Note: This post is the first in a series in which macroscopic objects will be analyzed from a quantum and classical point of view, as well as the nature of the observation. Finally, all of them will be integrated into a single article.
Introduction
Quantum theory establishes the fundamentals of the behavior of particles and their interaction with each other. In general, these fundamentals apply to microscopic systems formed by a very limited number of particles. However, nothing indicates that the application of quantum theory cannot be applied to macroscopic objects, since the emerging properties of such objects must be based on the underlying quantum reality. Obviously, there is a practical limitation established by the increase in complexity, which grows exponentially as the number of elementary particles increases.
The initial reference to this approach was made by Schrödinger [1], indicating that the quantum superposition of states did not represent any contradiction at the macroscopic level. To do this, he used what is known as Schrödinger’s cat paradox in which the cat could be in a superposition of states, one in which the cat was alive and another in which the cat was dead. Schrödinger’s original motivation was to raise a discussion about the EPR paradox [2], which revealed the incompleteness of quantum theory. This has finally been solved by Bell’s theorem [3] and its experimental verification by Aspect [4], making it clear that the entanglement of quantum particles is a reality on which quantum computation is based [5]. A summary of the aspects related to the realization of a quantum system that emulates Schrödinger cat has been made by Auletta [6], although these are restricted to non-macroscopic quantum systems.
But the question that remains is whether quantum theory can be used to describe macroscopic objects and whether the concept of quantum entanglement applies to these objects as well. Contrary to Schrödinger’s position, Wigner argued, through the friend paradox, that quantum mechanics could not have unlimited validity [7]. Recently, Frauchiger and Renner [8] have proposed a virtual experiment (Gedankenexperiment) that shows that quantum mechanics is not consistent when applied to complex objects.
The Schrödinger cat paradigm will be used to analyze these results from two points of view, with no loss of generality, one as a quantum object and the other as a macroscopic object (in a next post). This will allow their consistency and functional relationship to be determined, leading to the establishment of an irreducible functional structure. As a consequence of this, it will also be necessary to analyze the nature of the observer within this functional structure (also in a later posts).
Schrödinger’s cat as a quantum reality
In the Schrödinger cat experiment there are several entities [1], the radioactive particle, the radiation monitor, the poison flask and the cat. For simplicity, the experiment can be reduced to two quantum variables: the cat, which we will identify as CAT, and the system formed by the radioactive particle, the radiation monitor and the poison flask, which we will define as the poison system PS.
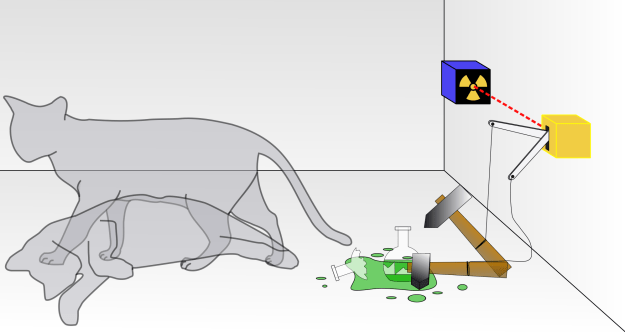
Schrödinger Cat. (Source: Doug Hatfield https://commons.wikimedia.org/wiki/File:Schrodingers_cat.svg)
These quantum variables can be expressed as [9]:
|CAT⟩ = α1|DC⟩ + β1|LC⟩. Quantum state of the cat: dead cat |DC⟩, live cat |LC⟩.
|PS⟩ = α2|PD⟩ + β2|PA⟩. Quantum state of the poison system: poison deactivated |PD⟩, poison activated |PA⟩.
The quantum state of the Schrödinger cat experiment SCE as a whole can be expressed as:
|SCE⟩ = |CAT⟩⊗|PS⟩= α1α2|DC⟩|PD⟩+α1β2|DC⟩|PA⟩+β1α2|LC⟩|PD⟩+β1β2|LC⟩|PA⟩.
Since for a classical observer the final result of the experiment requires that the states |DC⟩|PD⟩ and |LC⟩|PA⟩ are not compatible with observations, the experiment must be prepared in such a way that the quantum states |CAT⟩ and |PS⟩ are entangled [10] [11], so that the wave function of the experiment must be:
|SCE⟩ = α|DC⟩|PA⟩ + β|LC⟩|PD⟩.
As a consequence, the observation of the experiment [12] will result in a state:
|SCE⟩ = |DC⟩|PA⟩, with probability α2, (poison activated, dead cat).
or:
|SCE⟩ =|LC⟩|PD⟩, with probability β2, (poison deactivated, live cat).
Although from the formal point of view of quantum theory the approach of the experiment is correct, for a classical observer the experiment presents several objections. One of these is related to the fact that the experiment requires establishing “a priori” the requirement that the PS and CAT systems are entangled. Something contradictory, since from the point of view of the preparation of the quantum experiment there is no restriction, being able to exist results with quantum states |DC⟩|PD⟩, or |LC⟩|PA⟩, something totally impossible for a classical observer, assuming in any case that the poison is effective, that it is taken for granted in the experiment. Therefore, the SCE experiment is inconsistent, so it is necessary to analyze the root of the incongruence between the SCE quantum system and the result of the observation.
Another objection, which may seem trivial, is that for the SCE experiment to collapse in one of its states the OBS observer must be entangled with the experiment, since the experiment must interact with it. Otherwise, the operation performed by the observer would have no consequence on the experiment. For this reason, this aspect will require more detailed analysis.
