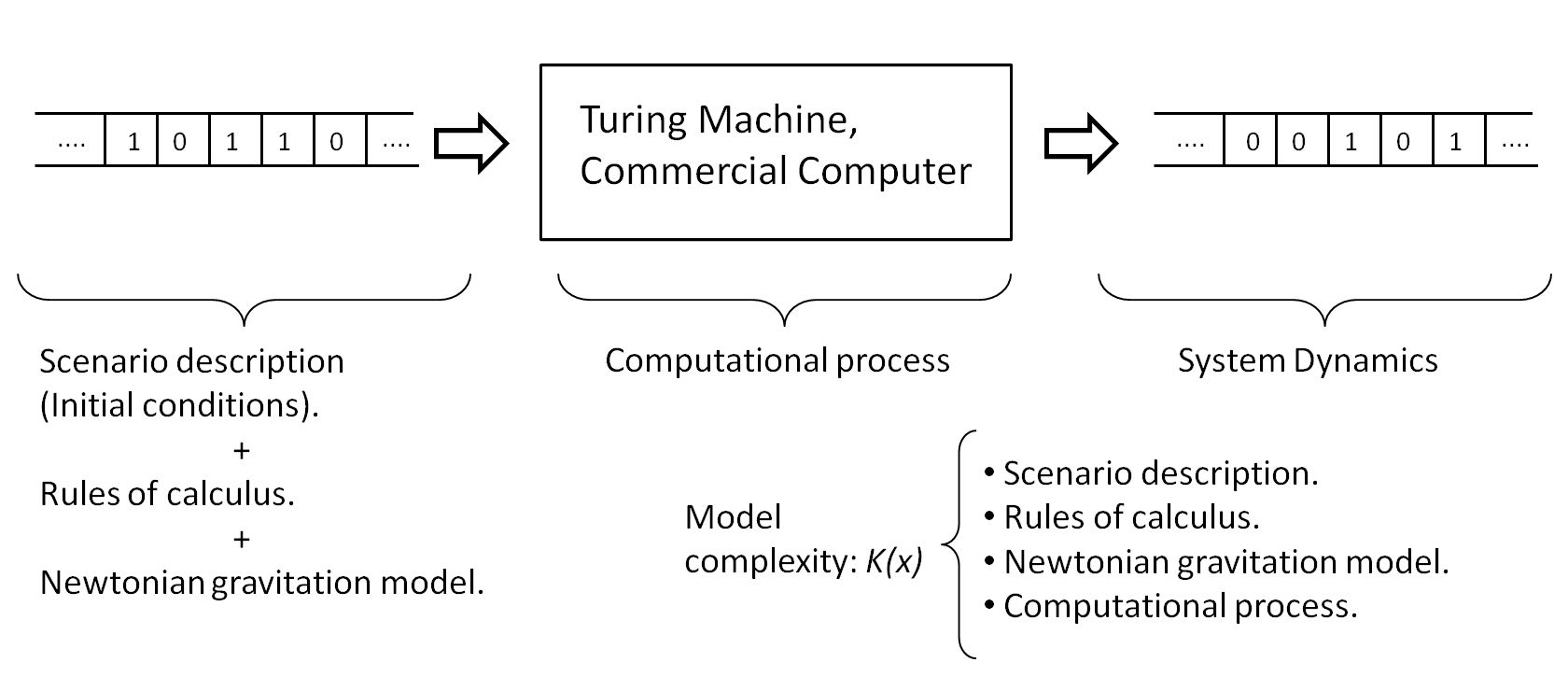

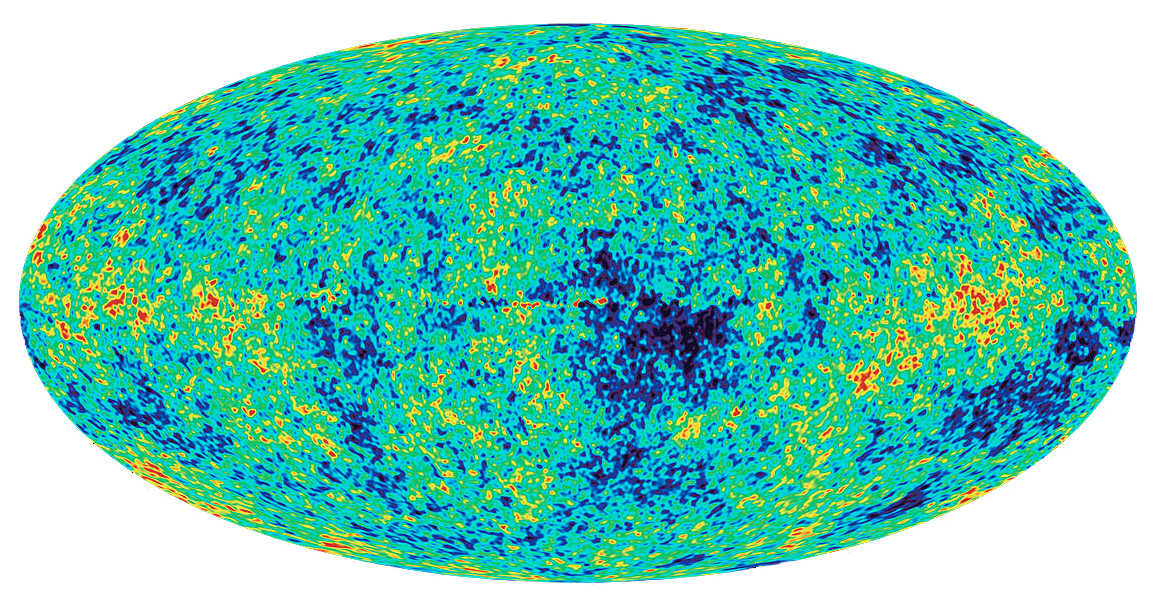


{kind=link}