Since the establishment of the principles of relativity, the problem arose of determining the transformations that would allow the expression of thermodynamic parameters in the relativistic context, such as entropy, temperature, pressure or heat transfer; in a analogous way to that achieved in the context of mechanics, such as space-time and momentum.
The first efforts in this field were made by Planck [1] and Einstein [2], arriving at the expressions:
S’ = S, T’ = T/γ, p = p’, γ = (1 – (v/c)2) -1/2
Where S, T, p are the entropy, temperature and pressure of the inertial thermodynamic system at rest I, and S’, T’, p’ are the entropy, temperature and pressure observed from the inertial system I’ in motion, with velocity v.
But in the 1960s this conception of relativistic thermodynamics was revised, and two different points of view were put forward. On the one hand, Ott [3] and Arzeliès [4] propose that the observed temperature of a body in motion must be T’ = Tγ. Subsequently, Landsberg [5] proposes that the observed temperature has be T’ = T.
All these cases are based on purely thermodynamic arguments of energy transfer by heat and work, such that ∆E = ∆Q + ∆W. However, van Kampen [6] and later Israel [7] analyze the problem from a relativistic point of view, such that ∆G = ∆Q + ∆W , where ∆G is the increment of the energy-momentum vector, ∆Q and ∆W are the four-component vectors corresponding to the irreversible and reversible part of the thermodynamic process, with ∆Q being the time component of ∆Q .
Thus, the van Kampen-Israel model can be considered the basis for the development of thermodynamics in a relativistic context, offering the advantage that it does not require the concepts of heat and energy, the laws of thermodynamics being expressed in terms of the relativistic concept of momentum-energy.
In spite of this, there is no theoretical justification based on any of the models that allows to determine conclusively the relation of temperatures corresponding to the thermodynamic system at rest and the one observed in the system in motion, so that the controversy raised by the different models is still unresolved today.
To complicate the situation further, the experimental determination of the observed temperature poses a challenge of enormous difficulty. The problem is that the observer must move in the thermal bath located in the inertial system at rest. To find out the observed temperature from the moving reference system Landsberg proposed a thought experiment and thus determine the relativistic transformation of the temperature experimentally. As a result of this proposal, he recognized that the measurement scenario may be unfeasible in practice.
In recent years, algorithms and computational capabilities have made it possible to propose numerical solutions aimed at resolving the controversy over relativistic transformations for a thermodynamic system. As a result, it is concluded that any of the temperature relations proposed by the different models can be true, depending on the thermodynamic assumptions used in the simulation [8] [9], so the resolution of the problem remains open.
The relativistic thermodynamic scenario
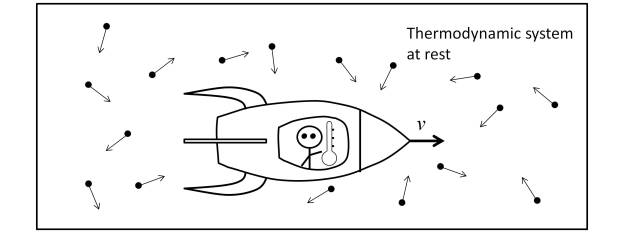
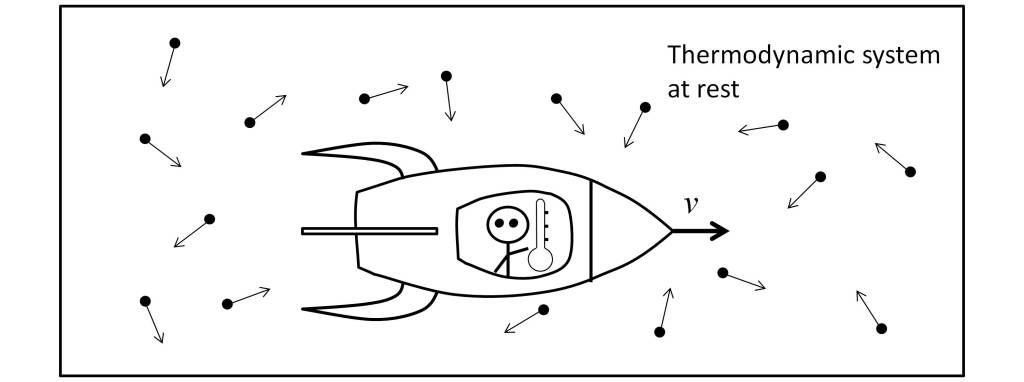
In order to highlight the difficulty inherent in the measurement of the thermodynamic body temperature of the inertial system at rest I from the inertial system I’ it is necessary to analyze the measurement scenario.
Thus, as Landsberg and Johns [10] make clear, the determination of the temperature transformation must be made by means of a thermometer attached to the observer by means of a brief interaction with the black body under measurement. To ensure that there is no energy loss, the observer must move within the thermodynamic system under measurement, as shown in the figure below.
This scenario, which may seem bizarre and may not be realizable in practice, clearly shows the essence of thermodynamic relativity. But it should not be confused with the scenario of temperature measurement in a cosmological scenario, in which the observer does not move inside the object under measurement.
Thus, in the case of the measurement of the surface temperature of a star the observer does not move within the thermodynamic context of the star, so that the temperature may be determined using Wien’s law, which relates the wavelength of the emission maximum of a black body and its temperature T, such that T = b/λmax, where b is a constant (b≅2.9*10-3 m K).
The redshift or blueshift produced by the Doppler effect, a consequence of the relative velocity of the reference systems of the star and the observer.
The redshift produced by the expansion of the universe and which is a function of the scales of space at the time of emission and observation of the photon.
The redshift produced by the gravitational effect of the mass of the star.
As an example, the following figure shows the concept of the redshift produced by the expansion of the universe.
Entropy is a relativistic invariant
Although the problem concerning the determination of the observed temperature in relativistic systems I and I’ remains open, it follows from the models proposed by Planck, Ott and Landsberg that the entropy is a relativistic invariant.
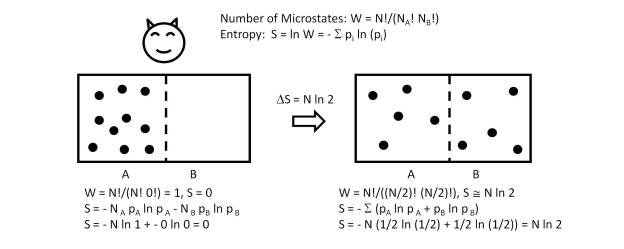
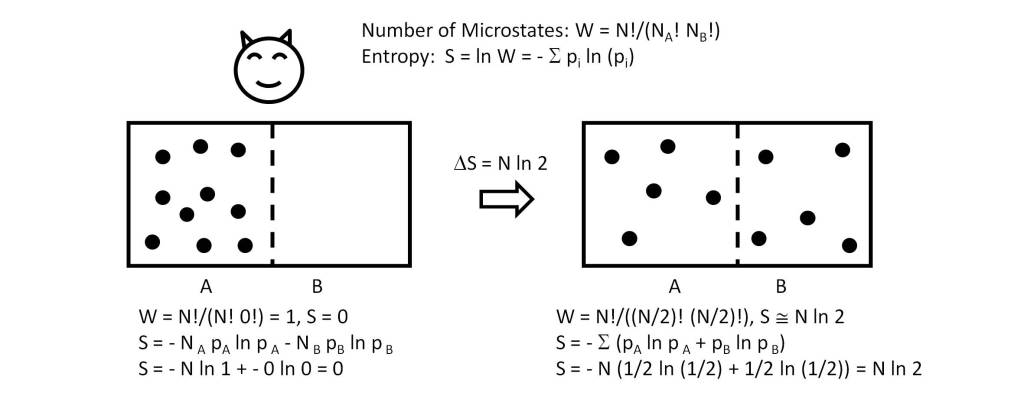
This conclusion follows from the fact that the number of microstates in the two systems is identical, so that according to the expression of the entropy S = k ln(Ω), where k is the Boltzmann constant and Ω is the number of microstates, it follows that S = S’, since Ω = Ω’.
The invariance of entropy in the relativistic context is of great significance, since it means that the amount of information needed to describe any scenario of reality that emerges from quantum reality is an invariant, independently of the observer.
In the post ’an interpretation of the collapse of the wave function‘ it was concluded that a quantum system is reversible and therefore its entropy is constant and, consequently, the amount of information for its description is an invariant. This post also highlights the entropy increase of classical systems, which is deduced from the ‘Pauli’s Master Equation’ [11], such that Ṡ > 0. This means that the information to describe the system grows systematically.
The conclusion drawn from the analysis of relativistic thermodynamics is that the entropy of a classical system is the same regardless of the observer and, therefore, the information needed to describe the system is also independent of the observer.
Obviously, the entropy increment of a classical system and how the information increment of the system emerges from quantum reality remains a mystery. However, the fact that the amount of information needed to describe a system is an invariant independent of the observer suggests that information is a fundamental physical entity at this level of reality.
On the other hand, the description of a system at any level of reality requires information in a magnitude that according to Algorithmic Information Theory is the entropy of the system. Therefore, reality and information are two entities intimately united from a logical point of view.
In short, from both the physical and the logical point of view, information is a fundamental entity. However, the axiomatic structure that configures the functionality from which the natural laws emerge, which determines how information is processed, remains a mystery.
[1]
M. Planck, « Zur dynamik bewegter systeme,» Ann. Phys. , vol. 26, 1908.
[2]
A. Einstein, «Über das Relativitätsprinzip und die aus demselben gezogenen Folgerungen.,» Jahrb. Radioakt. Elektron., vol. 4, pp. 411-462, 1907.
[3]
H. Ott, «Lorentz-Transformation der Wiirme und der Temperatur,» Zeitschrift Für Physik, vol. 175, pp. 70-104, 1963.
[4]
H. Arzeliès, «Transformation relativiste de la temperature et de quelques autres grandeurs thermodynamiques.,» Nuovo Cim. 35, 792 (1965)., vol. 35, nº 3, pp. 792-804, 1965.
[5]
P. Landsberg, «Special relativistic thermodynamics,» Proc. Phys. Soc., vol. 89, pp. 1007-1016, 1966.
[6]
N. G. van Kampen, «Relativistic Thermodynamics of Moving Systems,» Phys. Rev. 173, 295 (1968)., vol. 173, pp. 295-301, 1968.
[7]
W. Israel, «Nonstationary Irreversible Thermodynamics: A Causal Relativistic Theory,» Ann. Phys., vol. 106, pp. 310- 331, 1976.
[8]
D. Cubero, J. Casado-Pascual, J. Dunkel, P. Talkner y P. Hänggi, «Thermal Equilibrium and Statistical Thermometers in Special Relativity.,» Relativity. Phys. Rev. Lett. , vol. 99, pp. 170601, 1-4, 2007.
[9]
R. Manfred, «Thermodynamics meets Special Relativity–or what is real in Physics?,» arXiv: 0801.2639., nº 2008.
[10]
P. T. Landsberg y K. A. Johns, «The Problem of Moving Thermometers,» Proc. R. Soc. Lond., vol. 306, pp. 477-486, 1968.
[11]
F. Schwabl, Statistical Mechanics, pp. 491-494, Springer, 2006.
Undoubtedly, the concept of time is possibly one of the greatest mysteries of nature. The nature of time has always been a subject of debate both from the point of view of philosophy and physics. But this has taken on special relevance as a consequence of the development of the theory of relativity, which has marked a turning point in the perception of space-time.
Throughout history, different philosophical theories have been put forward on the nature of time [1], although it has been from the twentieth century onwards when the greatest development has taken place, mainly due to advances in physics. Thus, it is worth mentioning the argument against the reality of time put forward by McTaggart [2], such that time does not exist and that the perception of a temporal order is simply an appearance, which has had a great influence on philosophical thought.
However, McTaggart’s argument is based on the ordering of events, as we perceive them. From this idea, several philosophical theories have been developed, such as A-theory, B-theory, C-theory and D-theory [3]. However, this philosophical development is based on abstract reasoning, without relying on the knowledge provided by physical models, which raises questions of an ontological nature.
Thus, both relativity theory and quantum theory show that the emergent reality is an observable reality, which means that in the case of space-time both spatial and temporal coordinates are observable parameters, emerging from an underlying reality. In the case of time this raises the question: Does the fact that something is past, present or future imply that it is something real? Consequently, how does the reality shown by physics connect with the philosophical thesis?
If we focus on an analysis based on physical knowledge, there are two fundamental aspects in the conception of time. The first and most obvious is the perception of the passage of time, on which the idea of past, present and future is based, which Arthur Eddington defined as the arrow of time [4], which highlights its irreversibility. The second aspect is what Carlo Rovelli [5] defines as “loss of unity” and refers to space-time relativity, which makes the concept of past, present and future an arbitrary concept, based on the perception of physical events.
But, in addition to using physical criteria in the analysis of the nature of time, it seems necessary to analyze it from the point of view of information theory [6], which allows an abstract approach to overcome the limitations derived from the secrets locked in the underlying reality. This is possible since any element of reality must have an abstract representation, i.e. by information, otherwise it cannot be perceived by any means, be it sensory organ or measuring device, so it will not be an element of reality.
The topology of time
From the Newtonian point of view, the dynamics of classical systems develops in the context of space-time of four dimensions, three spatial dimensions (x,y,z) and one temporal dimension (t), so that the state of the system can be expressed as a function of the generalized coordinates q and the generalized moments p as a function f(q,p,t), where q and p are tuples (ordered lists of coordinates and moments) that determine the state of each of the elements that compose the system.
Thus, for a system of point particles, the state of each particle is determined by the coordinates of its position q = (x,y,z) and of its momentum p = (mẋ, mẏ, mż). This representation is very convenient, since it allows the analysis of the systems by calculating continuous time functions. However, this view can lead to a wrong interpretation since identifying time as a mathematical variable makes it conceived as a reversible variable. This becomes clear if the dynamics of the system is represented as a sequence of states, which according to quantum theory has a discrete nature [7] and can be expressed in terms of a classical system (CS) as:
According to this representation, we define the past as the sequence {… Si-2(qi-2,pi-2), Si-1(qi-1,pi+-)}, the future as the sequence {Si+1(qi+1,pi+1), Si+2(qi+2,pi+2),…} and the present as the state Si(qi,pi). The question that arises is: Do the sequences {… Si-3(qi-3,pi-3), Si-2(qi-2,pi-2), Si-1(qi-1,pi+-)} y {Si+1(qi+1,pi+1), Si+2(qi+2,pi+2), Si+3(qi+3,pi+3),…} have real existence? Or on the contrary: Are they the product of the perception of the emergent reality?
In the case of a quantum system its state is represented by its wave function Ψ(q), which is a superposition of the wave functions that compose the system:
Ψ(q,t) = Ψ(q1,t) ⊗ Ψ(q1,t) …⊗ Ψ(qi,t) …⊗ Ψ(qn,t)
Thus, the dynamics of the system can be expressed as a discrete sequence of states:
As in the case of the classical system Ψi(q) would represent the present state, while {… Ψi-2(q), ΨYi-1(q)} represents the past and {Ψi+1(q), Ψi+2(q), …} the future, although as will be discussed later this interpretation is questionable.