Returning to the first objection, from the perspective of quantum theory it may seem possible to prepare the PS and CAT systems in an entangled superposition of states. However, it should be noted that both systems are composed of a huge number of non-entangled quantum subsystems Si subject to continuous decoherence [13] [14]. It should be noted that the Si subsystems will internally have an entangled structure. Thus, the CAT and PS systems can be expressed as:
|CAT⟩ = |SC1⟩ ⊗ |SC2⟩ ⊗…⊗ |SCi⟩ ⊗…⊗ |SCk⟩,
|PS⟩= |SP1⟩⊗|SP2⟩⊗…⊗|SPi⟩⊗…⊗|SPl⟩,
in such a way that the observation of a certain subsystem causes its state to collapse, producing no influence on the rest of the subsystems, which will develop an independent quantum dynamics. This makes it unfeasible that the states |LC⟩ and |DC⟩ can be simultaneous and as a consequence the CAT system cannot be in a superposition of these states. An analogous reasoning can be made of the PS system, although it imay seem obvious that functionally it is much simpler.
In short, from a theoretical point of view it is possible to have a quantum system equivalent to the SCE, for which all the subsystems must be fully entangled with each other, and in addition the system will require an “a priori” preparation of its state. However, the emerging reality differs radically from this scenario, so that the experiment seems to be unfeasible in practice. But the most striking fact is that, if the SCE experiment is generalized, the observable reality would be radically different from the observed reality.
To better understand the consequences of the quantum state of the ECS system having to be prepared “a priori”, imagine that the supplier of the poison has changed its contents to a harmless liquid. As a result of this, the experiment will be able to kill the cat without cause.
From these conclusions the question can be raised as to whether quantum theory can explain in a general and consistent way the observable reality at the macroscopic level. But perhaps the question is also whether the assumptions on which the SCE experiment has been conducted are correct. Thus, for example: Is it correct to use the concepts of live cat or dead cat in the domain of quantum physics? Which in turn raises other kinds of questions, such as: Is it generally correct to establish a strong link between observable reality and the underlying quantum reality?
The conclusion that can be drawn from the contradictions of the SCE experiment is that the scenario of a complex quantum system cannot be treated in the same terms as a simple system. In terms of quantum computation these correspond, respectively, to systems made up of an enormous number and a limited number of qubits [5]. As a consequence of this, classical reality will be an irreducible fact, which based on quantum reality ends up being disconnected from it. This leads to defining reality in two independent and irreducible functional layers, a quantum reality layer and a classical reality layer. This would justify the criterion established by the Copenhagen interpretation [15] and its statistical nature as a means of functionally disconnecting both realities. Thus, quantum theory would be nothing more than a description of the information that can emerge from an underlying reality, but not a description of that reality. At this point, it is important to emphasize that statistical behavior is the means by which the functional correlation between processes can be reduced or eliminated [16] and that it would be the cause of irreducibility.
References
| [1] | E. Schrödinger, «Die gegenwärtige Situation in der Quantenmechanik,» Naturwissenschaften, vol. 23, pp. 844-849, 1935. |
| [2] | A. Einstein, B. Podolsky and N. Rose, “Can Quantum-Mechanical description of Physical Reality be Considered Complete?,” Physical Review, vol. 47, pp. 777-780, 1935. |
| [3] | J. S. Bell, «On the Einstein Podolsky Rosen Paradox,» Physics,vol. 1, nº 3, pp. 195-290, 1964. |
| [4] | A. Aspect, P. Grangier and G. Roger, “Experimental Tests of Realistic Local Theories via Bell’s Theorem,” Phys. Rev. Lett., vol. 47, pp. 460-463, 1981. |
| [5] | M. A. Nielsen and I. L. Chuang, Quantum computation and Quantum Information, Cambridge University Press, 2011. |
| [6] | G. Auletta, Foundations and Interpretation of Quantum Mechanics, World Scientific, 2001. |
| [7] | E. P. Wigner, «Remarks on the mind–body question,» in Symmetries and Reflections, Indiana University Press, 1967, pp. 171-184. |
| [8] | D. Frauchiger and R. Renner, “Quantum Theory Cannot Consistently Describe the Use of Itself,” Nature Commun., vol. 9, no. 3711, 2018. |
| [9] | P. Dirac, The Principles of Quantum Mechanics, Oxford University Press, 1958. |
| [10] | E. Schrödinger, «Discussion of Probability Relations between Separated Systems,» Mathematical Proceedings of the Cambridge Philosophical Society, vol. 31, nº 4, pp. 555-563, 1935. |
| [11] | E. Schrödinger, «Probability Relations between Separated Systems,» Mathematical Proceedings of the Cambridge Philosophical Society, vol. 32, nº 3, pp. 446-452, 1936. |
| [12] | M. Born, «On the quantum mechanics of collision processes.,» Zeit. Phys.(D. H. Delphenich translation), vol. 37, pp. 863-867, 1926. |
| [13] | H. D. Zeh, «On the Interpretation of Measurement in Quantum Theory,» Found. Phys., vol. 1, nº 1, pp. 69-76, 1970. |
| [14] | W. H. Zurek, «Decoherence, einselection, and the quantum origins of the classical,» Rev. Mod. Phys., vol. 75, nº 3, pp. 715-775, 2003. |
| [15] | W. Heisenberg, Physics and Philosophy. The revolution in Modern Science, Harper, 1958. |
| [16] | E. W. Weisstein, «MathWorld,» [En línea]. Available http://mathworld.wolfram.com/Covariance.html. |




{kind=link}