The replication mechanisms of living beings can be compared with the self-replication of automatons in the context of computability theory. In particular, DNA replication, analyzed from the perspective of the recursion theorem, indicates that its replication structure goes beyond biology and the quantum mechanisms that support it, as it is analyzed in the article Biology as an Axiomatic Process.
Physical chemistry establishes the principles by which atoms interact with each other to form molecules. In the inorganic world the resulting molecules are relatively simple, not allowing establishing a complex functional structure. On the other hand, in the organic world, molecules can be made up of thousands or even millions of atoms and have complex functionality. It highlights what is known as molecular recognition, through which the molecules interact with each other selectively and which is the basis of biology.
Molecular recognition plays a fundamental role in the structure of DNA, in the translation of the genetic code of DNA into proteins and in the biochemical interaction of proteins, which ultimately form the basis on which living beings are based.
The detailed study of these molecular interactions makes it possible to describe the functionality of the processes, in such a way that it is possible to establish formal models, to such an extent that they can be used as a computing technology, as is the case of DNA-based computing.
From this perspective, this allows us to ask if the process of information is something deeper and if in reality it is the foundation of biology itself, according to what is established by the principle of reality.
For this purpose, this section aims to analyze the basic processes on which biology is based, in order to establish a link with axiomatic processing and thus investigate the nature of biological processes. For this, it is not necessary to describe in detail the biological mechanisms described in the literature. We will simply describe its functionality, so that they can be identified with the theoretical foundations of information processing. To this end, we will explain the mechanisms on which DNA replication and protein synthesis are based.
DNA and RNA molecules are polymers formed from the ribose and deoxyribose nucleotides, respectively, bound by phosphates. On the basis of this nucleotide chain, one of the four possible nucleic acids can be linked. There are five different nucleic acids, adenine (A), guanine (G), cytosine (C), thymine (T) and uracil (U). In the case of DNA, nucleic acids that can be coupled by covalent bonds to nucleotides are A, G, C and T, whereas in the case of RNA they are A, G, C and U. As a consequence, molecules are structured in a helix shape, fitting the nucleic acids in a precise and compact way, due to the shape of their electronic clouds.
The helix structure allows the nucleic acids of two different strands to be bound together by hydrogen bonds, forming pairs A-T and G-C in the case of DNA, and A-U and G-C in the case of RNA, as shown in the following figure.
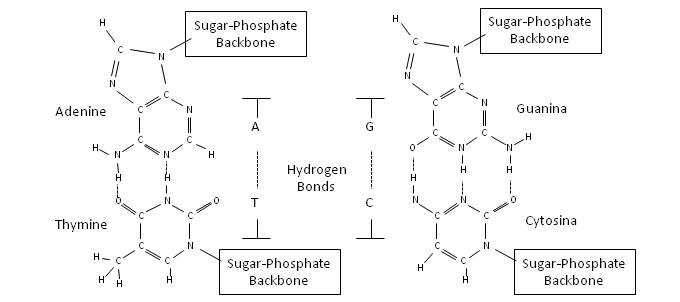
Base-pairing of nucleic acids in DNA
As a result, the DNA molecule is formed by a double helix, in which two chains of nucleotides polymers wind one on top of the other, remaining together by means of hydrogen bonds of nucleic acids. Thus, each strand of the DNA molecule contains the same genetic code, one of which can be considered the negative of the other.
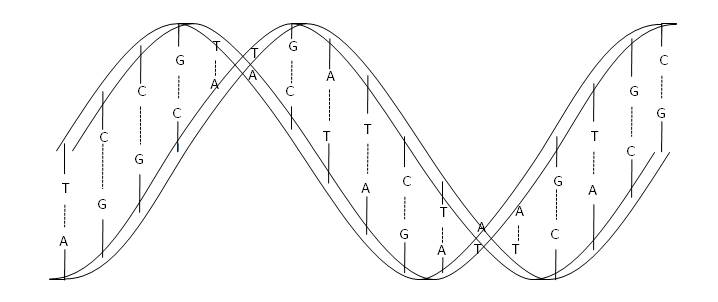
Double helix structure of DNA molecule
The genetic information of an organism, called a genome, is not contained in a single DNA molecule, but is organized into chromosomes. These are made up of DNA strands bound together by proteins. Thus, in the case of humans, the genome is formed by 46 chromosomes, and so, the number of bases in the DNA molecules that compose it being about 3×109. Since each base can be encoded by means of 2 bits, the human genome, considered as an object of information, is equivalent to 6×109 bits.
The information contained in the genes is the basis for the synthesis of proteins, which are responsible for executing and controlling the biochemistry of living beings. The proteins are formed by the bonding of amino acids, through covalent bonds, which is done from the sequences of the bases contained in the DNA. The number of existing amino acids is 20 and since each base codes 2 bits, 3 bases (6 bits, 64 combinations) are necessary to be able to code each one of the amino acids. This means that there is some redundancy in the assignment of base sequences to amino acids, in addition to control codes for the synthesis process (Stop), as shown in the following table.