However, it is essential to emphasize that the sequences of the classical system CS and the quantum system QS have, from the point of view of information theory, a characteristic that makes that their nature, and therefore their interpretation, must be different. Thus, quantum systems have a reversible nature, since their dynamics is determined by unitary transformations [8], so that all the states of the sequence contain the same amount of information. In other words, their entropy remains constant throughout the sequence:
H(Ψi(q i)) = H(Ψi(q i+1)).
In contrast, classical systems are irreversible [9], so the amount of information of the sequence states grows systematically, such that:
H(Si(qi,pi)) < H(Si+1(qi+1,pi+1)).
Concerning the entropy increase of classical systems, the post “An interpretation of the collapse of the wave function” has dealt with the nature of entropy growth from the “Pauli’s Master Equation” [10], which demonstrates that quantum reality is a source of emergent information towards classical reality. However, this demonstration is abstract in nature and provides no clues as to how this occurs physically, so it remains a mystery. Obviously, the entropy growth of classical systems assumes that there must be a source of information and, as has been justified, this source is quantum reality.
This makes the states of the classical system sequence distinguishable, establishing a directional order. On the contrary, the states of the quantum system are not distinguishable, since they all contain the same information because quantum theory has a reversible nature. And here we must make a crucial point, linked to the process of observation of quantum states, which may lead us to think that this interpretation is not correct. Thus, the classical states emerge as a consequence of the interaction of the quantum components of the system, which may lead to the conclusion that the quantum states are distinguishable, but the truth is that the states that are distinguishable are the emerging classical states.
According to this reasoning the following logical conclusion can be drawn. Time is a property that emerges from quantum reality as a consequence of the fact that the classical states of the system are distinguishable, establishing in addition what has been called the arrow of time, in such a way that the sequence of states has a distinguishable characteristic such as the entropy of the system.
This also makes it possible to hypothesize that time only has an observable existence at the classical level, while at the quantum level the dynamics of the system would not be subject to the concept of time, and would therefore be determined by means of other mechanisms. In principle this may seem contradictory, since according to the formulation of quantum mechanics the time variable appears explicitly. In reality this would be nothing more than a mathematical contraption that allows expressing a quantum model at the boundary that separates the quantum system and the classical system and thus describe the classical reality from the quantum mathematical model. In this sense it should be considered that the quantum model is nothing more than a mathematical model of the emerging reality that arises from an underlying nature, which for the moment is unknown and which tries to be interpreted by new models, such as string theory.
An argument that can support this idea is also found in the theory of loop quantum gravitation (LQG) [11], which is defined as a substrate-independent theory, meaning that it is not embedded in a space-time structure, and which posits that space and time emerge at distances about 10 times the Planck length [12].
The arrow of time
When analyzing the sequences of states CS and QS we have alluded to the past, present and future, which would be an emergent concept determined by the evolution of the entropy of the system. This seems clear in classical reality. But as reasoned, the sequence of quantum states is indistinguishable, so it would not be possible to establish the concept of past, present and future.
A fundamental aspect that must be overcome is the influence of the Newtonian view of the interpretation of time. Thus, in the fundamental equation of dynamics:
F = m d2x/dt2
the variable time is squared, this indicates that the equation does not distinguish t from -t, i.e., it is the same backward or forward in time, so that the dynamics of the system is reversible. This at the time led to Laplace’s causal determinism, which remained in force until the development of statistical mechanics and Boltzmann’s interpretation of the concept of entropy. To this we must add that throughout the twentieth century scientific development has led without any doubt to the conclusion that physics cannot be completely deterministic, both classical physics and quantum physics [13].
Therefore, it can be said that the development of calculus and the use of the continuous variable time (t) in the determination of dynamical processes has been fundamental and very fruitful for the development of physics. However, it must be concluded that this can be considered a mathematical contraption that does not reflect the true nature of time. Thus, when a trajectory is represented on coordinate axes, the sensation is created that time can be reversed at will, which would be justified by the reversibility of the processes.
However, classical processes are always subject to thermodynamic constraints, which make these processes irreversible, which mean that for an isolated system its state evolves in such a way that its entropy grows steadily and therefore the quantity and information describing the system, so that a future state cannot be reverted to a past state. Consequently, if the state of the system is represented as a function of time, it could be thought that the time variable could be reverted as if a cursor were moved on the time axis, which does not seem to have physical reality, since the growth of entropy is not compatible with this operation.
To further emphasize the idea of the possibility of moving in time as if it were an axis or a cursor, we can consider the evolution of a reversible system, which can reach a certain state Si and continue to evolve, and after a certain moment it can reach the state Si again. But this does not mean that time has been reversed, but rather that time always evolves in the direction of the dynamics of the system and the only thing that happens is that the state of the system can return to a past state in a reversible way. However, in classical systems this is only a hypothetical proposal, since reversible systems are ideal systems free of thermodynamic behavior, such as gravitational, electromagnetic and frictionless mechanical systems. To say, ideal models that do not interact with an underlying reality.
In short, the state of a system is a sequence determined by an index that grows systematically. Therefore, the idea of a time axis, although it allows us to visualize and treat systems intuitively, should be something we should discard, since it leads us to a misconception of the nature of time. Therefore, time is not a free variable, but the perception of a sequence of states.
Returning to the concept of past, present and future, it can be assured that according to information theory, the state of present is supported by the state Si(qi,pi), and therefore is part of the classical reality. As for the sequence of past states {… Si-3(qi-3,pi-3), Si-2(qi-2,pi-2), Si-1(qi-1,pi-1)} to be a classical reality would require that these states continue to exist physically, something totally impossible since it would require an increase of information in the system that is not in accordance with the increase of its entropy, so this concept is also purely perceptual. On the other hand, if this were possible the system would be reversible.
In the case of the future sequence of states {Si+1(qi+1,pi+1), Si+2(qi+2,pi+2),…} it is a classical reality for occurring with a degree of uncertainty that makes it not predictable. Even supposing this were possible, the states of the present would have to increase the amount of information to hold accurate forecasts of the future, which would increase their entropy, which is at disagreement with observable reality. Therefore, the concept of the future is not a classical reality, being a purely perceptual concept. In short, it can be concluded that the only concept of classical reality is the state of the present.
The relativistic context
Consequently, classical systems offer a vision of reality as a continuous sequence of states, while quantum physics modifies it, establishing that the dynamics of systems is a discrete sequence of states. However, the classical view is no more than an appearance at the macroscopic level. However, the theory of relativity [14] modifies the classical view, such that the description of a system is a sequence of events. If to this we add the quantum view, the description of the system is a discrete sequence of events.
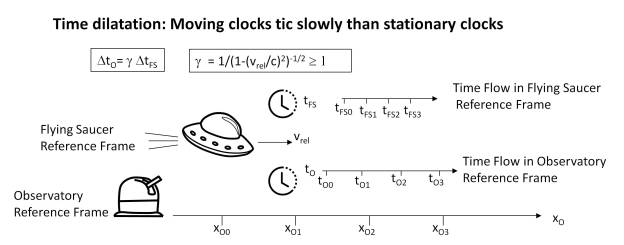
But in addition, the theory of relativity offers a perspective in which the perception of time depends on the reference system and therefore on the observer. Thus, as the following figure shows, clocks in motion are slower than stationary clocks, so that we can no longer speak of a single time sequence, but that it depends on the observer.
However, this does not modify the hypothesis put forward, which is to consider time as the perception of a sequence of states or events. This reinforces the idea that time emerges from an underlying reality and that its perception varies according to how it is observed. Thus, each observer has an independent view of time, determined by a sequence of events.
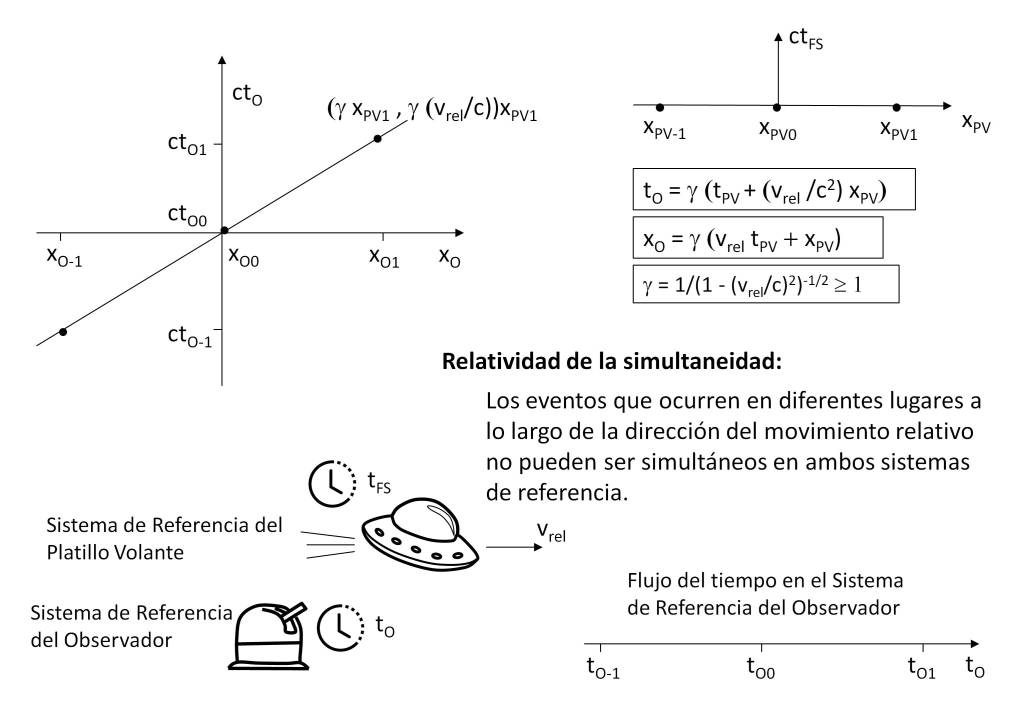
In addition to the relative perception of time, the theory of relativity has deeper implications, since it establishes a link between space and time, such that the relativistic interval
is invariant and therefore takes the same value in any reference frame.
As a consequence, both the perception of time and space depends on the observer and as the following figure shows, simultaneous events in one reference frame are observed as events occurring at different instants of time in another reference frame, so that in this one they are not simultaneous, giving rise to the concept of relativity of simultaneity.
In spite of this behavior, the view of time as the perception of a sequence of events is not modified, since although the sequences of events in each reference system are correlated, in each reference system there is a sequence of events that will be interpreted as the flow of time corresponding to each observer.
The above arguments are valid for inertial reference frames, i.e. free of acceleration. However, the theory of general relativity [15], based on the principles of covariance and equivalence, establishes the metric of the deformation of space-time in the presence of matter-energy and how this deformation acts as a gravitational field. These principles are defined as:
The Covariance Principle states that the laws of physics must take the same form in all reference frames.
The Equivalence Principle states that a system subjected to a gravitational field is indistinguishable from a non-inertial reference frame (subjected to acceleration).
It should be noted that, although the equivalence principle was fundamental in the development of general relativity, it is not a fundamental ingredient, and is not verified in the presence of electromagnetic fields.
It follows from the theory of general relativity that acceleration bends space-time, paradigmatic examples being the gravitational redshift of photons escaping from the gravitational field, or gravitational lenses. For this reason, it is essential to analyze the concept of time perception from the point of view of this perspective.
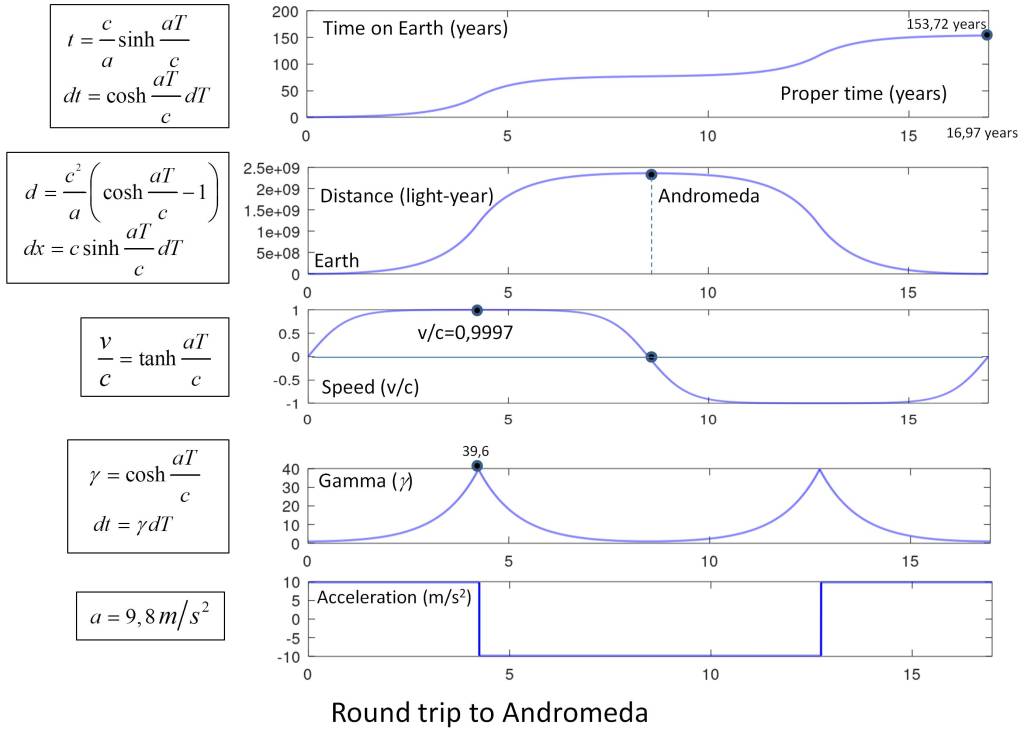
Thus, the following figure shows a round trip to Andromeda by a spacecraft propelled with acceleration a = g. It shows the time course in the Earth reference frame t and the proper time in the spacecraft reference frame T, such that the time course on Earth is slower than in the spacecraft by a value determined by g. The fact that the time course is produced by the velocity of the spacecraft in an inertial system or by the acceleration of the spacecraft does not modify the reasoning used throughout the test, since the time course is determined exclusively in each of the reference systems by the sequence of events observed in each of them independently.
Therefore, it can be concluded that the perception of time is produced by the sequence of events occurring in the observing reference system. To avoid possible anthropic interpretations, an entity endowed with the ability to detect events and to develop artificial intelligence (AI) algorithms can be proposed as an observer. As a consequence, it can be concluded that the entity will develop a concept of time based on the sequence of events. Evidently, the developed concept will not be reversible, since this sequence is organized by an index.
However, if the event detection mechanisms were not sufficiently accurate, the entity could deduce that the dynamics of the process could be cyclic and therefore reversible. However, the sequence of events is ordered and will therefore be interpreted as flowing in a single direction.
Thus, identical entities located in different reference systems will perceive a different sequence of events of the dynamics, determined by the laws of relativity. But the underlying reality sets a mark on each of the events that is defined as physical time, and to which the observing entities are inexorably subject in their real time clocks. Therefore, the question that remains to be answered is what the nature of this behavior is.
Physical time
So far, the term perception has been used to sidestep this issue. But it is clear that although real time clocks run at different rates in different reference systems, all clocks are perfectly synchronized. But for this to be possible a total connection of the universe in its underlying reality is necessary. This must be so, since the clocks located in the different reference systems run synchronously, regardless of their location, even though they run at different speeds.
Thus, in the example of the trip to Andromeda, when the ship returns to Earth, the elapsed time of the trip in the Earth’s reference system is T = 153.72 years, while in the ship’s clock it is t = 16.92 years, but both clocks are synchronized by the parameter g, so that they run according to the expression dt = γdT. The question arises: What indications are there that the underlying reality of the universe is a fully connected structure?
There are several physical clues arising from relativistic and quantum physics, such as space-time in the photon reference frame and quantum particle entanglement. Thus, in the case of the photon γ→∞, so that any interval of time and space in the direction of motion in the reference frame of the observer tends to zero in the reference frame of the photon. If we further consider that the state of the photon is a superposition of states in any direction, the universe for a photon is a singular point without space-time dimensions. This suggests that space-time arises from an underlying reality from which time emerges as a completely cosmologically synchronized reality.
In the context of quantum physics, particle entanglement provides another clue to the interconnections in the structure on which classical reality is based. Thus, the measurement of two entangled particles implies the exchange of quantum information between them independently of their position in space and instantaneously, as deduced from the superposition of quantum states and which Schrödinger posed as a thought experiment in “Schrödinger’s cat” [16]. This behavior seems to contradict the impossibility of transferring information faster than the speed of light, which raised a controversy known as the EPR paradox [17], which has been resolved theoretically and experimentally [18], [19].
Therefore, at the classical scale information cannot travel faster than the speed of light. However, at the quantum scale reality behaves as if there were no space-time constraints. This indicates that space and time are realities that emerge at the classical scale but do not have a quantum reality, whereas space-time at the classical scale emerges from a quantum reality, which is unknown so far.
But perhaps the argument that most clearly supports the global interconnectedness of space-time is the Covariance Principle, which explicitly recognizes this interconnectedness by stating that the laws of physics must take the same form in all reference frames.
Finally, the question that arises is the underlying nature of space-time. In the current state of development of physics, the Standard Particle Model is available, which describes the quantum interactions between particles in the context of space-time. In this theoretical scheme, space-time is identified with the vacuum, which in quantum field theory is identified with the quantum vacuum which is the quantum state with the lowest possible energy, but this model does not seem to allow a theoretical analysis of how space-time emerges. Perhaps, the development of a model of fields that give sense to the physical reality of the vacuum and that integrates the standard model of particles will allow in the future to investigate how the space-time reality emerges from this model.
I. Reznikoff, «A class of deductive theories that cannot be deterministic: classical and quantum physics are not deterministic. URL = https://arxiv.org/abs/1203.2945v3,» 2013. [En línea].
[14]
A. Einstein, «On The Electrodynamics Of Moving Bodies,» 1905.
[15]
T. P. Cheng, Relativity, Gravitation and Cosmology, Oxford University Press, 2010.
[16]
E. Schrödinger, «The Present Situation in Quantum Mechanics. (Trans. John Trimmer),» Naturwissenschaften, vol. 23, pp. 844-849, 1935.
[17]
A. Einstein, B. Podolsky and N. Rose, “Can Quantum-Mechanical Description of Physical Reality be Considered Complete?,” Physical Review, vol. 47, pp. 777-780, 1935.
[18]
J. S. Bell, «On the Einstein Podolsky Rosen Paradox,» Physics, vol. 1, nº 3, pp. 195-290, 1964.
[19]
A. Aspect, P. Grangier and G. Roger, “Experimental Tests of Realistic Local Theories via Bell’s Theorem,” Phys. Rev. Lett., vol. 47, pp. 460-463, 1981.
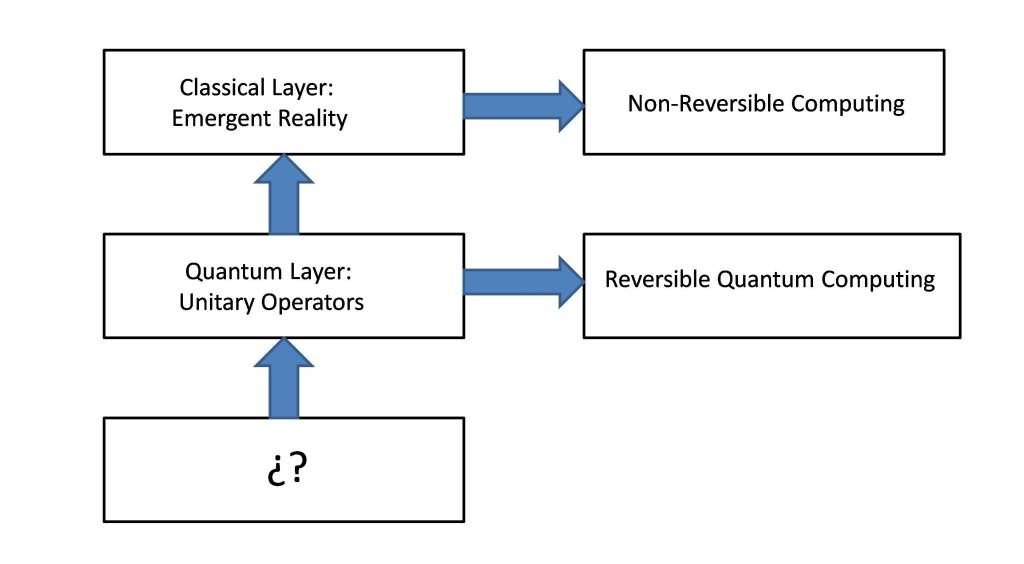
The aim of this post is to hypothesize about the collapse of the wave function based on thermodynamic entropy and computational reversibility. This will be done using arguments based on statistical mechanics, both quantum and classical, and on the theory of computation and the information theory.
In this sense, it is interesting to note that most of the natural processes have a reversible behavior, among which we must highlight the models of gravitation, electromagnetism and quantum physics. In particular, the latter is the basis for all the models of the emerging reality that configure the classical reality (macroscopic reality).
On the contrary, thermodynamic processes have an irreversible behavior, which contrasts with the previous models and poses a contradiction originally proposed by Loschmidt, since they are based on quantum physics, which has a reversible nature. It should also be emphasized that thermodynamic processes are essential to understand the nature of classical reality, since they are present in all macroscopic interactions.
This raises the following question. If the universe as a quantum entity is a reversible system, how is it possible that irreversible behavior exists within it?
This irreversible behavior is materialized in the evolution of thermodynamic entropy, in such a way that the dynamics of thermodynamic systems is determined by an increase of entropy as the system evolves in time. This determines that the complexity of the emerging classical reality grows steadily in time and therefore the amount of information of the classical universe.
To answer this question we will hypothesize how the collapse of the wave function is the mechanism that determines how classical reality emerges from the underlying quantum nature, justifying the increase of entropy and as a consequence the rise in the amount of information.
In order to go deeper into this topic, we will proceed to analyze it from the point of view of the theory of computation and the theory of information, emphasizing the meaning and nature of the concept of entropy. This point of view is fundamental, since quantity of information and entropy are synonyms of the same phenomenon.
Reversible computing
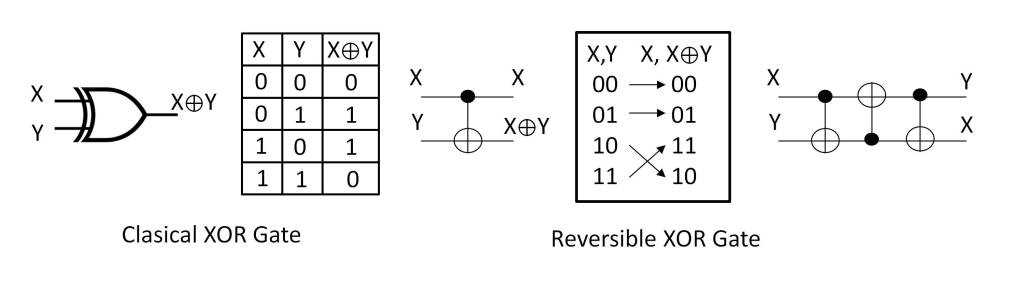
First we must analyze what reversible computation is and how it is implemented. To begin with, it should be emphasized that classical computation has an irreversible nature, which is made clear by a simple example, such as the XOR gate, which constitutes a universal set in classical computation, meaning that with a set of these gates any logical function can be implemented.
This gate performs the logical function X⊕Y from the logical variables X and Y, in such a way that in this process the system loses one bit of information, since the input information corresponds to two bits of information, while the output has only one bit of information. Therefore, once the X⊕Y function has been executed, it is not possible to recover the values of the X and Y variables.
According to Landauer’s principle [1], this loss of information means that the system dissipates energy in the environment, increasing its entropy, so that the loss of one bit of information dissipates a minimum energy k·T·ln2 in the environtment. Where k is Boltzmann’s constant and T is the absolute temperature of the system.
Therefore, for a classic system to be reversible it must verify that it does not lose information, so two conditions must be verified:
The number of input and output bits must be the same.
The relationship between inputs and outputs must be bijective.
The following figure shows the above criteria. But this does not mean that the logic function can be considered a complete set of implementation in a reversible computational context, since the relationship between inputs and outputs is linear and therefore cannot implement nonlinear functions.
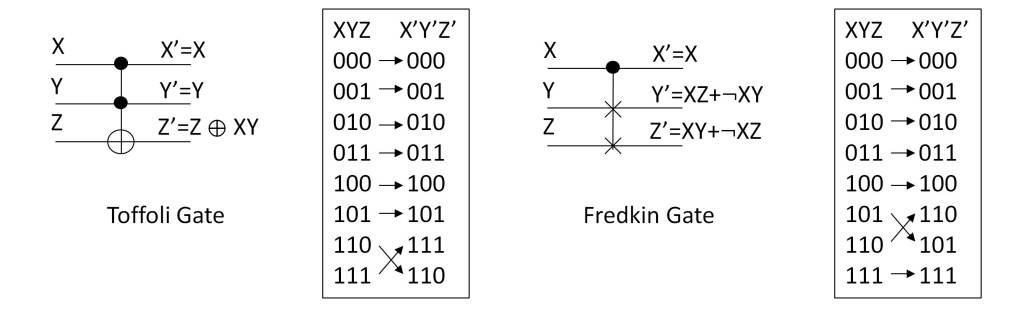
It is shown that for this to be possible the number of bits must be n≥3, an example being the Toffoli gate (X,Y,Z)→(X,Y,Z⊕XY) and Fredkin gate (X,Y,Z)→(X, XZ+¬XY,XY+¬XZ), where ¬ is the logical negation.
For this type of gates to form a universal set of quantum computation it is also necessary that they verify the ability to implement nonlinear functions, so according to its truth table the Toffoli gate is not a universal quantum set, unlike the Fredkin gate which is.
One of the reasons for studying universal reversible models of computation, such as the billiard ball model proposed by Fredkin and Toffoli [2], is that they could theoretically lead to real computational systems that consume very low amounts of energy.
But where these models become relevant is in quantum computation, since quantum theory has a reversible nature, which makes it possible to implement reversible algorithms by using reversible logic gates. The reversibility of these algorithms opens up the possibility of reducing the energy dissipated in their execution and approaching the Landauer limit.
Fundamentals of quantum computing
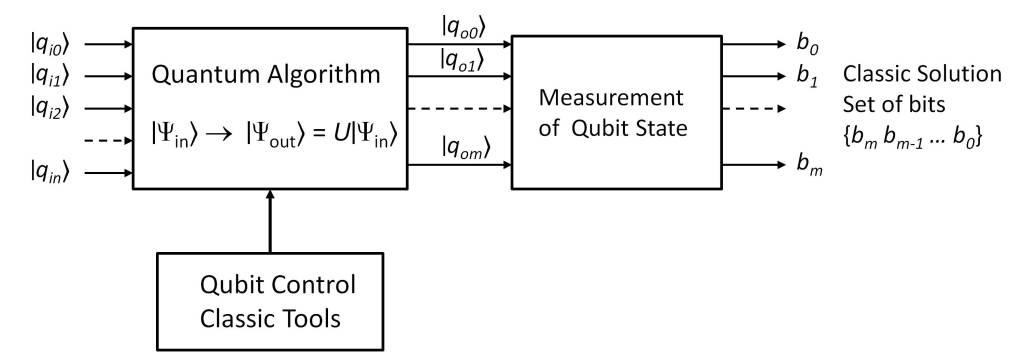
In the case of classical computing a bit of information can take one of the values {0,1}. In contrast, the state of a quantum variable is a superposition of its eigenstates. Thus, for example, the eigenstates of the spin of a particle with respect to some reference axes are {|0〉,|1〉}, so that the state of the particle |Ψ〉 can be in a superposition of the eigenstates |Ψ〉= α|0〉+ β|1〉, α2+ β2 = 1. This is what is called a qubit, so that a qubit can simultaneously encode the values {0,1}.
Thus, in a system consisting of n qubits its wave function can be expressed as |Ψ〉 = α0|00…00〉+α1|00…01〉+α2|00…10〉+…+αN-1|11…11〉, Σ(αi)2 =1, N=2n, such that the system can encode the N possible combinations of n bits and process them simultaneously, which is an exponential speedup compared to classical computing.
The time evolution of the wave function of a quantum system is determined by a unitary transformation, |Ψ’〉 = U|Ψ〉, such that the transposed conjugate of U is its inverse, U†U = UU†= I. Therefore, the process is reversible |Ψ〉 = U†|Ψ’〉 = U†U|Ψ〉, keeping the entropy of the system constant throughout the process, so the implementation of quantum computing algorithms must be performed with reversible logic gates. As an example, the inverse function of the Ferdkin gate is itself, as can be easily deduced from its definition.
The evolution of the state of the quantum system continues until it interacts with a measuring device, in what is defined as the quantum measurement, such that the system collapses into one of its possible states |Ψ〉 = |i〉, with probability (αi)2. Without going into further details, this behavior raises a philosophical debate that nevertheless has an empirical confirmation.
Another fundamental feature of quantum reality is particle entanglement, which plays a fundamental role in the implementation of quantum algorithms, quantum cryptography and quantum teleportation.
To understand what particle entanglement means let us first analyze the wave function of two independent quantum particles. Thus, the wave function of a quantum system consisting of two qubits, |Ψ0〉 = α00|0〉+ α01|1〉, |Ψ1〉 = α10|0〉+ α11|1〉, can be expressed as:
such that both qubits behave as independent systems, since this expression is factorizable in the functions |Ψ0〉 and |Ψ1〉. Where ⊗ is the tensor product.
However, quantum theory admits solutions for the system, such as |Ψ〉 = α|00〉+β|11〉, α2+ β2 = 1, so if a measurement is performed on one of the qubits, the quantum state of the other collapses instantaneously, regardless of the location of the entangled qubits.
Thus, if one of the qubit collapses in state |0〉 the other qubit collapses also in state |0〉. Conversely, if the qubit collapses into the |1〉 state the other qubit collapses into the |1〉 state as well. This means that the entangled quantum system behaves not as a set of independent qubits, but as a single inseparable quantum system, until the measurement of the system is performed.
This behavior seems to violate the speed limit imposed by the theory of relativity, breaking the principle of locality, which establishes that the state of an object is only influenced by its immediate environment. These inconsistencies gave rise to what is known as the EPR paradox [3], positing that quantum theory was an incomplete theory requiring the existence of hidden local variables in the quantum model.