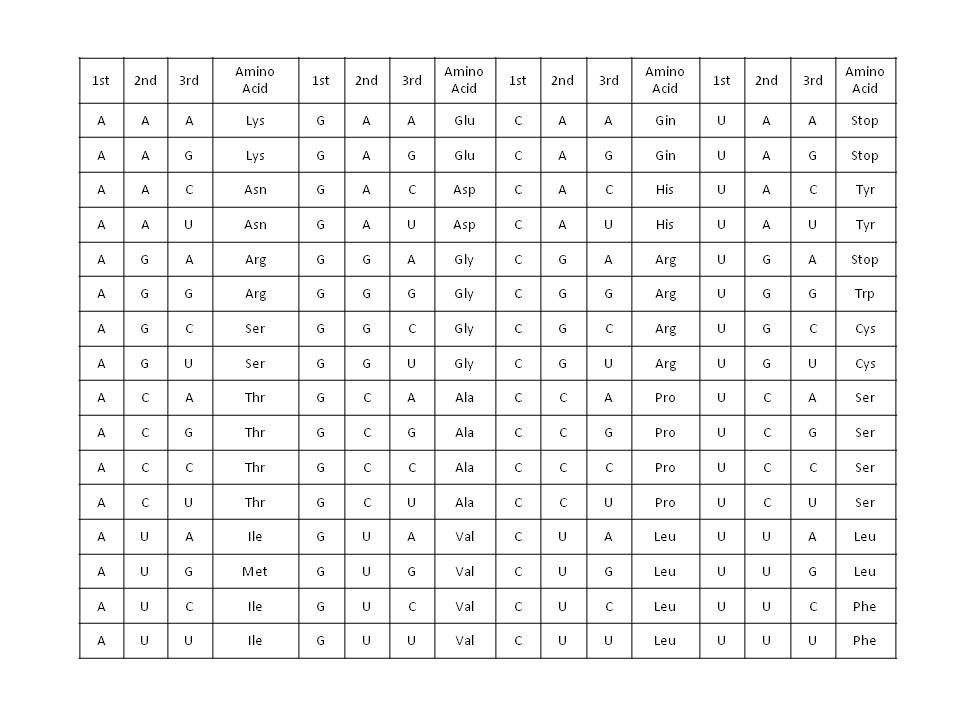
Translation of nucleic acids (Codons) to amino acids
However, protein synthesis is not done directly from DNA, since it requires the intermediation of RNA. This is called the translation process and involves two types of different RNA molecules, the messenger ARM (mRNA) and the transfer RNA (tRNA). The first step is the synthesis of mRNA from DNA. This process is called transcription, in such a way that the information corresponding to a gene is copied into the mRNA molecule, which is done through a process of recognition between the molecules of the nucleic acids, carried out by the hydrogen bonds, such as shows the following figure.
![]()
DNA transcription
Once the mRNA molecule is synthesized, the tRNA molecule is responsible for mediating between mRNA and amino acids to synthesize proteins, for which it has two specific molecular mechanisms. On the one hand, tRNA has a chain of three amino acids called anticodon at one end. On the opposite side, tRNA binds to a specific amino acid, according to the translation table of nucleic acid sequences into amino acids. In this way, tRNA is able to translate mRNA into a protein, as shown in the figure below.
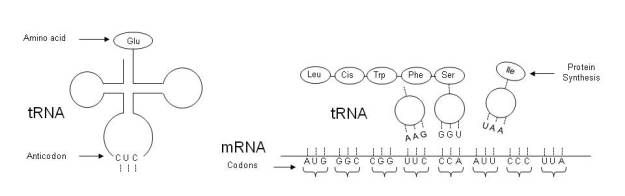
Protein synthesis (mRNA translation)
But perhaps the most complex process is undoubtedly DNA replication, so that each molecule produces two identical replicas. Replication is performed by unwinding each strand of the molecule and inserting the nucleic acid molecules on each of the strands, in a similar way to that shown in the mRNA synthesis. DNA replication is controlled by enzymatic processes supported by proteins. Without going into detail and in order to show its complexity, the table below shows the proteins involved in the replication process and their role.

The role of proteins in the DNA replication process
The processes described above are defined as the central dogma of molecular biology and are usually schematically represented schematically as shown in the following figure. It also depicts the reverse transcription that occurs in retroviruses, which synthesizes a DNA molecule from RNA.
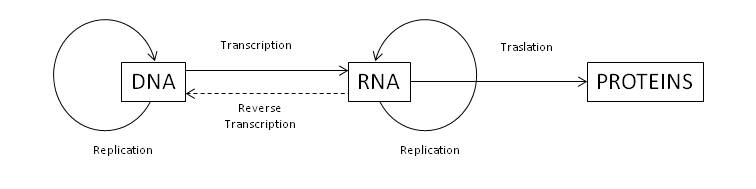
Central dogma of molecular biology
The biological process from the perspective of computability theory
Molecular processes supported by DNA, RNA and proteins can be considered from an abstract point of view as information processes. As a result, input statements corresponding to a language are processed resulting in new output statements. Thus, the following languages can be identified:
- DNA molecule. Sentence consisting of a sequence of characters corresponding to a 4-symbol alphabet.