However, Bell’s theorem [4] proves that quantum physics is incompatible with the existence of local hidden variables. For this purpose, Bell determined what results should be obtained from the measurement of entangled particles, assuming the existence of local hidden variables. This leads to the establishment of a constraint on how the measurement results correlate, known as Bell’s inequalities.
The experimental results obtained by A. Aspect [5] have shown that particle entanglement is a real fact in the world of quantum physics, so that the model of quantum physics is complete and does not require the existence of local hidden variables.
In short, quantum computing is closely linked to the model of quantum physics, based on the concepts of: superposition of states, unitary transformations and quantum measurement. To this we must add particle entanglement, so that a quantum system can be formed by a set of entangled particles, which form a single quantum system.
Based on these concepts, the structure of a quantum computer is as shown in the figure below. Without going into details about the functional structure of each block, the logic gates that constitute the quantum algorithm perform a specific function, for example the product of two variables. In this case, the input qubits would encode all the possible combinations of the input variables, obtaining as a result all the possible products of the input variables, encoded in the superposition of states of the output qubits.
For the information to emerge into the classical world it is necessary to measure the set of output qubits, so that the quantum state randomly collapses into one of its eigenstates, which is embodied in a set of bits that encodes one of the possible outcomes.
But this does not seem to be of practical use. On the one hand, quantum computing involves exponential speedup, by running all products simultaneously. But all this information is lost when measuring quantum information. For this reason, quantum computing requires algorithm design strategies to overcome this problem.
Shor’s factorization algorithm [6] is a clear example of this. In this particular case, the input qubits will encode the number to be factorized, so that the quantum algorithm will simultaneously obtain all the prime divisors of the number. When the quantum measurement is performed, a single factor will be obtained, which will allow the rest of the divisors to be obtained sequentially in polynomial time, which means acceleration with respect to the classical algorithms that require an exponential time.
But fundamental questions arise from all this. It seems obvious that the classical reality emerges from the quantum measurement and, clearly, the information that emerges is only a very small part of the information describing the quantum system. Therefore, one of the questions that arise is: What happens to the information describing the quantum system when performing the measurement? But on the other hand, when performing the measurement information emerges at the classical level, so we must ask: What consequences does this behavior have on the dynamics of the classical universe?
Thermodynamic entropy
The impossibility of directly observing the collapse of the wave function has given rise to various interpretations of quantum mechanics, so that the problem of quantum measurement remains an unsolved mystery [7]. However, we can find some clue if we ask what quantum measurement means and what is its physical foundation.
In this sense, it should be noted that the quantum measurement process is based on the interaction of quantum systems exclusively. The fact that quantum measurement is generally associated with measurement scenarios in an experimental context can give the measurement an anthropic character and, as a consequence, a misperception of the true nature of quantum measurement and of what is defined as a quantum observable.
Therefore, if the quantum measurement involves only quantum systems, the evolution of these systems will be determined by unitary transformations, so that the quantum entropy will remain constant throughout the whole process. But on the other hand, this quantum interaction causes the emergence of information that constitutes classical reality and ultimately produces an increase in classical entropy. Consequently, what is defined as quantum measurement would be nothing more than the emergence of information that conforms classical reality.
The abstract view is clearly shown in practical cases. Thus, for example, from the interaction between atoms that interact with each other emerge the observable properties that determine the properties of the system they form, such as its mechanical properties. However, the quantum system formed by atoms evolves according to the laws of quantum mechanics, keeping the amount of quantum information constant.
Similarly, the interaction between a set of atoms to form a molecule is determined by the laws of quantum mechanics, and therefore by unitary transformations, so that the complexity of the system remains constant at the quantum level. However, at the classical level the resulting system is more complex, emerging new properties that constitute the laws of chemistry and biology.
The question that arises is how it is possible that equations at the microscopic level which are time invariant can lead to a time asymmetry, as shown by the Boltzmann equation of heat diffusion.
Another objection to this behavior, and to a purely mechanical basis for thermodynamics, is due to the fact that every finite system, however complex it may be, must recover its initial state periodically after the so-called recurrence time, as demonstrated by Poincaré [8]. However, by purely statistical analysis it is shown that the probability of a complex thermodynamic system returning to its initial state is practically zero, with recurrence times much longer than the age of the universe itself.
Perhaps the most significant and which clearly highlights the irreversibility of thermodynamic systems is the evolution of the entropy S, which determines the complexity of the system and whose temporal dynamics is increasing, such that the derivative of S is always positive Ṡ > 0. But what is more relevant is that this behavior is demonstrated from the quantum description of the system in what is known as “Pauli’s Master Equation” [9].
This shows that the classical reality emerges from the quantum reality in a natural way, which supports the hypothesis put forward, in such a way that the interaction between quantum systems results in what is called the collapse of the wave function of these systems, emerging the classical reality.
Thermodynamic entropy vs. information theory
The analysis of this behavior from the point of view of information theory confirms this idea. The fact that quantum theory is time-reversible means that the complexity of the system is invariant. In other words, the amount of information describing the quantum system is constant in time. However, the classical reality is subject to an increase of complexity in time determined by the evolution of thermodynamic entropy, which means that the amount of information of the classical system is increasing with time.
If we assume that classical reality is a closed system, this poses a contradiction since in such a system information cannot grow over time. Thus, in a reversible computing system the amount of information remains unchanged, while in a non-reversible computing system the amount of information decreases as the execution progresses. Consequently, classical reality cannot be considered as an isolated system, so the entropy increase must be produced by an underlying reality that injects information in a sustained way.
In short, this analysis is consistent with the results obtained from quantum physics, by means of the “Pauli’s Master Equation”, which shows that the entropy growth of classical reality is obtained from its quantum nature.
It is important to note that the thermodynamic entropy can be expressed as a function of the probability of the microstates as S = – k Σ(pi ln pi), where k is the Boltzmann constant and which matches the amount of information in a system, if the physical dimensions are chosen such that k = 1. Therefore, it seems clear that the thermodynamic entropy represents the amount of information that emerges from the quantum reality.
But there remains the problem of understanding the physical process by which quantum information emerges into the classical reality layer1. It should be noted that the analysis to obtain the classical entropy from the quantum state of the system is purely mathematical and does not provide physical criteria on the nature of the process. Something similar happens with the analysis of the system from the point of view of classical statistical mechanics [10], where the entropy of the system is obtained from the microstates of the system (generalized coordinates qi and generalized momentum pi), so it does not provide physical criteria to understand this behavior either.
The inflationary universe
The expansion of the universe [11] is another example of how the entropy of the universe is growing steadily since its beginning, suggesting that the classical universe is an open system. But, unlike thermodynamics, in this case the physical structure involved is the vacuum.
It is important to emphasize that historically physical models integrate the vacuum as a purely mathematical structure of space-time in which physical phenomena occur, so that conceptually it is nothing more than a reference frame. This means that in classical models, the vacuum or space-time is not explicitly considered as a physical entity, as is the case with other physical concepts.
The development of the theory of relativity is the first model in which it is recognized, at least implicitly, that the vacuum must be a complex physical structure. While it continues to be treated as a reference frame, two aspects clearly highlight this complexity: the interaction between space-time and momentum-energy, and its relativistic nature.
Experiments such as the Casimir effect [12] or the Lamb effect show the complexity of the vacuum, so that quantum mechanics attributes to the basic state of electromagnetic radiation zero-point electric field fluctuations that pervade empty space at all frequencies. Similarly, the Higgs field suggests that it permeates all of space, such that particles interacting with it acquire mass.But ultimately there is no model that defines spacetime beyond a simple abstract reference frame.
However, it seems obvious that the vacuum must be a physical entity, since physical phenomena occur within it and, above all, its size and complexity grow systematically. This means that its entropy grows as a function of time, so the system must be open, there being a source that injects information in a sustained manner. The current theory assumes that dark energy is the cause of inflation [13], although its existence and nature is still a hypothesis.
Conclusions
From the previous analysis it is deduced that the entropy increase of the classical systems emerges from the quantum reality, which produces a sustained increase of the information of the classical reality. For this purpose different points of view have been used, such as classical and quantum thermodynamic criteria, and mathematical criteria such as classical and quantum computation theory and information theory.
The results obtained by these procedures are concordant, allowing verification of the hypothesis that classical reality emerges in a sustained manner from quantum interaction, providing insight into what is meant by the collapse of the wave function.
What remains a mystery is how this occurs, for while the entropy increase is demonstrated from the quantum state of the system, this analysis does not provide physical criteria for how this occurs.
Evidently, this must be produced by the quantum interaction of the particles involved, so that the collapse of their wave function is a source of information at the classical level. However, it is necessary to confirm this behavior in different scenarios since, for example, in a system in equilibrium there is no increase in entropy and yet there is still a quantum interaction between the particles.
Another factor that must necessarily intervene in this behavior is the vacuum, since the growth of entropy is also determined by variations in the dimensions of the system, which is also evident in the case of the inflationary universe. However, the lack of a model of the physical vacuum describing its true nature makes it difficult to establish hypotheses to explain its possible influence on the sustained increase of entropy.
In conclusion, the increase of information produced by the expansion of the universe is an observable fact that is not yet justified by a physical model. On the contrary, the increase of information determined by entropy is a phenomenon that emerges from quantum reality and that is justified by the model of quantum physics and that, as has been proposed in this essay, would be produced by the collapse of the wave function.
Appendix
1 The irreversibility of the system is obtained from the quantum density matrix:
ρ(t)= ∑ i pi |i〉〈i|
Being |i〉 the eigenstates of the Hamiltonian ℌ0, such that the general Hamiltonian is ℌ=ℌ0+V, where the perturbation V is the cause of the state transitions. Thus for example, in an ideal gas ℌ0, could be the kinetic energy and V the interaction as a consequence of the collision of the atoms of the gas.
Consequently, “Pauli’s Master Equation” takes into consideration the interaction of particles with each other and their relation to the volume of the system, but in an abstract way. Thus, the interaction of two particles has a quantum nature, exchanging energy by means of bosons, something that is hidden in the mathematical development.
Similarly, gas particles interact with the vacuum, this interaction being fundamental, as is evident in the expansion of the gas shown in the figure. However, the quantum nature of this interaction is hidden in the model. Moreover, it is also not possible to establish what this interaction is like, beyond its motion, since we lack a vacuum model that allows this analysis.
References
[1]
R. Landauer, “Irreversibility and Heat Generation in Computing Process,” IBM J. Res. Dev., vol. 5, pp. 183-191, 1961.
[2]
E. Fredkin y T. Toffoli, «Conservative logic,» International Journal of Theoretical Physics, vol. 21, p. 219–253, 1982.
[3]
A. Einstein, B. Podolsky and N. Rose, “Can Quantum-Mechanical Description of Physical Reality be Considered Complete?,” Physical Review, vol. 47, pp. 777-780, 1935.
[4]
J. S. Bell, «On the Einstein Podolsky Rosen Paradox,» Physics, vol. 1, nº 3, pp. 195-290, 1964.
[5]
A. Aspect, P. Grangier and G. Roger, “Experimental Tests of Realistic Local Theories via Bell’s Theorem,” Phys. Rev. Lett., vol. 47, pp. 460-463, 1981.
[6]
P. W. Shor, «Polynomial-Time Algorithms for Prime Factorization and Discrete Logarithms on a Quantum Computer,» arXiv:quant-ph/9508027v2, 1996.
[7]
M. Schlosshauer, J. Kofler y A. Zeilinger, «A Snapshot of Foundational Attitudes Toward Quantum Mechanics,» arXiv:1301.1069v, 2013.
[8]
H. Poincaré, «Sur le problème des trois corps et les équations de la dynamique,» Acta Math, vol. 13, pp. 1-270, 1890.
[9]
F. Schwabl, Statistical Mechanics, pp. 491-494, Springer, 2006.
[10]
F. W. Sears, An Introduction to Thermodynamics, The Kinetic Theory of Gases, and Statistical Mechanics, Addison-Wesley Publishing Company, 1953.
[11]
A. H. Guth, The Inflationary Universe, Perseus, 1997.
[12]
H. B. G. Casimir, «On the Attraction Between Two Perfectly Conducting Plates,» Indag. Math. , vol. 10, p. 261–263., 1948.
[13]
P. J. E. Peebles y B. Ratra, «The cosmological constant and dark energy,» Reviews of Modern Physics, vol. 75, nº 2, p. 559–606, 2003.
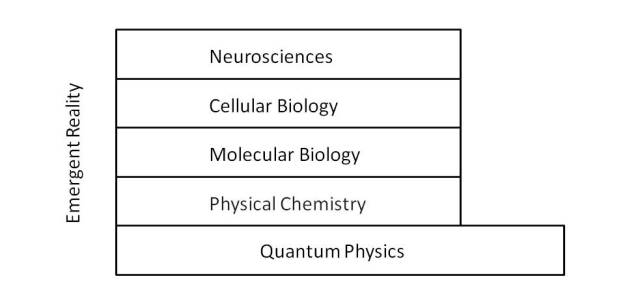
In the post “What is the nature of mathematics“, the dilemma of whether mathematics is discovered or invented by humans has been exposed, but so far no convincing evidence has been provided in either direction.
A more profound way of approaching the issue is as posed by Eugene P. Wigner [1], asking about the unreasonable effectiveness of mathematics in the natural sciences.
According to Roger Penrose this poses three mysteries [2] [3], identifying three distinct “worlds”: the world of our conscious perception, the physical world and the Platonic world of mathematical forms. Thus:
The world of physical reality seems to obey laws that actually reside in the world of mathematical forms.
The perceiving minds themselves – the realm of our conscious perception – have managed to emerge from the physical world.
Those same minds have been able to access the mathematical world by discovering, or creating, and articulating a capital of mathematical forms and concepts.
The effectiveness of mathematics has two different aspects. An active one in which physicists develop mathematical models that allow them to accurately describe the behavior of physical phenomena, but also to make predictions about them, which is a striking fact.
Even more extraordinary, however, is the passive aspect of mathematics, such that the concepts that mathematicians explore in an abstract way end up being the solutions to problems firmly rooted in physical reality.
But this view of mathematics has detractors especially outside the field of physics, in areas where mathematics does not seem to have this behavior. Thus, the neurobiologist Jean-Pierre Changeux notes [4], “Asserting the physical reality of mathematical objects on the same level as the natural phenomena studied in biology raises, in my opinion, a considerable epistemological problem. How can an internal physical state of our brain represent another physical state external to it?”
Obviously, it seems that analyzing the problem using case studies from different areas of knowledge does not allow us to establish formal arguments to reach a conclusion about the nature of mathematics. For this reason, an abstract method must be sought to overcome these difficulties. In this sense, Information Theory (IT) [5], Algorithmic Information Theory (AIT) [6] and Theory of Computation (TC) [7] can be tools of analysis that help to solve the problem.
What do we understand by mathematics?
The question may seem obvious, but mathematics is structured in multiple areas: algebra, logic, calculus, etc., and the truth is that when we refer to the success of mathematics in the field of physics, it underlies the idea of physical theories supported by mathematical models: quantum physics, electromagnetism, general relativity, etc.
However, when these mathematical models are applied in other areas they do not seem to have the same effectiveness, for example in biology, sociology or finance, which seems to contradict the experience in the field of physics.
For this reason, a fundamental question is to analyze how these models work and what are the causes that hinder their application outside the field of physics. To do this, let us imagine any of the successful models of physics, such as the theory of gravitation, electromagnetism, quantum physics or general relativity. These models are based on a set of equations defined in mathematical language, which determine the laws that control the described phenomenon, which admit analytical solutions that describe the dynamics of the system. Thus, for example, a body subjected to a central attractive force describes a trajectory defined by a conic.
This functionality is a powerful analysis tool, since it allows to analyze systems under hypothetical conditions and to reach conclusions that can be later verified experimentally. But beware! This success scenario masks a reality that often goes unnoticed, since generally the scenarios in which the model admits an analytical solution are very limited. Thus, the gravitational model does not admit an analytical solution when the number of bodies is n>=3 [8], except in very specific cases such as the so-called Lagrange points. Moreover, the system has a very sensitive behavior to the initial conditions, so that small variations in these conditions can produce large deviations in the long term.
This is a fundamental characteristic of nonlinear systems and, although the system is governed by deterministic laws, its behavior is chaotic. Without going into details that are beyond the scope of this analysis, this is the general behavior of the cosmos and everything that happens in it.
One case that can be considered extraordinary is the quantum model which, according to the Schrödinger equation or the Heisenberg matrix model, is a linear and reversible model. However, the information that emerges from quantum reality is stochastic in nature.
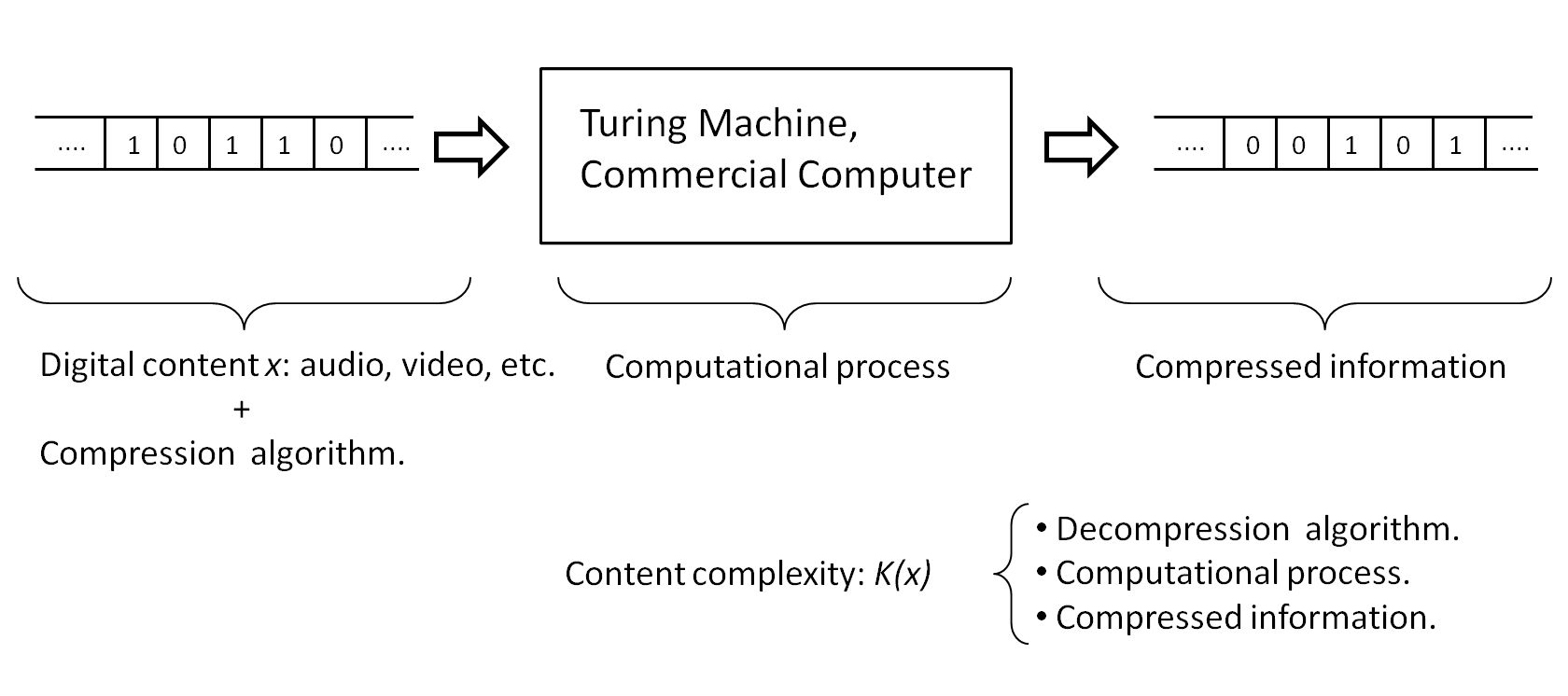
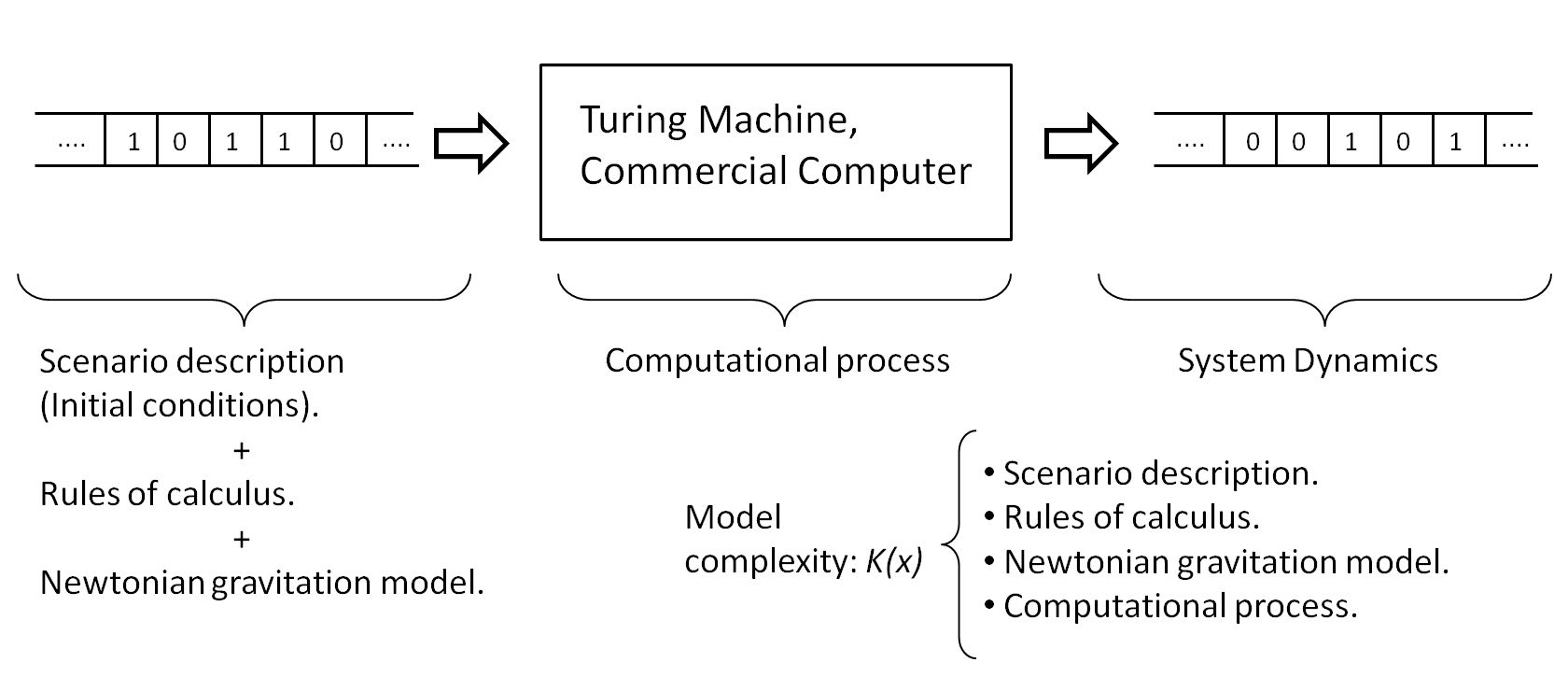
In short, the models that describe physical reality only have an analytical solution in very particular cases. For complex scenarios, particular solutions to the problem can be obtained by numerical series, but the general solution of any mathematical proposition is obtained by the Turing Machine (TM) [9].
This model can be represented in an abstract form by the concatenation of three mathematical objects〈xyz〉(bit sequences) which, when executed in a Turing machine TM(〈xyz〉), determine the solution. Thus, for example, in the case of electromagnetism, the object z will correspond to the description of the boundary conditions of the system, y to the definition of Maxwell’s equations and x to the formal definition of the mathematical calculus. TM is the Turing machine defined by a finite set of states. Therefore, the problem is reduced to the treatment of a set of bits〈xyz〉 according to axiomatic rules defined in TM, and that in the optimal case can be reduced to a machine with three states (plus the HALT state) and two symbols (bit).
Nature as a Turing machine
And here we return to the starting point. How is it possible that reality can be represented by a set of bits and a small number of axiomatic rules?
Prior to the development of IT, the concept of information had no formal meaning, as evidenced by its classic dictionary definition. In fact, until communication technologies began to develop, words such as “send” referred exclusively to material objects.
However, everything that happens in the universe is interaction and transfer, and in the case of humans the most elaborate medium for this interaction is natural language, which we consider to be the most important milestone on which cultural development is based. It is perhaps for this reason that in the debate about whether mathematics is invented or discovered, natural language is used as an argument.
But TC shows that natural language is not formal, not being defined on axiomatic grounds, so that arguments based on it may be of questionable validity. And it is here that IT and TC provide a broad view on the problem posed.
In a physical system each of the component particles has physical properties and a state, in such a way that when it interacts with the environment it modifies its state according to its properties, its state and the external physical interaction. This interaction process is reciprocal and as a consequence of the whole set of interactions the system develops a temporal dynamics.
Thus, for example, the dynamics of a particle is determined by the curvature of space-time which indicates to the particle how it should move and this in turn interacts with space-time, modifying its curvature.
In short, a system has a description that is distributed in each of the parts that make up the system. Thus, the system could be described in several different ways:
As a set of TMs interacting with each other.
As a TM describing the total system.
As a TM partially describing the global behavior, showing emergent properties of the system.
The fundamental conclusion is that the system is a Turing machine. Therefore, the question is not whether the mathematics is discovered or invented or to ask ourselves how it is possible for mathematics to be so effective in describing the system. The question is how it is possible for an intelligent entity – natural or artificial – to reach this conclusion and even to be able to deduce the axiomatic laws that control the system.
The justification must be based on the fact that it is nature that imposes the functionality and not the intelligent entities that are part of nature. Nature is capable of developing any computable functionality, so that among other functionalities, learning and recognition of behavioral patterns is a basic functionality of nature. In this way, nature develops a complex dynamic from which physical behavior, biology, living beings, and intelligent entities emerge.
As a consequence, nature has created structures that are able to identify its own patterns of behavior, such as physical laws, and ultimately identify nature as a Universal Turing Machine (UTM). This is what makes physical interaction consistent at all levels. Thus, in the above case of the ability of living beings to establish a spatio-temporal map, this allows them to interact with the environment; otherwise their existence would not be possible. Obviously this map corresponds to a Euclidean space, but if the living being in question were able to move at speeds close to light, the map learned would correspond to the one described by relativity.
A view beyond physics
While TC, IT and AIT are the theoretical support that allows sustaining this view of nature, advances in computer technology and AI are a source of inspiration, showing how reality can be described as a structured sequence of bits. This in turn enables functions such as pattern extraction and recognition, complexity determination and machine learning.
Despite this, fundamental questions remain to be answered, in particular what happens in those cases where mathematics does not seem to have the same success as in the case of physics, such as biology, economics or sociology.
Many of the arguments used against the previous view are based on the fact that the description of reality in mathematical terms, or rather, in terms of computational concepts does not seem to fit, or at least not precisely, in areas of knowledge beyond physics. However, it is necessary to recognize that very significant advances have been made in areas such as biology and economics.
Thus, knowledge of biology shows that the chemistry of life is structured in several overlapping languages:
The language of nucleic acids, consisting of an alphabet of 4 symbols that encodes the structure of DNA and RNA.
The amino acid language, consisting of an alphabet of 64 symbols that encodes proteins. The transcription process for protein synthesis is carried out by means of a concordance between both languages.
The language of the intergenic regions of the genome. Their functionality is still to be clarified, but everything seems to indicate that they are responsible for the control of protein production in different parts of the body, through the activation of molecular switches.
On the other hand, protein structure prediction by deep learning techniques is a solid evidence that associates biology to TC [10]. To emphasize also that biology as an information process must verify the laws of logic, in particular the recursion theorem [11], so DNA replication must be performed at least in two phases by independent processes.
In the case of economics there have been relevant advances since the 80’s of the twentieth century, with the development of computational finance [12]. But as a paradigmatic example we will focus on the financial markets, which should serve to test in an environment far from physics the hypothesis that nature has the behavior of a Turing machine.
Basically, financial markets are a space, which can be physical or virtual, through which financial assets are exchanged between economic agents and in which the prices of such assets are defined.
A financial market is governed by the law of supply and demand. In other words, when an economic agent wants something at a certain price, he can only buy it at that price if there is another agent willing to sell him that something at that price.
Traditionally, economic agents were individuals but, with the development of complex computer applications, these applications now also act as economic agents, both supervised and unsupervised, giving rise to different types of investment strategies.
This system can be modeled by a Turing machine that emulates all the economic agents involved, or as a set of Turing machines interacting with each other, each of which emulates an economic agent.
The definition of this model requires implementing the axiomatic rules of the market, as well as the functionality of each of the economic agents, which allow them to determine the purchase or sale prices at which they are willing to negotiate. This is where the problem lies, since this depends on very diverse and complex factors, such as the availability of information on the securities traded, the agent’s psychology and many other factors such as contingencies or speculative strategies.
In brief, this makes emulation of the system impossible in practice. It should be noted, however, that brokers and automated applications can gain a competitive advantage by identifying global patterns, or even by insider trading, although this practice is punishable by law in suitably regulated markets.
The question that can be raised is whether this impossibility of precise emulation invalidates the hypothesis put forward. If we return to the case study of Newtonian gravitation, determined by the central attractive force, it can be observed that, although functionally different, it shares a fundamental characteristic that makes emulation of the system impossible in practice and that is present in all scenarios.
If we intend to emulate the case of the solar system we must determine the position, velocity and angular momentum of all celestial bodies involved, sun, planets, dwarf planets, planetoids, satellites, as well as the rest of the bodies located in the system, such as the asteroid belt, the Kuiper belt and the Oort cloud, as well as the dispersed mass and energy. In addition, the shape and structure of solid, liquid and gaseous bodies must be determined. It will also be necessary to consider the effects of collisions that modify the structure of the resulting bodies. Finally, it will be necessary to consider physicochemical activity, such as geological, biological and radiation phenomena, since they modify the structure and dynamics of the bodies and are subject to quantum phenomena, which is another source of uncertainty. And yet the model is not adequate, since it is necessary to apply a relativistic model.