- RNA molecule – protein synthesis. Sentence consisting of a sequence of characters belonging to a 21-symbol alphabet.
- RNA molecule-reverse transcription. Sentence composed of a sequence of characters belonging to a 4-symbol alphabet.
- Protein molecule. Sentence composed of a sequence of characters belonging to a 20-symbol alphabet.
This information is processed by the machinery established by the physicochemical properties of control molecules. To better understand this functional structure, it is advisable to modify the scheme corresponding to the central dogma of biology. To do this, we must represent the processes involved and the information that flows between them, as shown in the following block diagram.
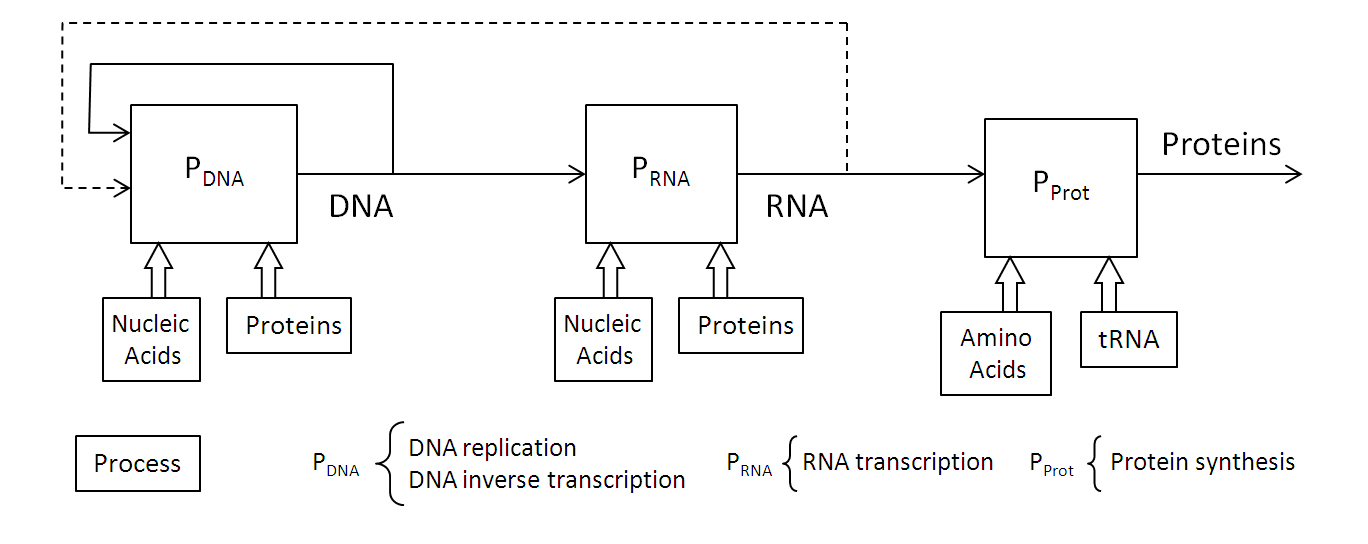
Functional structure of DNA replication
This structure highlights the flow of information between processes, such as DNA and RNA sentences, where the functional blocks of information processing are the following:
- PDNA. Replication process. The functionality of this process is determined by the proteins involved in DNA synthesis, producing two replicas of DNA from a single molecule.
- PRNA. Transcription process. It synthesizes a RNA molecule from a gene encoded in DNA.
- PProt. Translation process. It synthesizes a protein from an RNA molecule.
This structure clearly shows how information emerges from biological processes, something that seems to be ubiquitous in all natural models and allows the implementation of computer systems. In all cases this capacity is finally supported by quantum physics. In the case of biology in particular, this is produced from the physicochemical properties of molecules, which are determined by quantum physics. Therefore, the information process is something that emerges from an underlying reality and ultimately from quantum physics. This is true as far as knowledge goes.
This means that, although there is a strong link between reality and information, information is simply an emerging product of reality. But biology provides a clue to the intimate relationship between reality and information, which are ultimately indistinguishable concepts. If we look at the DNA replication process, we see that DNA is produced in several stages of processing:
DNA → RNA → Proteins → DNA.
We could consider this to be a specific feature of the biological process. However, computability theory indicates that the replication process is subject to deeper logical rules than the physical processes themselves that support replication. In computability theory, the recursion theorem determines that replication of information requires at least the intervention of two independent processes.
This shows that DNA replication is subject to abstract rules that must be satisfied not only by biology, but by every natural process. Therefore, the physical foundations that support biological processes must verify this requirement. Consequently, this shows that the information processing is essential in what we understand by reality.

Pingback: The unreasonable effectiveness of mathematics | Information and Reality