This makes accurate emulation impossible in practice, as demonstrated by the continuous corrections in the ephemerides of GPS satellites, or the adjustments of space travel trajectories, where the journey to Pluto by NASA’s New Horizons spacecraft is a paradigmatic case.
Conclusions
From the previous analysis it can be hypothesized that the universe is an axiomatic system governed by laws that determine a dynamic that is a consequence of the interaction and transference of the entities that compose it.
As a consequence of the interaction and transfer phenomena, the system itself can partially and approximately emulate its own behavior, which gives rise to learning processes and finally gives rise to life and intelligence. This makes it possible for living beings to interact in a complex way with the environment and for intelligent entities to observe reality and establish models of this reality.
This gave rise to abstract representations such as natural language and mathematics. With the development of IT [5] it is concluded that all objects can be represented by a set of bits, which can be processed by axiomatic rules [7] and which optimally encoded determine the complexity of the object, defined as Kolmogorov complexity [6].
The development of TC establishes that these models can be defined as a TM, so that in the limit it can be hypothesized that the universe is equivalent to a Turing machine and that the limits of reality can go beyond the universe itself, in what is defined as multiverse and that it would be equivalent to a UTM. Esta concordancia entre un universo y una TM permite plantear la hipótesis de que el universo no es más que información procesada por reglas axiomáticas.
Therefore, from the observation of natural phenomena we can extract the laws of behavior that constitute the abstract models (axioms), as well as the information necessary to describe the cases of reality (information). Since this representation is made on a physical reality, its representation will always be approximate, so that only the universe can emulate itself. Since the universe is consistent, models only corroborate this fact. But reciprocally, the equivalence between the universe and a TM implies that the deductions made from consistent models must be satisfied by reality.
However, everything seems to indicate that this way of perceiving reality is distorted by the senses, since at the level of classical reality what we observe are the consequences of the processes that occur at this functional level, appearing concepts such as mass, energy, inertia.
But when we explore the layers that support classical reality, this perception disappears, since our senses do not have the direct capability for its observation, in such a way that what emerges is nothing more than a model of axiomatic rules that process information, and the physical sensory conception disappears. This would justify the difficulty to understand the foundations of reality.
It is sometimes speculated that reality may be nothing more than a complex simulation, but this poses a problem, since in such a case a support for its execution would be necessary, implying the existence of an underlying reality necessary to support such a simulation [13].
There are two aspects that have not been dealt with and that are of transcendental importance for the understanding of the universe. The first concerns irreversibility in the layer of classical reality. According to the AIT, the amount of information in a TM remains constant, so the irreversibility of thermodynamic systems is an indication that these systems are open, since they do not verify this property, an aspect to which physics must provide an answer.
The second is related to the non-cloning theorem. Quantum systems are reversible and, according to the non-cloning theorem, it is not possible to make exact copies of the unknown quantum state of a particle. But according to the recursion theorem, at least two independent processes are necessary to make a copy. This would mean that in the quantum layer it is not possible to have at least two independent processes to copy such a quantum state. An alternative explanation would be that these quantum states have a non-computable complexity.
Finally, it should be noted that the question of whether mathematics was invented or discovered by humans is flawed by an anthropic view of the universe, which considers humans as a central part of it. But it must be concluded that humans are a part of the universe, as are all the entities that make up the universe, particularly mathematics.
References
[1]
E. P. Wigner, “The unreasonable effectiveness of mathematics in the natural sciences.,” Communications on Pure and Applied Mathematics, vol. 13, no. 1, pp. 1-14, 1960.
[2]
R. Penrose, The Emperor’s New Mind: Concerning Computers, Minds, and the Laws of Physics, Oxford: Oxford University Press, 1989.
[3]
R. Penrose, The Road to Reality: A Complete Guide to the Laws of the Universe, London: Jonathan Cape, 2004.
[4]
J.-P. Changeux and A. Connes, Conversations on Mind, Matter, and Mathematics, Princeton N. J.: Princeton University Press, 1995.
[5]
C. E. Shannon, “A Mathematical Theory of Communication,” The Bell System Technical Journal, vol. 27, pp. 379-423, 1948.
[6]
P. Günwald and P. Vitányi, “Shannon Information and Kolmogorov Complexity,” arXiv:cs/0410002v1 [cs:IT], 2008.
[7]
M. Sipser, Introduction to the Theory of Computation, Course Technology, 2012.
[8]
H. Poincaré, New Methods of Celestial Mechanics, Springer, 1992.
[9]
A. M. Turing, “On computable numbers, with an application to the Entscheidungsproblem.,” Proceedings, London Mathematical Society, pp. 230-265, 1936.
[10]
A. W. Senior, R. Evans and e. al., “Improved protein structure prediction using potentials from deep learning,” Nature, vol. 577, pp. 706-710, Jan 2020.
[11]
S. Kleene, “On Notation for ordinal numbers,” J. Symbolic Logic, no. 3, p. 150–155, 1938.
[12]
A. Savine, Modern Computational Finance: AAD and Parallel Simulations, Wiley, 2018.
[13]
N. Bostrom, “Are We Living in a Computer Simulation?,” The Philosophical Quarterly, vol. 53, no. 211, p. 243–255, April 2003.
The ability of mathematics to describe the behavior of nature, particularly in the field of physics, is a surprising fact, especially when one considers that mathematics is an abstract entity created by the human mind and disconnected from physical reality. But if mathematics is an entity created by humans, how is this precise correspondence possible?
Throughout centuries this has been a topic of debate, focusing on two opposing ideas: Is mathematics invented or discovered by humans?
This question has divided the scientific community: philosophers, physicists, logicians, cognitive scientists and linguists, and it can be said that not only is there no consensus, but generally positions are totally opposed. Mario Livio in the essay “Is God a Mathematician? [1] describes in a broad and precise way the historical events on the subject, from Greek philosophers to our days.
The aim of this post is to analyze this dilemma, introducing new analysis tools such as Information Theory (IT) [2], Algorithmic Information Theory (AIT) [3] and Computer Theory (CT) [4], without forgetting the perspective that shows the new knowledge about Artificial Intelligence (AI).
In this post we will make a brief review of the current state of the issue, without entering into its historical development, trying to identify the difficulties that hinder its resolution, for in subsequent posts to analyze the problem from a different perspective to the conventional, using the logical tools that offer us the above theories.
Currents of thought: invented or discovered?
In a very simplified way, it can be said that at present the position that mathematics is discovered by humans is headed by Max Tegmark, who states in “Our Mathematical Universe” [5] that the universe is a purely mathematical entity, which would justify that mathematics describes reality with precision, but that reality itself is a mathematical entity.
On the other extreme, there is a large group of scientists, including cognitive scientists and biologists who, based on the fact of the brain’s capabilities, maintain that mathematics is an entity invented by humans.
Max Tegmark: Our Mathematical Universe
In both cases, there are no arguments that would tip the balance towards one of the hypotheses. Thus, in Max Tegmark’s case he maintains that the definitive theory (Theory of Everything) cannot include concepts such as “subatomic particles”, “vibrating strings”, “space-time deformation” or other man-made constructs. Therefore, the only possible description of the cosmos implies only abstract concepts and relations between them, which for him constitute the operative definition of mathematics.
This reasoning assumes that the cosmos has a nature completely independent of human perception, and its behavior is governed exclusively by such abstract concepts. This view of the cosmos seems to be correct insofar as it eliminates any anthropic view of the universe, in which humans are only a part of it. However, it does not justify that physical laws and abstract mathematical concepts are the same entity.
In the case of those who maintain that mathematics is an entity invented by humans, the arguments do not usually have a formal structure and it could be said that in many cases they correspond more to a personal position and sentiment. An exception is the position maintained by biologists and cognitive scientists, in which the arguments are based on the creative capacity of the human brain and which would justify that mathematics is an entity created by humans.
For these, mathematics does not really differ from natural language, so mathematics would be no more than another language. Thus, the conception of mathematics would be nothing more than the idealization and abstraction of elements of the physical world. However, this approach presents several difficulties to be able to conclude that mathematics is an entity invented by humans.
On the one hand, it does not provide formal criteria for its demonstration. But it also presupposes that the ability to learn is an attribute exclusive to humans. This is a crucial point, which will be addressed in later posts. In addition, natural language is used as a central concept, without taking into account that any interaction, no matter what its nature, is carried out through language, as shown by the TC [4], which is a theory of language.
Consequently, it can be concluded that neither current of thought presents conclusive arguments about what the nature of mathematics is. For this reason, it seems necessary to analyze from new points of view what is the cause for this, since physical reality and mathematics seem intimately linked.
Mathematics as a discovered entity
In the case that considers mathematics the very essence of the cosmos, and therefore that mathematics is an entity discovered by humans, the argument is the equivalence of mathematical models with physical behavior. But for this argument to be conclusive, the Theory of Everything should be developed, in which the physical entities would be strictly of a mathematical nature. This means that reality would be supported by a set of axioms and the information describing the model, the state and the dynamics of the system.
This means a dematerialization of physics, something that somehow seems to be happening as the development of the deeper structures of physics proceeds. Thus, the particles of the standard model are nothing more than abstract entities with observable properties. This could be the key, and there is a hint in Landauer’s principle [6], which establishes an equivalence between information and energy.
But solving the problem by physical means or, to be more precise, by contrasting mathematical models with reality presents a fundamental difficulty. In general, mathematical models describe the functionality of a certain context or layer of reality, and all of them have a common characteristic, in such a way that these models are irreducible and disconnected from the underlying layers. Therefore, the deepest functional layer should be unraveled, which from the point of view of AIT and TC is a non-computable problem.
Mathematics as an invented entity
The current of opinion in favor of mathematics being an entity invented by humans is based on natural language and on the brain’s ability to learn, imagine and create.
But this argument has two fundamental weaknesses. On the one hand, it does not provide formal arguments to conclusively demonstrate the hypothesis that mathematics is an invented entity. On the other hand, it attributes properties to the human brain that are a general characteristic of the cosmos.
The Hippocampus: A paradigmatic example of the dilemma discovered or invented
To clarify this last point, let us take as an example the invention of whole numbers by humans, which is usually used to support this view. Let us now imagine an animal interacting with the environment. Therefore, it has to interpret spacetime accurately as a basic means of survival. Obviously, the animal must have learned or invented the space-time map, something much more complex than natural numbers.
Moreover, nature has provided or invented the hippocampus [7], a neuronal structure specialized in acquiring long-term information that forms a complex convolution, forming a recurrent neuronal network, very suitable for the treatment of the space-time map and for the resolution of trajectories. And of course this structure is physical and encoded in the genome of higher animals. The question is: Is this structure discovered or invented by nature?
Regarding the use of language as an argument, it should be noted that language is the means of interaction in nature at all functional levels. Thus, biology is a language, the interaction between particles is formally a language, although this point requires a deeper analysis for its justification. In particular, natural language is in fact a non-formal language, so it is not an axiomatic language, which makes it inconsistent.
Finally, in relation to the learning capability attributed to the brain, this is a fundamental characteristic of nature, as demonstrated by mathematical models of learning and evidenced in an incipient manner by AI.
Another way of approaching the question about the nature of mathematics is through Wigner’s enigma [8], in which he asks about the inexplicable effectiveness of mathematics. But this topic and the topics opened before will be dealt with and expanded in later posts.
References
[1]
M. Livio, Is God a Mathematician?, New York: Simon & Schuster Paperbacks, 2009.
[2]
C. E. Shannon, «A Mathematical Theory of Communication,» The Bell System Technical Journal, vol. 27, pp. 379-423, 1948.
[3]
P. Günwald and P. Vitányi, “Shannon Information and Kolmogorov Complexity,” arXiv:cs/0410002v1 [cs:IT], 2008.
[4]
M. Sipser, Introduction to the Theory of Computation, Course Technology, 2012.
[5]
M. Tegmark, Our Mathematical Universe: My Quest For The Ultimate Nature Of Reality, Knopf Doubleday Publishing Group, 2014.
[6]
R. Landauer, «Irreversibility and Heat Generation in Computing Process,» IBM J. Res. Dev., vol. 5, pp. 183-191, 1961.
[7]
S. Jacobson y E. M. Marcus, Neuroanatomy for the Neuroscientist, Springer, 2008.
[8]
E. P. Wigner, «The unreasonable effectiveness of mathematics in the natural sciences.,» Communications on Pure and Applied Mathematics, vol. 13, nº 1, pp. 1-14, 1960.
In previous posts, the nature of reality and its complexity has been approached from the point of view of Information Theory. However, it is interesting to make this analysis from the point of view of human perception and thus obtain a more intuitive view.
Obviously, making an exhaustive analysis of reality from this perspective is complex due to the diversity of the organs of perception and the physiological and neurological aspects that develop over them. In this sense, we could explain how the information perceived is processed, depending on each of the organs of perception. Especially the auditory and visual systems, as these are more culturally relevant. Thus, in the post dedicated to color perception it has been described how the physical parameters of light are encoded by the photoreceptor cells of the retina.
However, in this post the approach will consist of analyzing in an abstract way how knowledge influences the interpretation of information, in such a way that previous experience can lead the analysis in a certain direction. This behavior establishes a priori assumptions or conditions that limit the analysis of information in all its extension and that, as a consequence, prevent to obtain certain answers or solutions. Overcoming these obstacles, despite the conditioning posed by previous experience, is what is known as lateral thinking.
To begin with, let’s consider the case of series math puzzles in which a sequence of numbers, characters, or graphics is presented, asking how the sequence continues. For example, given the sequence “IIIIIIIVVV”, we are asked to determine which the next character is. If the Roman culture had not developed, it could be said that the next character is “V”, or also that the sequence has been made by little scribblers. But this is not the case, so the brain begins to engineer determining that the characters can be Roman and that the sequence is that of the numbers “1,2,3,…”. Consequently, the next character must be “I”.
In this way, it can be seen how the knowledge acquired conditions the interpretation of the information perceived by the senses. But from this example another conclusion can be drawn, consisting of the ordering of information as a sign of intelligence. To expose this idea in a formal way let’s consider a numerical sequence, for example the Fibonacci series “0,1,2,3,5,8,…”. Similarly to the previous case, the following number should be 13, so that the general term can be expressed as fn=fn-1+fn-2. However, we can define another discrete mathematical function that takes the values “0,1,2,3,5,8” for n = 0,1,2,3,4,5, but differs for the rest of the values of n belonging to the natural numbers, as shown in the following figure. In fact, with this criterion it is possible to define an infinite number of functions that meet this criterion.
The question, therefore, is: What is so special about the Fibonacci series in relation to the set of functions that meet the condition defined above?
Here we can make the argument already used in the case of the Roman number series. So that mathematical training leads to identifying the series of numbers as belonging to the Fibonacci series. But this poses a contradiction, since any of the functions that meet the same criterion could have been identified. To clear up this contradiction, Algorithmic Information Theory (AIT) should be used again.
Firstly, it should be stressed that culturally the game of riddles implicitly involves following logical rules and that, therefore, the answer is free from arbitrariness. Thus, in the case of number series the game consists of determining a rule that justifies the result. If we now try to identify a simple mathematical series that determines the sequence “0,1,2,3,5,8,…” we see that the expression fn=fn-1+fn-2 fulfills these requirements. In fact, it is possible that this is the simplest within this type of expressions. The rest are either complex, arbitrary or simple expressions that follow different rules from the implicit rules of the puzzle.
From the AIT point of view, the solution that contains the minimum information and can therefore be expressed most readily will be the most likely response that the brain will give in identifying a pattern determined by a stimulus. In the example above, the description of the predictable solution will be the one composed of:
A Turing machine.
The information to code the calculus rules.
The information to code the analytical expression of the simplest solution. In the example shown it corresponds to the expression of the Fibonacci series.
Obviously, there are solutions of similar or even less complexity, such as the one performed by a Turing machine that periodically generates the sequence “0,1,2,3,5,8”. But in most cases the solutions will have a more complex description, so that, according to the AIT, in most cases their most compact description will be the sequence itself, which cannot be compressed or expressed analytically.
For example, it is easy to check that the function:
generates for integer values of n the sequence “0,1,1,2,3,5,8,0,-62,-279,…”, so it could be said that the quantities following the proposed series are “…,0,-62,-279,… Obviously, the complexity of this sequence is higher than that of the Fibonacci series, as a result of the complexity of the description of the function and the operations to be performed.
Similarly, we can try to define other algorithms that generate the proposed sequence, which will grow in complexity. This shows the possibility of interpreting the information from different points of view that go beyond the obvious solutions, which are conditioned by previous experiences.
If, in addition to all the above, it is considered that, according to Landauer’s principle, information complexity is associated with greater energy consumption, the resolution of complex problems not only requires a greater computational effort, but also a greater energy effort.
This may explain the feeling of satisfaction produced when a certain problem is solved, and the tendency to engage in relaxing activities that are characterized by simplicity or monotony. Conversely, the lack of response to a problem produces frustration and restlessness.
This is in contrast to the idea that is generally held about intelligence. Thus, the ability to solve problems such as the ones described above is considered a sign of intelligence. But on the contrary, the search for more complex interpretations does not seem to have this status. Something similar occurs with the concept of entropy, which is generally interpreted as disorder or chaos and yet from the point of view of information it is a measure of the amount of information.
Another aspect that should be highlighted is the fact that the cognitive process is supported by the processing of information and, therefore, subject to the rules of mathematical logic, whose nature is irrefutable. This nuance is important, since emphasis is generally placed on the physical and biological mechanisms that support the cognitive processes, which may eventually be assigned a spiritual or esoteric nature.
Therefore, it can be concluded that the cognitive process is subject to the nature and structure of information processing and that from the formal point of view of the Theory of Computability it corresponds to a Turing machine. In such a way that nature has created a processing structure based on the physics of emerging reality – classical reality -, materialized in a neural network, which interprets the information coded by the perception senses, according to the algorithmic established by previous experience. As a consequence, the system performs two fundamental functions, as shown in the figure:
Interact with the environment, producing a response to the input stimuli.
Enhance the ability to interpret, acquiring new skills -algorithmic- as a result of the learning capacity provided by the neural network.
But the truth is that the input stimuli are conditioned by the sensory organs, which constitute a first filter of information and therefore they condition the perception of reality. The question that can be raised is: What impact does this filtering have on the perception of reality?
The purpose of physics is the description and interpretation of physical reality based on observation. To this end, mathematics has been a fundamental tool to formalize this reality through models, which in turn have allowed predictions to be made that have subsequently been experimentally verified. This creates an astonishing connection between reality and abstract logic that makes suspect the existence of a deep relationship beyond its conceptual definition. In fact, the ability of mathematics to accurately describe physical processes can lead us to think that reality is nothing more than a manifestation of a mathematical world.
But perhaps it is necessary to define in greater detail what we mean by this. Usually, when we refer to mathematics we think of concepts such as theorems or equations. However, we can have another view of mathematics as an information processing system, in which the above concepts can be interpreted as a compact expression of the behavior of the system, as shown by the algorithmic information theory [1].
In this way, physical laws determine how the information that describes the system is processed, establishing a space-time dynamic. As a consequence, a parallelism is established between the physical system and the computational system that, from an abstract point of view, are equivalent. This equivalence is somewhat astonishing, since in principle we assume that both systems belong to totally different fields of knowledge.
But apart from this fact, we can ask what consequences can be drawn from this equivalence. In particular, computability theory [2] and information theory [3] [1] provide criteria for determining the computational reversibility and complexity of a system [4]. In particular:
In a reversible computing system (RCS) the amount of information remains constant throughout the dynamics of the system.
In a non-reversible computational system (NRCS) the amount of information never increases along the dynamics of the system.
The complexity of the system corresponds to the most compact expression of the system, called Kolmogorov complexity and is an absolute measure.
It is important to note that in an NRCS system information is not lost, but is explicitly discarded. This means that there is no fundamental reason why such information should not be maintained, as the complexity of an RCS system remains constant. In practice, the implementation of computer systems is non-reversible in order to optimize resources, as a consequence of the technological limitations for its implementation. In fact, the energy currently needed for its implementation is much higher than that established by the Landauer principle [5].
If we focus on the analysis of reversible physical systems, such as quantum mechanics, relativity, Newtonian mechanics or electromagnetism, we can observe invariant physical magnitudes that are a consequence of computational reversibility. These are determined by unitary mathematical processes, which mean that every process has an inverse process [6]. But the difficulties in understanding reality from the point of view of mathematical logic seem to arise immediately, with thermodynamics and quantum measurement being paradigmatic examples.
In the case of quantum measurement, the state of the system before the measurement is made is in a superposition of states, so that when the measurement is made the state collapses in one of the possible states in which the system was [7]. This means that the quantum measurement scenario corresponds to that of a non-reversible computational system, in which the information in the system decreases when the superposition of states disappears, making the system non-reversible as a consequence of the loss of information.
This implies that physical reality systematically loses information, which poses two fundamental contradictions. The first is the fact that quantum mechanics is a reversible theory and that observable reality is based on it. The second is that this loss of information contradicts the systematic increase of classical entropy, which in turn poses a deeper contradiction, since in classical reality there is a spontaneous increase of information, as a consequence of the increase of entropy.
The solution to the first contradiction is relatively simple if we eliminate the anthropic vision of reality. In general, the process of quantum measurement introduces the concept of observer, which creates a certain degree of subjectivity that is very important to clarify, as it can lead to misinterpretations. In this process there are two clearly separated layers of reality, the quantum layer and the classical layer, which have already been addressed in previous posts. The realization of quantum measurement involves two quantum systems, one that we define as the system to be measured and another that corresponds to the measurement system, which can be considered as a quantum observer, and both have a quantum nature. As a result of this interaction, classical information emerges, where the classical observer is located, who can be identified e.g. with a physicist in a laboratory.
Now consider that the measurement is structured in two blocks, one the quantum system under observation and the other the measurement system that includes the quantum observer and the classical observer. In this case it is being interpreted that the quantum system under measurement is an open quantum system that loses quantum information in the measurement process and that as a result a lesser amount of classical information emerges. In short, this scenario offers a negative balance of information.
But, on the contrary, in the quantum reality layer the interaction of two quantum systems takes place which, it can be said, mutually observe each other according to unitary operators, so that the system is closed producing an exchange of information with a null balance of information. As a result of this interaction, the classical layer emerges. But then there seems to be a positive balance of information, as classical information emerges from this process. But what really happens is that the emerging information, which constitutes the classical layer, is simply a simplified view of the quantum layer. For this reason we can say that the classical layer is an emerging reality.
So, it can be said that the quantum layer is formed by subsystems that interact with each other in a unitary way, constituting a closed system in which the information and, therefore, the complexity of the system is invariant. As a consequence of these interactions, the classical layer emerges as an irreducible reality of the quantum layer.
As for the contradiction produced by the increase in entropy, the reasons justifying this behavior seem more subtle. However, a first clue may lie in the fact that this increase occurs only in the classical layer. It must also be considered that, according to the algorithmic information theory, the complexity of a system, and therefore the amount of information that describes the system, is the set formed by the processed information and the information necessary to describe the processor itself.
A physical scenario that can illustrate this situation is the case of the big bang [8], in which it is considered that the entropy of the system in its beginning was small or even null. This is so because the microwave background radiation shows a fairly homogeneous pattern, so the amount of information for its description and, therefore, its entropy is small. But if we create a computational model of this scenario, it is evident that the complexity of the system has increased in a formidable way, which is incompatible from the logical point of view. This indicates that in the model not only the information is incomplete, but also the description of the processes that govern it. But what physical evidence do we have to show that this is so?
Perhaps the clearest sample of this is cosmic inflation [9], so that the space-time metric changes with time, so that the spatial dimensions grow with time. To explain this behavior the existence of dark energy has been postulated as the engine of this process [10], which in a physical form recognizes the gaps revealed by mathematical logic. Perhaps one aspect that is not usually paid attention is the interaction between vacuum and photons, which produces a loss of energy in photons as space-time expands. This loss supposes a decrease of information that necessarily must be transferred to space-time.
This situation causes the vacuum, which in the context of classical physics is nothing more than an abstract metric, to become a fundamental physical piece of enormous complexity. Aspects that contribute to this conception of vacuum are the entanglement of quantum particles [11], decoherence and zero point energy [12].
From all of the above, a hypothesis can be made as to what the structure of reality is from a computational point of view, as shown in the following figure. If we assume that the quantum layer is a unitary and closed structure, its complexity will remain constant. But the functionality and complexity of this remains hidden from observation and it is only possible to model it through an inductive process based on experimentation, which has led to the definition of physical models, in such a way that these models allow us to describe classical reality. As a consequence, the quantum layer shows a reality that constitutes the classical layer and that is a partial vision and, according to the theoretical and experimental results, extremely reduced of the underlying reality and that makes the classical reality an irreducible reality.
The fundamental question that can be raised in this model is whether the complexity of the classical layer is constant or whether it can vary over time, since it is only bound by the laws of the underlying layer and is a partial and irreducible view of that functional layer. But for the classical layer to be invariant, it must be closed and therefore its computational description must be closed, which is not verified since it is subject to the quantum layer. Consequently, the complexity of the classical layer may change over time.
Consequently, the question arises as to whether there is any mechanism in the quantum layer that justifies the fluctuation of the complexity of the classical layer. Obviously one of the causes is quantum decoherence, which makes information observable in the classical layer. Similarly, cosmic inflation produces an increase in complexity, as space-time grows. On the contrary, attractive forces tend to reduce complexity, so gravity would be the most prominent factor.
From the observation of classical reality we can answer that currently its entropy tends to grow, as a consequence of the fact that decoherence and inflation are predominant causes. However, one can imagine recession scenarios, such as a big crunch scenario in which entropy decreased. Therefore, the entropy trend may be a consequence of the dynamic state of the system.
In summary, it can be said that the amount of information in the quantum layer remains constant, as a consequence of its unitary nature. On the contrary, the amount of information in the classical layer is determined by the amount of information that emerges from the quantum layer. Therefore, the challenge is to determine precisely the mechanisms that determine the dynamics of this process. Additionally, it is possible to analyze specific scenarios that generally correspond to the field of thermodynamics. Other interesting scenarios may be quantum in nature, such as the one proposed by Hugh Everett on the Many-Worlds Interpretation (MWI).
Bibliography
[1]
P. Günwald and P. Vitányi, “Shannon Information and Kolmogorov Complexity,” arXiv:cs/0410002v1 [cs:IT], 2008.
[2]
M. Sipser, Introduction to the Theory of Computation, Course Technology, 2012.
[3]
C. E. Shannon, “A Mathematical Theory of Communication,” vol. 27, pp. 379-423, 623-656, 1948.
[4]
M. A. Nielsen and I. L. Chuang, Quantum computation and Quantum Information, Cambridge University Press, 2011.
[5]
R. Landauer, «Irreversibility and Heat Generation in Computing Process,» IBM J. Res. Dev., vol. 5, pp. 183-191, 1961.
[6]
J. Sakurai y J. Napolitano, Modern Quantum Mechanics, Cambridge University Press, 2017.
[7]
G. Auletta, Foundations and Interpretation of Quantum Mechanics, World Scientific, 2001.
[8]
A. H. Guth, The Inflationary Universe, Perseus, 1997.
[9]
A. Liddle, An Introduction to Modern Cosmology, Wiley, 2003.
[10]
P. J. E. Peebles and Bharat Ratra, “The cosmological constant and dark energy,” arXiv:astro-ph/0207347, 2003.
[11]
A. Aspect, P. Grangier and G. Roger, “Experimental Tests of Realistic Local Theories via Bell’s Theorem,” Phys. Rev. Lett., vol. 47, pp. 460-463, 1981.
[12]
H. B. G. Casimir and D. Polder, “The Influence of Retardation on the London-van der Waals Forces,” Phys. Rev., vol. 73, no. 4, pp. 360-372, 1948.
There is no doubt that since the origins of geometry humans have been seduced by the number π. Thus, one of its fundamental characteristics is that it determines the relationship between the length of a circumference and its radius. But this does not stop here, since this constant appears systematically in mathematical and scientific models that describe the behavior of nature. In fact, it is so popular that it is the only number that has its own commemorative day. The great fascination around π has raised speculations about the information encoded in its figures and above all has unleashed an endless race for its determination, having calculated several tens of billions of figures to date.
Formally, the classification of real numbers is done according to the rules of calculus. In this way, Cantor showed that real numbers can be classified as countable infinities and uncountable infinities, what are commonly called rational and irrational. Rational numbers are those that can be expressed as a quotient of two whole numbers. While irrational numbers cannot be expressed this way. These in turn are classified as algebraic numbers and transcendent numbers. The former correspond to the non-rational roots of the algebraic equations, that is, the roots of polynomials. On the contrary, transcendent numbers are solutions of transcendent equations, that is, non-polynomial, such as exponential and trigonometric functions.
Georg Cantor. Co-creator of Set Theory
Without going into greater detail, what should catch our attention is that this classification of numbers is based on positional rules, in which each figure has a hierarchical value. But what happens if the numbers are treated as ordered sequences of bits, in which the position is not a value attribute. In this case, the Algorithmic Information Theory (AIT) allows to establish a measure of the information contained in a finite sequence of bits, and in general of any mathematical object, and that therefore is defined in the domain of natural numbers.
What does the AIT tell us?
This measure is based on the concept of Kolmogorov complexity (KC). So that, the Kolmogorov complexity K(x) of a finite object x is defined as the length of the shortest effective binary description of x. Where the term “effective description” connects the Kolmogorov complexity with the Theory of Computation, so that K(x) would correspond to the length of the shortest program that prints x and enters the halt state. To be precise, the formal definition of K(x) is:
K(x) = minp,i{K(i) + l(p):Ti (p) = x } + O(1)
Where Ti(p) is the Turing machine (TM) i that executes p and prints x, l(p) is the length of p, and K(i) is the complexity of Ti. Therefore, object p is a compressed representation of object x, relative to Ti, since x can be retrieved from p by the decoding process defined by Ti, so it is defined as meaningful information. The rest is considered as meaningless, redundant, accidental or noise (meaningless information). The term O(1) indicates that K(i) is a recursive function and in general it is non-computable, although by definition it is machine independent, and whose result has the same order of magnitude in each one of the implementations. In this sense, Gödel’s incompleteness theorems, Turing machine and Kolmogorov complexity lead to the same conclusion about undecidability, revealing the existence of non-computable functions.
KC shows that information can be compressed, but does not establish any general procedure for its implementation, which is only possible for certain sequences. In effect, from the definition of KC it is demonstrated that this is an intrinsic property of bitstreams, in such a way that there are sequences that cannot be compressed. Thus, the number of n-bit sequences that can be encoded by m bits is less than 2m, so the fraction of n-bit sequences with K(x) ≥ n-k is less than 2-k. If the n-bit possible sequences are considered, each one of them will have a probability of occurrence equal to 2-n, so the probability that the complexity of a sequence is K(x) ≥ n-k is equal to or greater than (1-2-k). In short, most bit sequences cannot be compressed beyond their own size, showing a high complexity as they do not present any type of pattern. Applied to the field of physics, this behavior justifies the ergodic hypothesis. As a consequence, this means that most of the problems cannot be solved analytically, since they can only be represented by themselves and as a consequence they cannot be described in a compact way by means of formal rules.
It could be thought that the complexity of a sequence can be reduced at will, by applying a coding criterion that modifies the sequence into a less complex sequence. In general, this only increases the complexity, since in the calculation of K(x) we would have to add the complexity of the coding algorithm that makes it grow as n2. Finally, add that the KC is applicable to any mathematical object, integers, sets, functions, and it is demonstrated that, as the complexity of the mathematical object grows, K(x) is equivalent to the entropy H defined in the context of Information Theory. The advantage of AIT is that it performs a semantic treatment of information, being an axiomatic process, so it does not require having a priori any type of alphabet to perform the measurement of information.
What can be said about the complexity of π?
According to its definition, KC cannot be applied to irrational numbers, since in this case the Turing machine does not reach the halt state, and as we know these numbers have an infinite number of digits. In other words, and to be formally correct, the Turing machine is only defined in the field of natural numbers (it must be noted that their cardinality is the same as that of the rationals), while irrational numbers have a cardinality greater than that of rational numbers. This means that KC and the equivalent entropy H of irrational numbers are undecidable and therefore non-computable.
To overcome this difficulty we can consider an irrational number X as the concatenation of a sequence of bits composed of a rational number x and a residue δx, so that in numerical terms X=x+δx, but in terms of information X={x,δx}. As a consequence, δx is an irrational number δx→0, and therefore δx is a sequence of bits with an undecidable KC and hence non-computable. In this way, it can be expressed:
K(X) = K(x)+K(δx)
The complexity of X can be assimilated to the complexity of x. A priori this approach may seem surprising and inadmissible, since the term K(δx) is neglected when in fact it has an undecidable complexity. But this is similar to the approximation made in the calculation of the entropy of a continuous variable or to the renormalization process used in physics, in order to circumvent the complexity of the underlying processes that remain hidden from observable reality.
Consequently, the sequence p, which runs the Turing machine i to get x, will be composed of the concatenation of:
The sequence of bits that encode the rules of calculus in the Turing machine i.
The bitstream that encodes the compressed expression of x, for example a given numerical series of x.
The length of the sequence x that is to be decoded and that determines when the Turing machine should reach the halt state, for example a googol (10100).
In short, it can be concluded that the complexity K(x) of known irrational numbers, e.g. √2, π, e,…, is limited. For this reason, the challenge must be to obtain the optimum expression of K(x) and not the figures that encode these numbers, since according to what has been said, their uncompressed expression, or the development of their figures, has a high degree of redundancy (meaningless information).
What in theory is a surprising and questionable fact is in practice an irrefutable fact, since the complexity of δx will always remain hidden, since it is undecidable and therefore non-computable.
Another important conclusion is that it provides a criterion for classifying irrational numbers into two groups: representable and non-representable. The former correspond to irrational numbers that can be represented by mathematical expressions, which would be the compressed expression of these numbers. While non-representable numbers would correspond to irrational numbers that could only be expressed by themselves and are therefore undecidable. In short, the cardinality of representable irrational numbers is that of natural numbers. It should be noted that the previous classification criterion is applicable to any mathematical object.
On the other hand, it is evident that mathematics, and calculus in particular, de facto accepts the criteria established to define the complexity K(x). This may go unnoticed because, traditionally in this context, numbers are analyzed from the perspective of positional coding, in such a way that the non-representable residue is filtered out through the concept of limit, in such a way that δx→0. However, when it comes to evaluating the informative complexity of a mathematical object, it may be required to apply a renormalization procedure.
From the analysis carried out in the previous post, it can be concluded that, in general, it is not possible to identify the macroscopic states of a complex system with its quantum states. Thus, the macroscopic states corresponding to the dead cat (DC) or to the living cat (AC) cannot be considered quantum states, since according to quantum theory the system could be expressed as a superposition of these states. Consequently, as it has been justified, for macroscopic systems it is not possible to define quantum states such as |DC⟩ and |DC⟩. On the other hand, the states (DC) and (AC) are an observable reality, indicating that the system presents two realities, a quantum reality and an emerging reality that can be defined as classical reality.
Quantum reality will be defined by its wave function, formed by the superposition of the quantum subsystems that make up the system and which will evolve according to the existing interaction between all the quantum elements that make up the system and the environment. For simplicity, if the CAT system is considered isolated from the environment, the succession of its quantum state can be expressed as:
Expression in which it has been taken into account
that the number of non-entangled quantum subsystems k also varies with time, so
it is a function of the sequence n, considering time as a discrete
variable.
The observable classical reality can be described by the state of the system that, if for the object “cat” is defined as (CAT[n]), from the previous reasoning it is concluded that (CAT[n]) ≢ |CAT[n]⟩. In other words, the quantum and classical states of a complex object are not equivalent.
The question that remains to be justified is the irreducibility of the observable classical state (CAT) from the underlying quantum reality, represented by the quantum state |CAT⟩. This can be done if it is considered that the functional relationship between states |CAT⟩ and (CAT) is extraordinarily complex, being subject to the mathematical concepts on which complex systems are based, such as they are:
The complexity of the space of quantum states (Hilbert space).
The random behavior of observable information emerging from quantum reality.
The enormous number of quantum entities involved in a macroscopic system.
The non-linearity of the laws of classical physics.
Based on Kolmogorov complexity [1], it is possible to prove that the behavior of systems with these characteristics does not support, in most cases, an analytical solution that determines the evolution of the system from its initial state. This also implies that, in practice, the process of evolution of a complex object can only be represented by itself, both on a quantum and a classical level.
According to the algorithmic information theory [1], this process is equivalent to a mathematical object composed of an ordered set of bits processed according to axiomatic rules. In such a way that the information of the object is defined by the Kolmogorov complexity, in a manner that it remains constant throughout time, as long as the process is an isolated system. It should be pointed out that the Kolmogorov complexity makes it possible to determine the information contained in an object, without previously having an alphabet for the determination of its entropy, as is the case in the information theory [2], although both concepts coincide at the limit.
From this point of view, two fundamental questions
arise. The first is the evolution of the entropy of the system and the second
is the apparent loss of information in the observation process, through which
classical reality emerges from quantum reality. This opens a possible line of
analysis that will be addressed later.
But going back to the analysis of what is the relationship between classic and quantum states, it is possible to have an intuitive view of how the state (CAT) ends up being disconnected from the state |CAT⟩, analyzing the system qualitatively.
First, it should be noted that virtually 100% of the quantum information contained in the state |CAT⟩ remains hidden within the elementary particles that make up the system. This is a consequence of the fact that the physical-chemical structure [3] of the molecules is determined exclusively by the electrons that support its covalent bonds. Next, it must be considered that the molecular interaction, on which molecular biology is based, is performed by van der Waals forces and hydrogen bonds, creating a new level of functional disconnection with the underlying layer.
Supported by this functional level appears a new functional structure formed by cellular biology [4], from which appear living organisms, from unicellular beings to complex beings formed by multicellular organs. It is in this layer that the concept of living being emerges, establishing a new border between the strictly physical and the concept of perception. At this level the nervous tissue [5] emerges, allowing the complex interaction between individuals and on which new structures and concepts are sustained, such as consciousness, culture, social organization, which are not only reserved to human beings, although it is in the latter where the functionality is more complex.
But to the complexity of the functional layers must be
added the non-linearity of the laws to which they are subject and which are necessary and sufficient conditions for a behavior of deterministic chaos [6] and which, as previously justified, is based on the algorithmic information theory [1]. This means that any variation in the initial conditions will produce a different dynamic, so that any emulation will end up diverging from the original, this behavior being the justification of free will. In this sense, Heisenberg’s uncertainty principle [7] prevents from knowing exactly the initial conditions of the classical system, in any of the functional layers described above. Consequently, all of them will have an irreducible nature and an unpredictable dynamic, determined exclusively by the system itself.
At this point and in view of this complex functional structure, we must ask what the state (CAT) refers to, since in this context the existence of a classical state has been implicitly assumed. The complex functional structure of the object “cat” allows a description at different levels. Thus, the cat object can be described in different ways:
As atoms and molecules subject to the laws of physical chemistry.
As molecules that interact according to molecular biology.
As complex sets of molecules that give rise to cell biology.
As sets of cells to form organs and living organisms.
As structures of information processing, that give rise to the mechanisms of perception and interaction with the environment that allow the development of individual and social behavior.
As a result, each of these functional layers can be expressed by means of a certain state. So to speak of, the definition of a unique macroscopic state (CAT) is not correct. Each of these states will describe the object according to different functional rules, so it is worth asking what relationship exists between these descriptions and what their complexity is. Analogous to the arguments used to demonstrate that the states |CAT⟩ and (CAT) are not equivalent and are uncorrelated with each other, the states that describe the “cat” object at different functional levels will not be equivalent and may to some extent be disconnected from each other.
This behavior is a proof of how reality is structured in irreducible functional layers, in such a way that each one of the layers can be modeled independently and irreducibly, by means of an ordered set of bits processed according to axiomatic rules.
Refereces
[1]
P. Günwald and P. Vitányi, “Shannon Information and Kolmogorov Complexity,” arXiv:cs/0410002v1 [cs:IT], 2008.
[2]
C. E. Shannon, «A Mathematical Theory of Communication,» The Bell System Technical Journal, vol. 27, pp. 379-423, 1948.
[3]
P. Atkins and J. de Paula, Physical Chemestry, Oxford University Press, 2006.
[4]
A. Bray, J. Hopkin, R. Lewis and W. Roberts, Essential Cell Biology, Garlan Science, 2014.
[5]
D. Purves and G. J. Augustine, Neuroscience, Oxford Univesisty press, 2018.
[6]
J. Gleick, Chaos: Making a New Science, Penguin Books, 1988.
[7]
W. Heisenberg, «The Actual Content of Quantum Theoretical Kinematics and Mechanics,» Zeit-schrift fur Physik. Translation: NASA TM-77379., vol. 43, nº 3-4, pp. 172-198, 1927.
If we stick to its definition, which can be found in dictionaries, we can see that it always refers to a set of data and often adds the fact that these are sorted and processed. But we are going to see that these definitions are imprecise and even erroneous in assimilating it to the concept of knowledge.
One of the things that information theory has taught us is that any object (news, profile, image, etc.) can be expressed precisely by a set of bits. Therefore, the formal definition of information is the ordered set of symbols that represent the object and that in their basic form constitute an ordered set of bits. However, information theory itself surprisingly reveals that information has no meaning, which is technically known as “information without meaning”.
This seems to be totally contradictory, especially if we take into account the conventional idea of what is considered as information. However, this is easy to understand. Let us imagine that we find a book in which symbols appear written that are totally unknown to us. We will immediately assume that it is a text written in a language unknown to us, since, in our culture, book-shaped objects are what they usually contain. Thus, we begin to investigate and conclude that it is an unknown language without reference or Rosetta stone with any known language. Therefore, we have information but we do not know its message and as a result, the knowledge contained in the text. We can even classify the symbols that appear in the text and assign them a binary code, as we do in the digitization processes, converting the text into an ordered set of bits.
However, to know the content of the message we must analyze the information through a process that must include the keys that allow extracting the content of the message. It is exactly the same as if the message were encrypted, so the message will remain hidden if the decryption key is not available, as shown by the one-time pad encryption technique.
Ray Solomonoff, co-founder of Algorithmic Information Theory together with Andrey Kolmogorov.
What is knowledge?
This clearly shows the difference between information and knowledge. In such a way that information is the set of data (bits) that describe an object and knowledge is the result of a process applied to this information and that is materialized in reality. In fact, reality is always subject to this scheme.
For example, suppose we are told a certain story. From the sound pressure applied to our eardrums we will end up extracting the content of the news and also we will be able to experience subjective sensations, such as pleasure or sadness. There is no doubt that the original stimulus can be represented as a set of bits, considering that audio information can be a digital content, e.g. MP3.
But for knowledge to emerge, information needs to be processed. In fact, in the previous case it is necessary to involve several different processes, among which we must highlight:
Biological processes responsible for the transduction of information into nerve stimuli.
Extraction processes of linguistic information, established by the rules of language in our brain by learning.
Extraction processes of subjective information, established by cultural rules in our brain by learning.
In short, knowledge is established by means of information processing. And here the debate may arise as a consequence of the diversity of processes, of their structuring, but above all because of the nature of the ultimate source from which they emerge. Countless examples can be given. But, since doubts can surely arise that this is the way reality emerges, we can try to look for a single counterexample!
A fundamental question is: Can we measure knowledge? The answer is yes and is provided by the algorithmic information theory (AIT) which, based on information theory and computer theory, allows us to establish the complexity of an object, by means of the Kolmogorov complexity K(x), which is defined as follows:
For a finite object x, K(x) is defined as the length of the shortest effective binary description of x.
Without going into complex theoretical details, it is important to mention that K(x) is an intrinsic property of the object and not a property of the evaluation process. But don’t panic! Since, in practice, we are familiar with this idea.
Let’s imagine audio, video, or general bitstream content. We know that these can be compressed, which significantly reduces their size. This means that the complexity of these objects is not determined by the number of bits of the original sequence, but by the result of the compression since through an inverse decompression process we can recover the original content. But be careful! The effective description of the object must include the result of the compression process and the description of the decompression process, needed to retrieve the message.
Complexity of digital content, equivalent to a compression process
A similar scenario is the modeling of reality, where physical processes stand out. Thus, a model is a compact definition of a reality. For example, Newton’s universal gravitation model is the most compact definition of the behavior of a gravitational system in a non-relativistic context. In this way, the model, together with the rules of calculus and the information that defines the physical scenario, will be the most compact description of the system and constitutes what we call algorithm. It is interesting to note that this is the formal definition of algorithm and that until these mathematical concepts were developed in the first half of the 20th century by Klein, Chruch and Turing, this concept was not fully established.
Alan Turing, one of the fathers of computing
It must be considered that the physical machine that supports the process is also part of the description of the object, providing the basic functions. These are axiomatically defined and in the case of the Turing machine correspond to an extremely small number of axiomatic rules.
Structure of the models, equivalent to a decompression process
In summary, we can say that knowledge is the result of information processing. Therefore, information processing is the source of reality. But this raises the question: Since there are non-computable problems, to what depth is it possible to explore reality?